 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Transfer Learning and pre-trained Models for Effective Forest Fire Detection: A Case Study of Uttarakhand
Oct 09, 2024

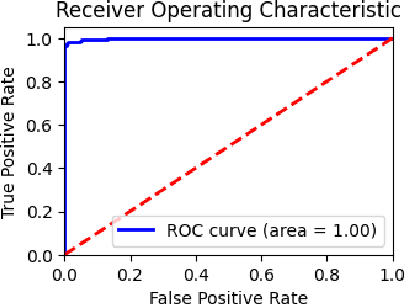
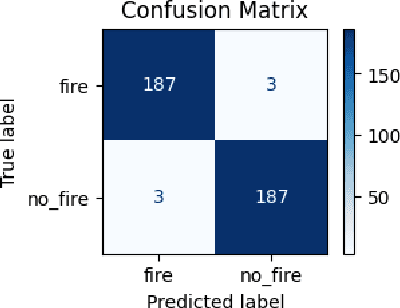
Forest fires pose a significant threat to the environment, human life, and property. Early detection and response are crucial to mitigating the impact of these disasters. However, traditional forest fire detection methods are often hindered by our reliability on manual observation and satellite imagery with low spatial resolution. This paper emphasizes the role of transfer learning in enhancing forest fire detection in India, particularly in overcoming data collection challenges and improving model accuracy across various regions. We compare traditional learning methods with transfer learning, focusing on the unique challenges posed by regional differences in terrain, climate, and vegetation. Transfer learning can be categorized into several types based on the similarity between the source and target tasks, as well as the type of knowledge transferred. One key method is utilizing pre-trained models for efficient transfer learning, which significantly reduces the need for extensive labeled data. We outline the transfer learning process, demonstrating how researchers can adapt pre-trained models like MobileNetV2 for specific tasks such as forest fire detection. Finally, we present experimental results from training and evaluating a deep learning model using the Uttarakhand forest fire dataset, showcasing the effectiveness of transfer learning in this context.
A Dataset of Inertial Measurement Units for Handwritten English Alphabets
