 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Federated Survival Analysis through Peer-Driven Client Reputation in Healthcare
May 22, 2025Federated Learning (FL) holds great promise for digital health by enabling collaborative model training without compromising patient data privacy. However, heterogeneity across institutions, lack of sustained reputation, and unreliable contributions remain major challenges. In this paper, we propose a robust, peer-driven reputation mechanism for federated healthcare that employs a hybrid communication model to integrate decentralized peer feedback with clustering-based noise handling to enhance model aggregation. Crucially, our approach decouples the federated aggregation and reputation mechanisms by applying differential privacy to client-side model updates before sharing them for peer evaluation. This ensures sensitive information remains protected during reputation computation, while unaltered updates are sent to the server for global model training. Using the Cox Proportional Hazards model for survival analysis across multiple federated nodes, our framework addresses both data heterogeneity and reputation deficit by dynamically adjusting trust scores based on local performance improvements measured via the concordance index. Experimental evaluations on both synthetic datasets and the SEER dataset demonstrate that our method consistently achieves high and stable C-index values, effectively down-weighing noisy client updates and outperforming FL methods that lack a reputation system.
Addressing Data Heterogeneity in Federated Learning of Cox Proportional Hazards Models
Jul 20, 2024
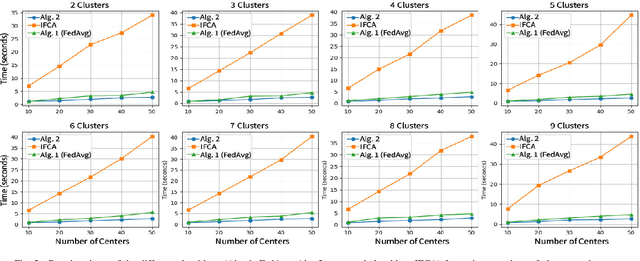
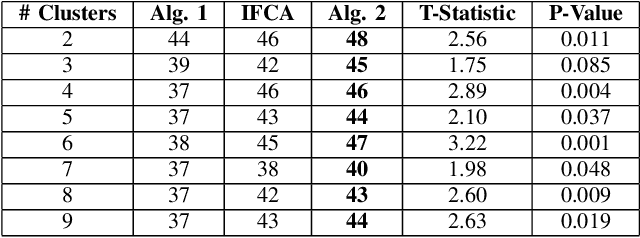
The diversity in disease profiles and therapeutic approaches between hospitals and health professionals underscores the need for patient-centric personalized strategies in healthcare. Alongside this, similarities in disease progression across patients can be utilized to improve prediction models in survival analysis. The need for patient privacy and the utility of prediction models can be simultaneously addressed in the framework of Federated Learning (FL). This paper outlines an approach in the domain of federated survival analysis, specifically the Cox Proportional Hazards (CoxPH) model, with a specific focus on mitigating data heterogeneity and elevating model performance. We present an FL approach that employs feature-based clustering to enhance model accuracy across synthetic datasets and real-world applications, including the Surveillance, Epidemiology, and End Results (SEER) database. Furthermore, we consider an event-based reporting strategy that provides a dynamic approach to model adaptation by responding to local data changes. Our experiments show the efficacy of our approach and discuss future directions for a practical application of FL in healthcare.
A Review of Link Prediction Applications in Network Biology
Dec 03, 2023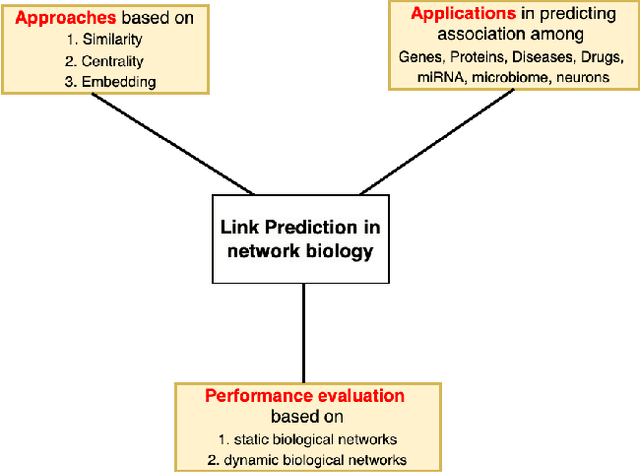


In the domain of network biology, the interactions among heterogeneous genomic and molecular entities are represented through networks. Link prediction (LP) methodologies are instrumental in inferring missing or prospective associations within these biological networks. In this review, we systematically dissect the attributes of local, centrality, and embedding-based LP approaches, applied to static and dynamic biological networks. We undertake an examination of the current applications of LP metrics for predicting links between diseases, genes, proteins, RNA, microbiomes, drugs, and neurons. We carry out comprehensive performance evaluations on established biological network datasets to show the practical applications of standard LP models. Moreover, we compare the similarity in prediction trends among the models and the specific network attributes that contribute to effective link prediction, before underscoring the role of LP in addressing the formidable challenges prevalent in biological systems, ranging from noise, bias, and data sparseness to interpretability. We conclude the review with an exploration of the essential characteristics expected from future LP models, poised to advance our comprehension of the intricate interactions governing biological systems.
Use of Artificial Intelligence to Analyse Risk in Legal Documents for a Better Decision Support
Nov 22, 2019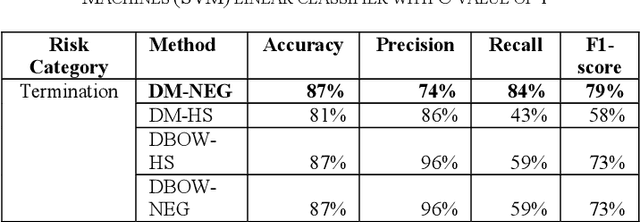
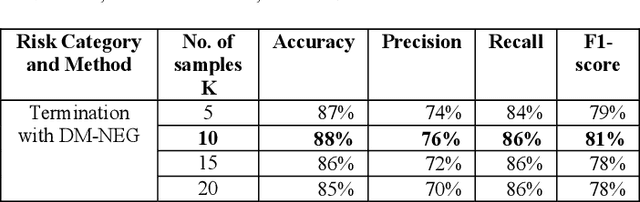
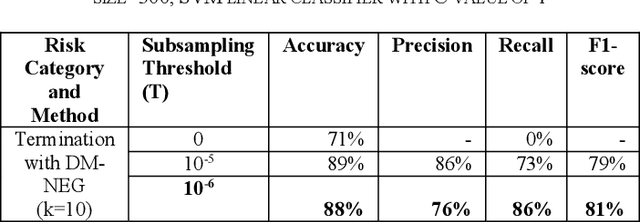

Assessing risk for voluminous legal documents such as request for proposal; contracts is tedious and error prone. We have developed "risk-o-meter", a framework, based on machine learning and natural language processing to review and assess risks of any legal document. Our framework uses Paragraph Vector, an unsupervised model to generate vector representation of text. This enables the framework to learn contextual relations of legal terms and generate sensible context aware embedding. The framework then feeds the vector space into a supervised classification algorithm to predict whether a paragraph belongs to a per-defined risk category or not. The framework thus extracts risk prone paragraphs. This technique efficiently overcomes the limitations of keyword-based search. We have achieved an accuracy of 91% for the risk category having the largest training dataset. This framework will help organizations optimize effort to identify risk from large document base with minimal human intervention and thus will help to have risk mitigated sustainable growth. Its machine learning capability makes it scalable to uncover relevant information from any type of document apart from legal documents, provided the library is per-populated and rich.