 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnronQA: Towards Personalized RAG over Private Documents
May 01, 2025Retrieval Augmented Generation (RAG) has become one of the most popular methods for bringing knowledge-intensive context to large language models (LLM) because of its ability to bring local context at inference time without the cost or data leakage risks associated with fine-tuning. A clear separation of private information from the LLM training has made RAG the basis for many enterprise LLM workloads as it allows the company to augment LLM's understanding using customers' private documents. Despite its popularity for private documents in enterprise deployments, current RAG benchmarks for validating and optimizing RAG pipelines draw their corpora from public data such as Wikipedia or generic web pages and offer little to no personal context. Seeking to empower more personal and private RAG we release the EnronQA benchmark, a dataset of 103,638 emails with 528,304 question-answer pairs across 150 different user inboxes. EnronQA enables better benchmarking of RAG pipelines over private data and allows for experimentation on the introduction of personalized retrieval settings over realistic data. Finally, we use EnronQA to explore the tradeoff in memorization and retrieval when reasoning over private documents.
Arctic-Embed: Scalable, Efficient, and Accurate Text Embedding Models
May 08, 2024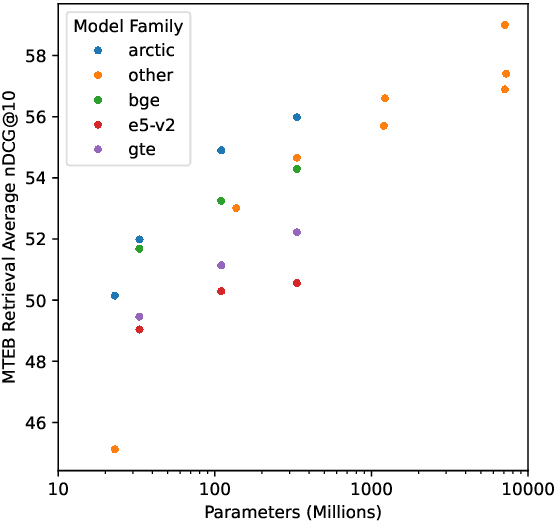


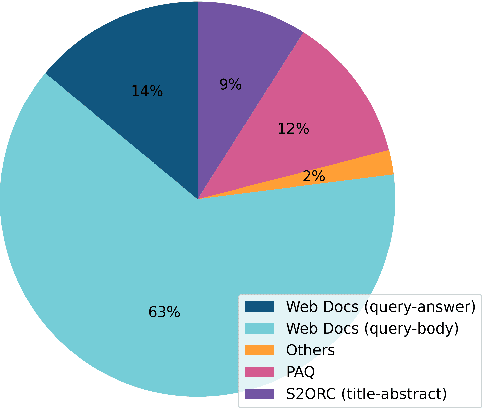
This report describes the training dataset creation and recipe behind the family of \texttt{arctic-embed} text embedding models (a set of five models ranging from 22 to 334 million parameters with weights open-sourced under an Apache-2 license). At the time of their release, each model achieved state-of-the-art retrieval accuracy for models of their size on the MTEB Retrieval leaderboard, with the largest model, arctic-embed-l outperforming closed source embedding models such as Cohere's embed-v3 and Open AI's text-embed-3-large. In addition to the details of our training recipe, we have provided several informative ablation studies, which we believe are the cause of our model performance.