Jul 05, 2023This paper presents an end-to-end methodology for collecting datasets to recognize handwritten English alphabets by utilizing Inertial Measurement Units (IMUs) and leveraging the diversity present in the Indian writing style. The IMUs are utilized to capture the dynamic movement patterns associated with handwriting, enabling more accurate recognition of alphabets. The Indian context introduces various challenges due to the heterogeneity in writing styles across different regions and languages. By leveraging this diversity, the collected dataset and the collection system aim to achieve higher recognition accuracy. Some preliminary experimental results demonstrate the effectiveness of the dataset in accurately recognizing handwritten English alphabet in the Indian context. This research can be extended and contributes to the field of pattern recognition and offers valuable insights for developing improved systems for handwriting recognition, particularly in diverse linguistic and cultural contexts.
Designing and Training of Lightweight Neural Networks on Edge Devices using Early Halting in Knowledge Distillation
Sep 30, 2022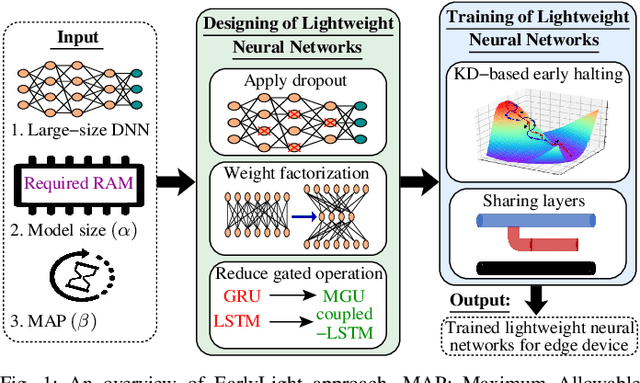
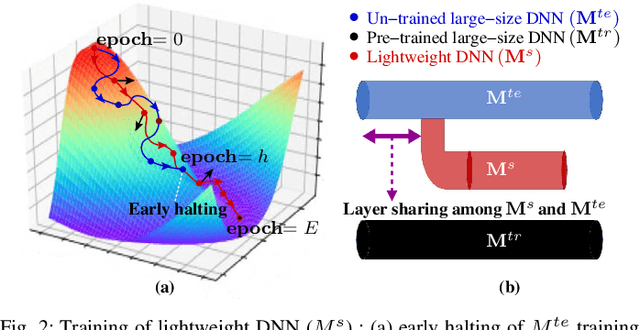
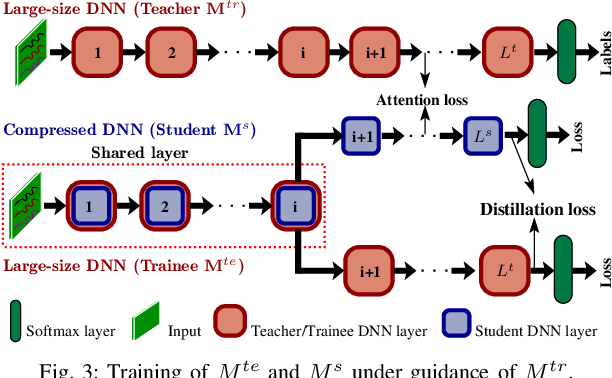
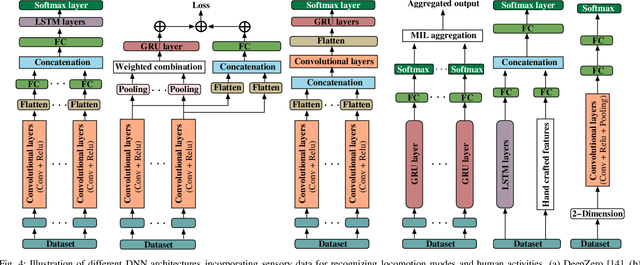
Automated feature extraction capability and significant performance of Deep Neural Networks (DNN) make them suitable for Internet of Things (IoT) applications. However, deploying DNN on edge devices becomes prohibitive due to the colossal computation, energy, and storage requirements. This paper presents a novel approach for designing and training lightweight DNN using large-size DNN. The approach considers the available storage, processing speed, and maximum allowable processing time to execute the task on edge devices. We present a knowledge distillation based training procedure to train the lightweight DNN to achieve adequate accuracy. During the training of lightweight DNN, we introduce a novel early halting technique, which preserves network resources; thus, speedups the training procedure. Finally, we present the empirically and real-world evaluations to verify the effectiveness of the proposed approach under different constraints using various edge devices.
