 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions
Paper and Code
Oct 05, 2020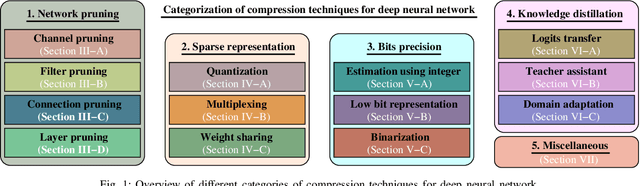
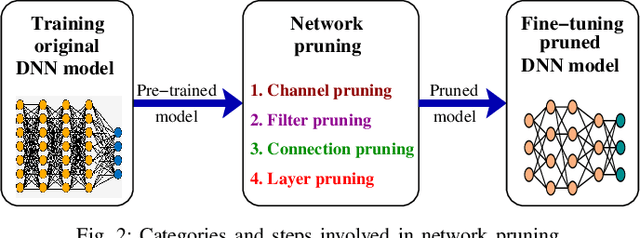
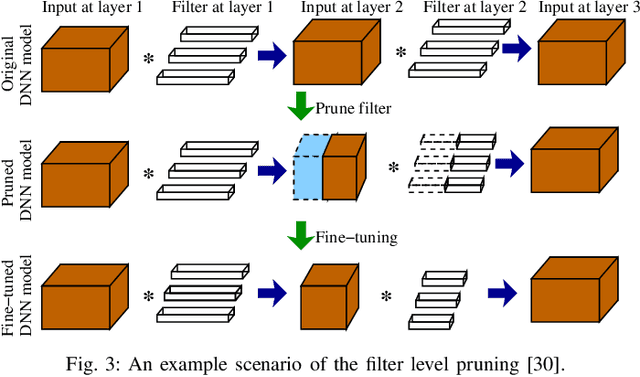

Deep Neural Network (DNN) has gained unprecedented performance due to its automated feature extraction capability. This high order performance leads to significant incorporation of DNN models in different Internet of Things (IoT) applications in the past decade. However, the colossal requirement of computation, energy, and storage of DNN models make their deployment prohibitive on resource constraint IoT devices. Therefore, several compression techniques were proposed in recent years for reducing the storage and computation requirements of the DNN model. These techniques on DNN compression have utilized a different perspective for compressing DNN with minimal accuracy compromise. It encourages us to make a comprehensive overview of the DNN compression techniques. In this paper, we present a comprehensive review of existing literature on compressing DNN model that reduces both storage and computation requirements. We divide the existing approaches into five broad categories, i.e., network pruning, sparse representation, bits precision, knowledge distillation, and miscellaneous, based upon the mechanism incorporated for compressing the DNN model. The paper also discussed the challenges associated with each category of DNN compression techniques. Finally, we provide a quick summary of existing work under each category with the future direction in DNN compression.