 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of Artificial Intelligence to Analyse Risk in Legal Documents for a Better Decision Support
Paper and Code
Nov 22, 2019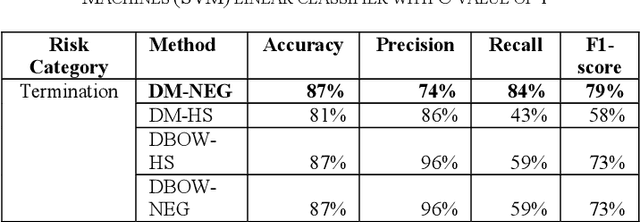
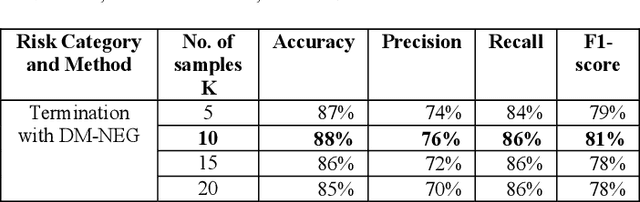
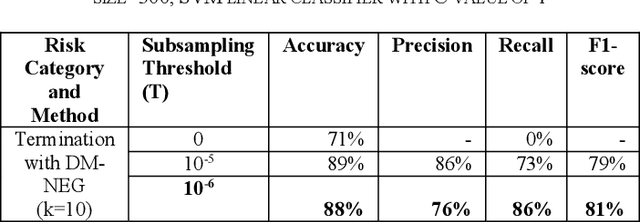

Assessing risk for voluminous legal documents such as request for proposal; contracts is tedious and error prone. We have developed "risk-o-meter", a framework, based on machine learning and natural language processing to review and assess risks of any legal document. Our framework uses Paragraph Vector, an unsupervised model to generate vector representation of text. This enables the framework to learn contextual relations of legal terms and generate sensible context aware embedding. The framework then feeds the vector space into a supervised classification algorithm to predict whether a paragraph belongs to a per-defined risk category or not. The framework thus extracts risk prone paragraphs. This technique efficiently overcomes the limitations of keyword-based search. We have achieved an accuracy of 91% for the risk category having the largest training dataset. This framework will help organizations optimize effort to identify risk from large document base with minimal human intervention and thus will help to have risk mitigated sustainable growth. Its machine learning capability makes it scalable to uncover relevant information from any type of document apart from legal documents, provided the library is per-populated and rich.