Suppressing Noise from Built Environment Datasets to Reduce Communication Rounds for Convergence of Federated Learning
Sep 03, 2022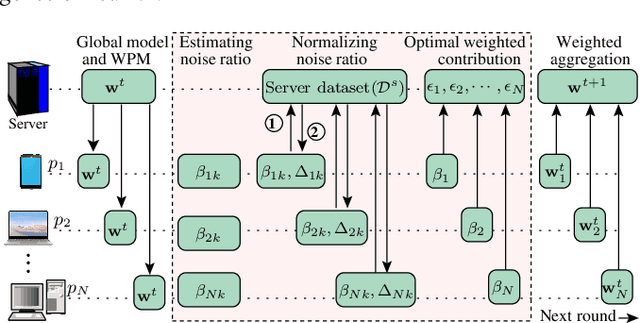
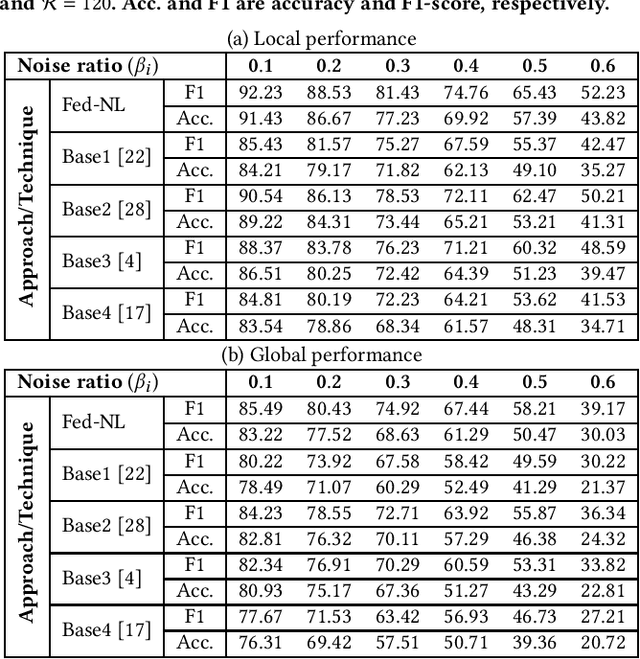
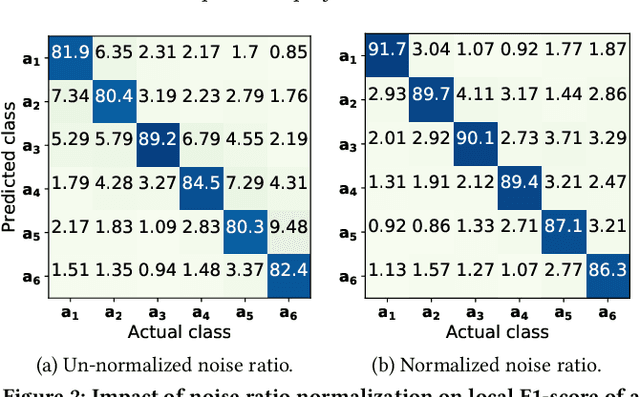
Smart sensing provides an easier and convenient data-driven mechanism for monitoring and control in the built environment. Data generated in the built environment are privacy sensitive and limited. Federated learning is an emerging paradigm that provides privacy-preserving collaboration among multiple participants for model training without sharing private and limited data. The noisy labels in the datasets of the participants degrade the performance and increase the number of communication rounds for convergence of federated learning. Such large communication rounds require more time and energy to train the model. In this paper, we propose a federated learning approach to suppress the unequal distribution of the noisy labels in the dataset of each participant. The approach first estimates the noise ratio of the dataset for each participant and normalizes the noise ratio using the server dataset. The proposed approach can handle bias in the server dataset and minimizes its impact on the participants' dataset. Next, we calculate the optimal weighted contributions of the participants using the normalized noise ratio and influence of each participant. We further derive the expression to estimate the number of communication rounds required for the convergence of the proposed approach. Finally, experimental results demonstrate the effectiveness of the proposed approach over existing techniques in terms of the communication rounds and achieved performance in the built environment.
