 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblems with Chinchilla Approach 2: Systematic Biases in IsoFLOP Parabola Fits
Mar 25, 2026Chinchilla Approach 2 is among the most widely used methods for fitting neural scaling laws. Its parabolic approximation introduces systematic biases in compute-optimal allocation estimates, even on noise-free synthetic data. Applied to published Llama 3 IsoFLOP data at open frontier compute scales, these biases imply a parameter underallocation corresponding to 6.5% of the $3.8\times10^{25}$ FLOP training budget and \$1.4M (90% CI: \$412K-\$2.9M) in unnecessary compute at 50% H100 MFU. Simulated multimodal model misallocations show even greater opportunity costs due to higher loss surface asymmetry. Three sources of this error are examined: IsoFLOP sampling grid width (Taylor approximation accuracy), uncentered IsoFLOP sampling, and loss surface asymmetry ($α\neq β$). Chinchilla Approach 3 largely eliminates these biases but is often regarded as less data-efficient, numerically unstable, prone to local minima, and harder to implement. Each concern is shown to be unfounded or addressable, especially when the partially linear structure of the objective is exploited via Variable Projection, enabling unbiased inference on all five loss surface parameters through a two-dimensional optimization that is well-conditioned, analytically differentiable, and amenable to dense, or even exhaustive, grid search. It may serve as a more convenient replacement for Approach 2 or a more scalable alternative for adaptations of Approach 3 to richer scaling law formulations. See https://github.com/Open-Athena/vpnls for details and https://openathena.ai/scaling-law-analysis for other results from this study.
Scaling Open Discrete Audio Foundation Models with Interleaved Semantic, Acoustic, and Text Tokens
Feb 18, 2026Current audio language models are predominantly text-first, either extending pre-trained text LLM backbones or relying on semantic-only audio tokens, limiting general audio modeling. This paper presents a systematic empirical study of native audio foundation models that apply next-token prediction to audio at scale, jointly modeling semantic content, acoustic details, and text to support both general audio generation and cross-modal capabilities. We provide comprehensive empirical insights for building such models: (1) We systematically investigate design choices -- data sources, text mixture ratios, and token composition -- establishing a validated training recipe. (2) We conduct the first scaling law study for discrete audio models via IsoFLOP analysis on 64 models spanning $3{\times}10^{18}$ to $3{\times}10^{20}$ FLOPs, finding that optimal data grows 1.6$\times$ faster than optimal model size. (3) We apply these lessons to train SODA (Scaling Open Discrete Audio), a suite of models from 135M to 4B parameters on 500B tokens, comparing against our scaling predictions and existing models. SODA serves as a flexible backbone for diverse audio/text tasks -- we demonstrate this by fine-tuning for voice-preserving speech-to-speech translation, using the same unified architecture.
Culture Cartography: Mapping the Landscape of Cultural Knowledge
Oct 31, 2025To serve global users safely and productively, LLMs need culture-specific knowledge that might not be learned during pre-training. How do we find such knowledge that is (1) salient to in-group users, but (2) unknown to LLMs? The most common solutions are single-initiative: either researchers define challenging questions that users passively answer (traditional annotation), or users actively produce data that researchers structure as benchmarks (knowledge extraction). The process would benefit from mixed-initiative collaboration, where users guide the process to meaningfully reflect their cultures, and LLMs steer the process towards more challenging questions that meet the researcher's goals. We propose a mixed-initiative methodology called CultureCartography. Here, an LLM initializes annotation with questions for which it has low-confidence answers, making explicit both its prior knowledge and the gaps therein. This allows a human respondent to fill these gaps and steer the model towards salient topics through direct edits. We implement this methodology as a tool called CultureExplorer. Compared to a baseline where humans answer LLM-proposed questions, we find that CultureExplorer more effectively produces knowledge that leading models like DeepSeek R1 and GPT-4o are missing, even with web search. Fine-tuning on this data boosts the accuracy of Llama-3.1-8B by up to 19.2% on related culture benchmarks.
