 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer-in-Transformer Network Utilizing Knowledge Distillation for Image Recognition
Feb 24, 2025This paper presents a novel knowledge distillation neural architecture leveraging efficient transformer networks for effective image classification. Natural images display intricate arrangements encompassing numerous extraneous elements. Vision transformers utilize localized patches to compute attention. However, exclusive dependence on patch segmentation proves inadequate in sufficiently encompassing the comprehensive nature of the image. To address this issue, we have proposed an inner-outer transformer-based architecture, which gives attention to the global and local aspects of the image. Moreover, The training of transformer models poses significant challenges due to their demanding resource, time, and data requirements. To tackle this, we integrate knowledge distillation into the architecture, enabling efficient learning. Leveraging insights from a larger teacher model, our approach enhances learning efficiency and effectiveness. Significantly, the transformer-in-transformer network acquires lightweight characteristics by means of distillation conducted within the feature extraction layer. Our featured network's robustness is established through substantial experimentation on the MNIST, CIFAR10, and CIFAR100 datasets, demonstrating commendable top-1 and top-5 accuracy. The conducted ablative analysis comprehensively validates the effectiveness of the chosen parameters and settings, showcasing their superiority against contemporary methodologies. Remarkably, the proposed Transformer-in-Transformer Network (TITN) model achieves impressive performance milestones across various datasets: securing the highest top-1 accuracy of 74.71% and a top-5 accuracy of 92.28% for the CIFAR100 dataset, attaining an unparalleled top-1 accuracy of 92.03% and top-5 accuracy of 99.80% for the CIFAR-10 dataset, and registering an exceptional top-1 accuracy of 99.56% for the MNIST dataset.
Single Image Internal Distribution Measurement Using Non-Local Variational Autoencoder
Apr 02, 2022
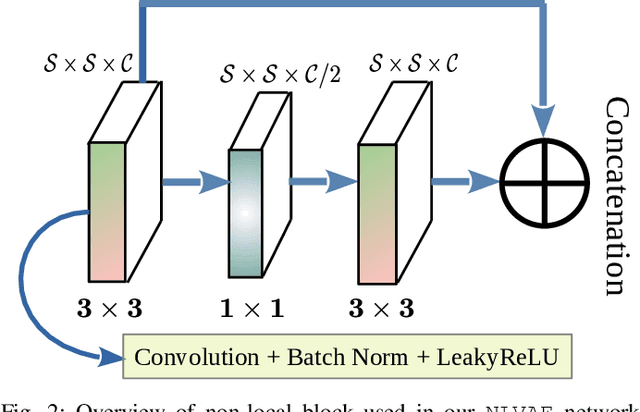
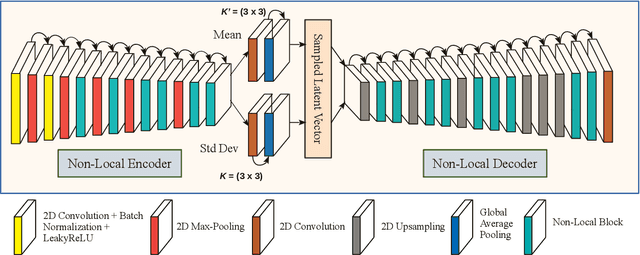

Deep learning-based super-resolution methods have shown great promise, especially for single image super-resolution (SISR) tasks. Despite the performance gain, these methods are limited due to their reliance on copious data for model training. In addition, supervised SISR solutions rely on local neighbourhood information focusing only on the feature learning processes for the reconstruction of low-dimensional images. Moreover, they fail to capitalize on global context due to their constrained receptive field. To combat these challenges, this paper proposes a novel image-specific solution, namely non-local variational autoencoder (\texttt{NLVAE}), to reconstruct a high-resolution (HR) image from a single low-resolution (LR) image without the need for any prior training. To harvest maximum details for various receptive regions and high-quality synthetic images, \texttt{NLVAE} is introduced as a self-supervised strategy that reconstructs high-resolution images using disentangled information from the non-local neighbourhood. Experimental results from seven benchmark datasets demonstrate the effectiveness of the \texttt{NLVAE} model. Moreover, our proposed model outperforms a number of baseline and state-of-the-art methods as confirmed through extensive qualitative and quantitative evaluations.