FedAR+: A Federated Learning Approach to Appliance Recognition with Mislabeled Data in Residential Buildings
Sep 03, 2022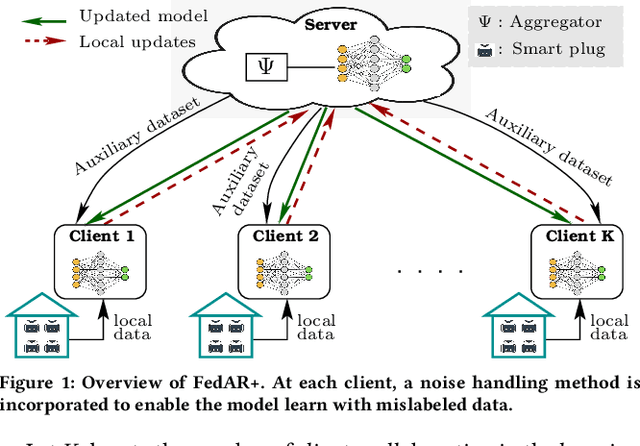
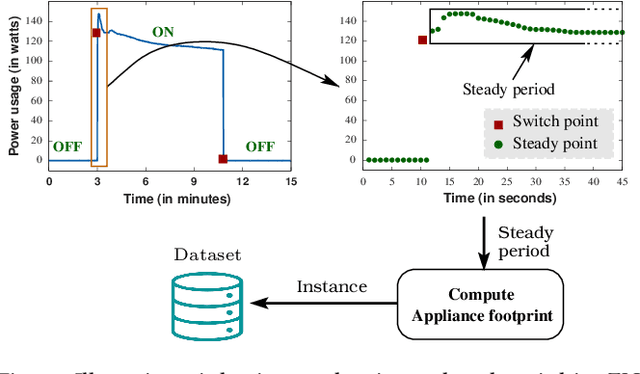
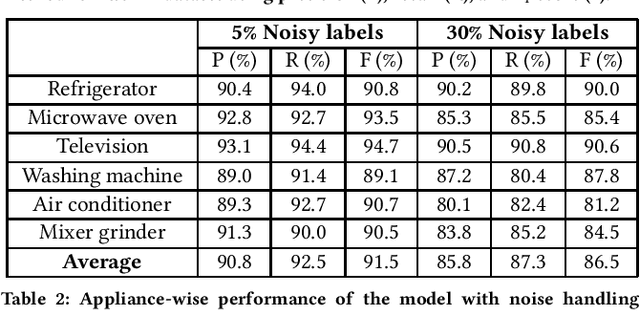
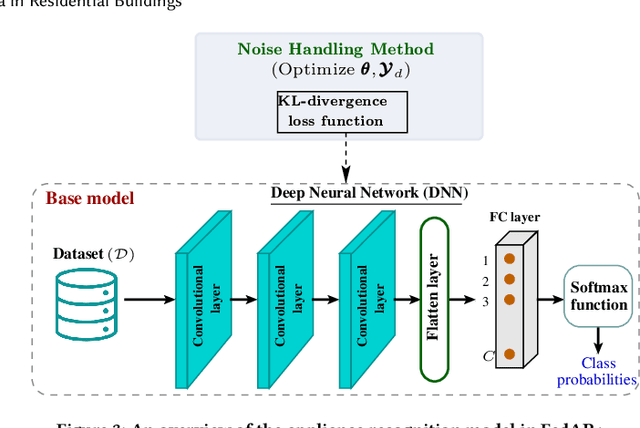
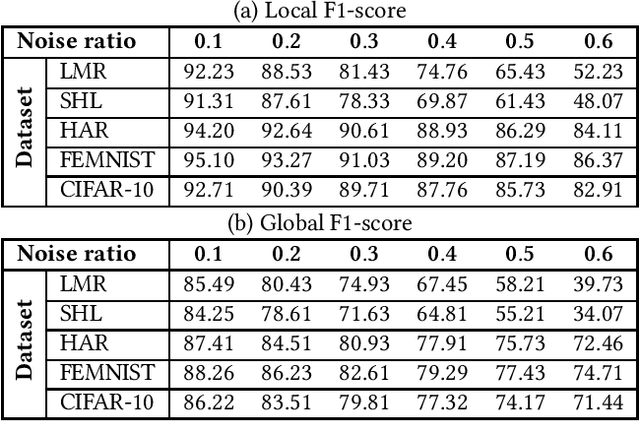
With the enhancement of people's living standards and rapid growth of communication technologies, residential environments are becoming smart and well-connected, increasing overall energy consumption substantially. As household appliances are the primary energy consumers, their recognition becomes crucial to avoid unattended usage, thereby conserving energy and making smart environments more sustainable. An appliance recognition model is traditionally trained at a central server (service provider) by collecting electricity consumption data, recorded via smart plugs, from the clients (consumers), causing a privacy breach. Besides that, the data are susceptible to noisy labels that may appear when an appliance gets connected to a non-designated smart plug. While addressing these issues jointly, we propose a novel federated learning approach to appliance recognition, called FedAR+, enabling decentralized model training across clients in a privacy preserving way even with mislabeled training data. FedAR+ introduces an adaptive noise handling method, essentially a joint loss function incorporating weights and label distribution, to empower the appliance recognition model against noisy labels. By deploying smart plugs in an apartment complex, we collect a labeled dataset that, along with two existing datasets, are utilized to evaluate the performance of FedAR+. Experimental results show that our approach can effectively handle up to $30\%$ concentration of noisy labels while outperforming the prior solutions by a large margin on accuracy.