SynthesizeMe! Inducing Persona-Guided Prompts for Personalized Reward Models in LLMs
Jun 05, 2025Recent calls for pluralistic alignment of Large Language Models (LLMs) encourage adapting models to diverse user preferences. However, most prior work on personalized reward models heavily rely on additional identity information, such as demographic details or a predefined set of preference categories. To this end, we introduce SynthesizeMe, an approach to inducing synthetic user personas from user interactions for personalized reward modeling. SynthesizeMe first generates and verifies reasoning to explain user preferences, then induces synthetic user personas from that reasoning, and finally filters to informative prior user interactions in order to build personalized prompts for a particular user. We show that using SynthesizeMe induced prompts improves personalized LLM-as-a-judge accuracy by 4.4% on Chatbot Arena. Combining SynthesizeMe derived prompts with a reward model achieves top performance on PersonalRewardBench: a new curation of user-stratified interactions with chatbots collected from 854 users of Chatbot Arena and PRISM.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Optimizing Pretraining Data Mixtures with LLM-Estimated Utility
Jan 20, 2025


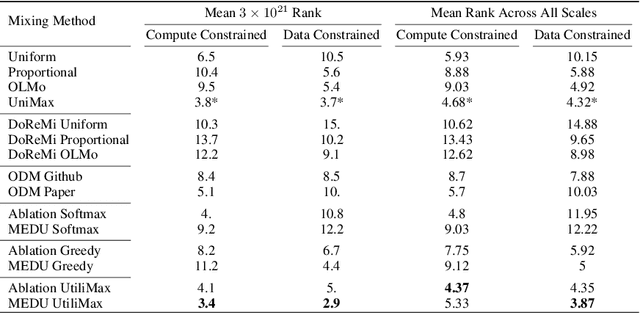
Large Language Models improve with increasing amounts of high-quality training data. However, leveraging larger datasets requires balancing quality, quantity, and diversity across sources. After evaluating nine baseline methods under both compute- and data-constrained scenarios, we find token-count heuristics outperform manual and learned mixes, indicating that simple approaches accounting for dataset size and diversity are surprisingly effective. Building on this insight, we propose two complementary approaches: UtiliMax, which extends token-based heuristics by incorporating utility estimates from reduced-scale ablations, achieving up to a 10.6x speedup over manual baselines; and Model Estimated Data Utility (MEDU), which leverages LLMs to estimate data utility from small samples, matching ablation-based performance while reducing computational requirements by $\sim$200x. Together, these approaches establish a new framework for automated, compute-efficient data mixing that is robust across training regimes.
Distilling an End-to-End Voice Assistant Without Instruction Training Data
Oct 03, 2024



Voice assistants, such as Siri and Google Assistant, typically model audio and text separately, resulting in lost speech information and increased complexity. Recent efforts to address this with end-to-end Speech Large Language Models (LLMs) trained with supervised finetuning (SFT) have led to models ``forgetting" capabilities from text-only LLMs. Our work proposes an alternative paradigm for training Speech LLMs without instruction data, using the response of a text-only LLM to transcripts as self-supervision. Importantly, this process can be performed without annotated responses. We show that our Distilled Voice Assistant (DiVA) generalizes to Spoken Question Answering, Classification, and Translation. Furthermore, we show that DiVA better meets user preferences, achieving a 72\% win rate compared with state-of-the-art models like Qwen 2 Audio, despite using $>$100x less training compute.
Measuring and Addressing Indexical Bias in Information Retrieval
Jun 06, 2024



Information Retrieval (IR) systems are designed to deliver relevant content, but traditional systems may not optimize rankings for fairness, neutrality, or the balance of ideas. Consequently, IR can often introduce indexical biases, or biases in the positional order of documents. Although indexical bias can demonstrably affect people's opinion, voting patterns, and other behaviors, these issues remain understudied as the field lacks reliable metrics and procedures for automatically measuring indexical bias. Towards this end, we introduce the PAIR framework, which supports automatic bias audits for ranked documents or entire IR systems. After introducing DUO, the first general-purpose automatic bias metric, we run an extensive evaluation of 8 IR systems on a new corpus of 32k synthetic and 4.7k natural documents, with 4k queries spanning 1.4k controversial issue topics. A human behavioral study validates our approach, showing that our bias metric can help predict when and how indexical bias will shift a reader's opinion.
