Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-Embed: Scalable, Efficient, and Accurate Text Embedding Models
Paper and Code
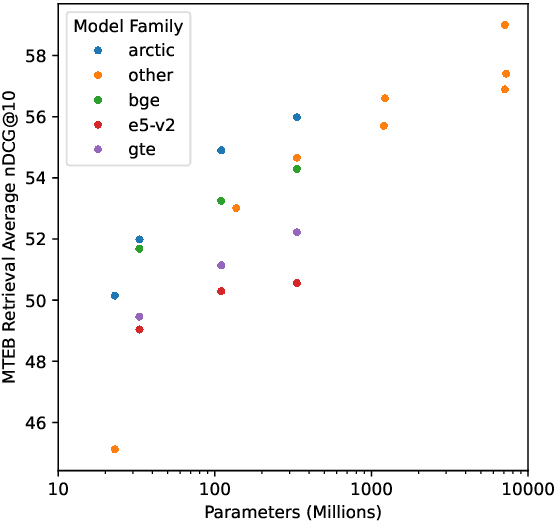


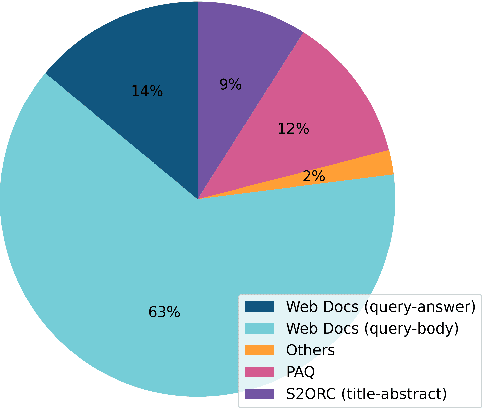
This report describes the training dataset creation and recipe behind the family of \texttt{arctic-embed} text embedding models (a set of five models ranging from 22 to 334 million parameters with weights open-sourced under an Apache-2 license). At the time of their release, each model achieved state-of-the-art retrieval accuracy for models of their size on the MTEB Retrieval leaderboard, with the largest model, arctic-embed-l outperforming closed source embedding models such as Cohere's embed-v3 and Open AI's text-embed-3-large. In addition to the details of our training recipe, we have provided several informative ablation studies, which we believe are the cause of our model performance.
* 17 pages, 11 Figures, 9 tables
View paper on