A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions
Oct 05, 2020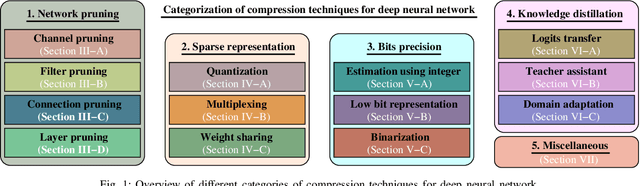
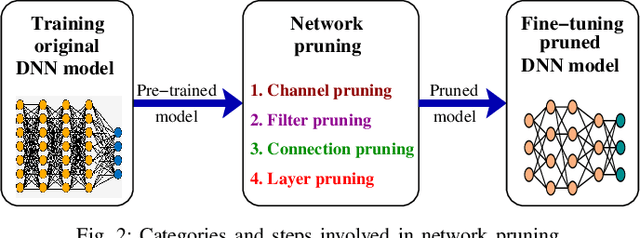
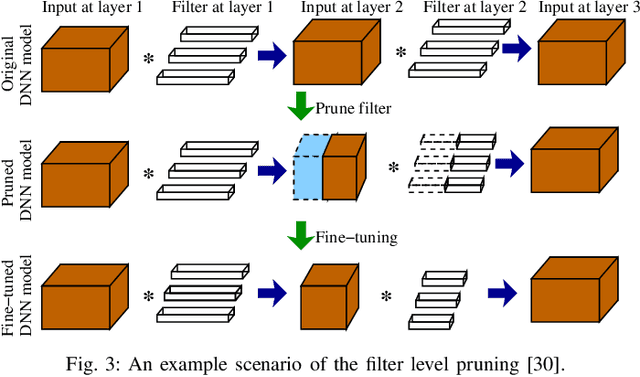

Deep Neural Network (DNN) has gained unprecedented performance due to its automated feature extraction capability. This high order performance leads to significant incorporation of DNN models in different Internet of Things (IoT) applications in the past decade. However, the colossal requirement of computation, energy, and storage of DNN models make their deployment prohibitive on resource constraint IoT devices. Therefore, several compression techniques were proposed in recent years for reducing the storage and computation requirements of the DNN model. These techniques on DNN compression have utilized a different perspective for compressing DNN with minimal accuracy compromise. It encourages us to make a comprehensive overview of the DNN compression techniques. In this paper, we present a comprehensive review of existing literature on compressing DNN model that reduces both storage and computation requirements. We divide the existing approaches into five broad categories, i.e., network pruning, sparse representation, bits precision, knowledge distillation, and miscellaneous, based upon the mechanism incorporated for compressing the DNN model. The paper also discussed the challenges associated with each category of DNN compression techniques. Finally, we provide a quick summary of existing work under each category with the future direction in DNN compression.
Approaches and Applications of Early Classification of Time Series: A Review
May 06, 2020
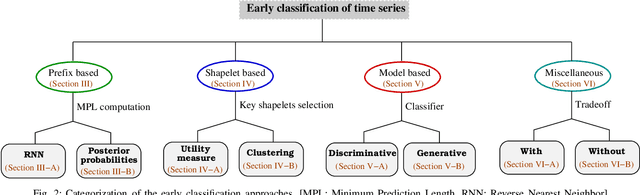
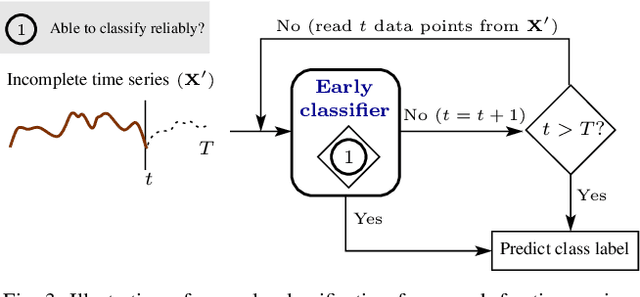
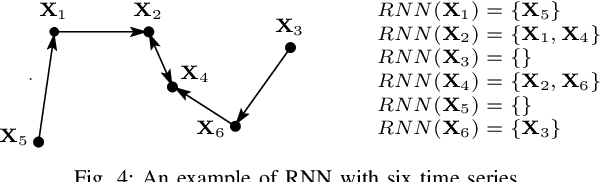
Early classification of time series has been extensively studied for minimizing class prediction delay in time-sensitive applications such as healthcare and finance. A primary task of an early classification approach is to classify an incomplete time series as soon as possible with some desired level of accuracy. Recent years have witnessed several approaches for early classification of time series. As most of the approaches have solved the early classification problem with different aspects, it becomes very important to make a thorough review of the existing solutions to know the current status of the area. These solutions have demonstrated reasonable performance in a wide range of applications including human activity recognition, gene expression based health diagnostic, industrial monitoring, and so on. In this paper, we present a systematic review of current literature on early classification approaches for both univariate and multivariate time series. We divide various existing approaches into four exclusive categories based on their proposed solution strategies. The four categories include prefix based, shapelet based, model based, and miscellaneous approaches. The authors also discuss the applications of early classification in many areas including industrial monitoring, intelligent transportation, and medical. Finally, we provide a quick summary of the current literature with future research directions.