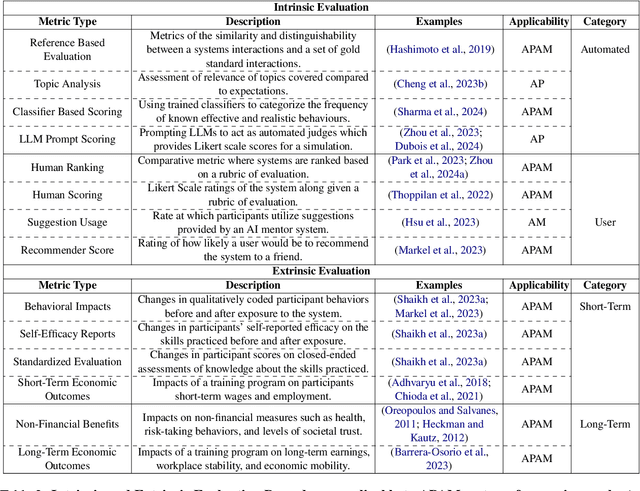
Social Skill Training with Large Language Models
Apr 05, 2024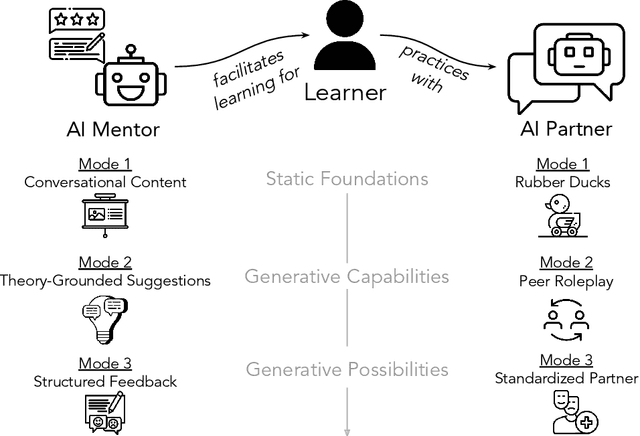
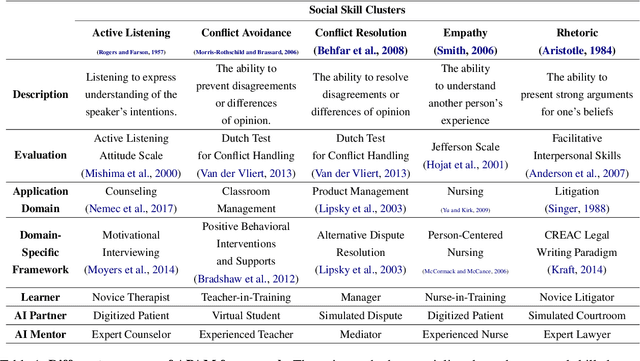
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of reach for most people. How can we make social skill training more available, accessible, and inviting? Drawing upon interdisciplinary research from communication and psychology, this perspective paper identifies social skill barriers to enter specialized fields. Then we present a solution that leverages large language models for social skill training via a generic framework. Our AI Partner, AI Mentor framework merges experiential learning with realistic practice and tailored feedback. This work ultimately calls for cross-disciplinary innovation to address the broader implications for workforce development and social equality.
Unintended Impacts of LLM Alignment on Global Representation
Feb 22, 2024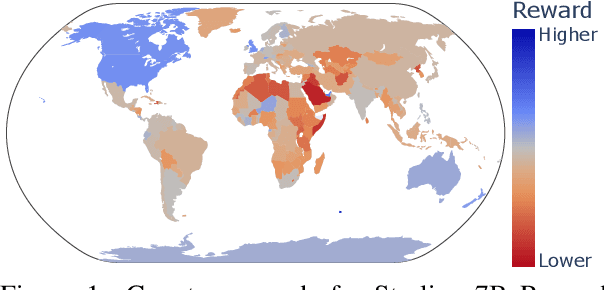

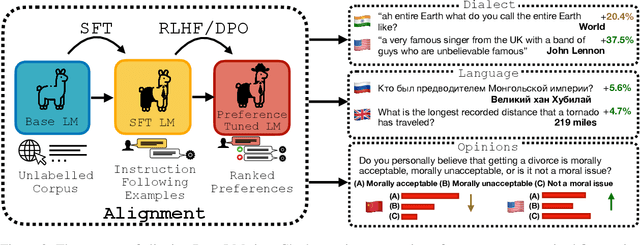
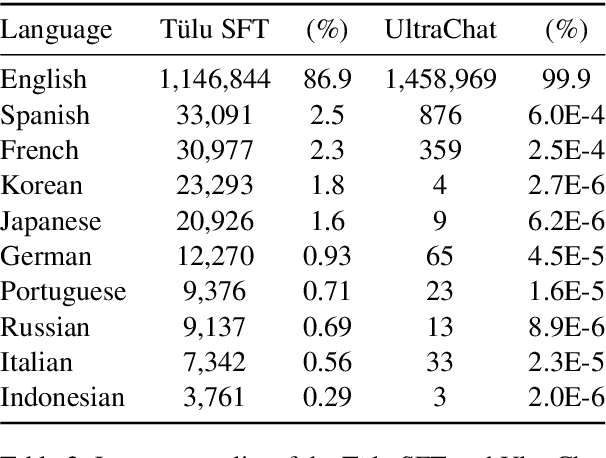
Before being deployed for user-facing applications, developers align Large Language Models (LLMs) to user preferences through a variety of procedures, such as Reinforcement Learning From Human Feedback (RLHF) and Direct Preference Optimization (DPO). Current evaluations of these procedures focus on benchmarks of instruction following, reasoning, and truthfulness. However, human preferences are not universal, and aligning to specific preference sets may have unintended effects. We explore how alignment impacts performance along three axes of global representation: English dialects, multilingualism, and opinions from and about countries worldwide. Our results show that current alignment procedures create disparities between English dialects and global opinions. We find alignment improves capabilities in several languages. We conclude by discussing design decisions that led to these unintended impacts and recommendations for more equitable preference tuning.