 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations
Oct 26, 2025AI agents are continually optimized for tasks related to human work, such as software engineering and professional writing, signaling a pressing trend with significant impacts on the human workforce. However, these agent developments have often not been grounded in a clear understanding of how humans execute work, to reveal what expertise agents possess and the roles they can play in diverse workflows. In this work, we study how agents do human work by presenting the first direct comparison of human and agent workers across multiple essential work-related skills: data analysis, engineering, computation, writing, and design. To better understand and compare heterogeneous computer-use activities of workers, we introduce a scalable toolkit to induce interpretable, structured workflows from either human or agent computer-use activities. Using such induced workflows, we compare how humans and agents perform the same tasks and find that: (1) While agents exhibit promise in their alignment to human workflows, they take an overwhelmingly programmatic approach across all work domains, even for open-ended, visually dependent tasks like design, creating a contrast with the UI-centric methods typically used by humans. (2) Agents produce work of inferior quality, yet often mask their deficiencies via data fabrication and misuse of advanced tools. (3) Nonetheless, agents deliver results 88.3% faster and cost 90.4-96.2% less than humans, highlighting the potential for enabling efficient collaboration by delegating easily programmable tasks to agents.
SynthesizeMe! Inducing Persona-Guided Prompts for Personalized Reward Models in LLMs
Jun 05, 2025Recent calls for pluralistic alignment of Large Language Models (LLMs) encourage adapting models to diverse user preferences. However, most prior work on personalized reward models heavily rely on additional identity information, such as demographic details or a predefined set of preference categories. To this end, we introduce SynthesizeMe, an approach to inducing synthetic user personas from user interactions for personalized reward modeling. SynthesizeMe first generates and verifies reasoning to explain user preferences, then induces synthetic user personas from that reasoning, and finally filters to informative prior user interactions in order to build personalized prompts for a particular user. We show that using SynthesizeMe induced prompts improves personalized LLM-as-a-judge accuracy by 4.4% on Chatbot Arena. Combining SynthesizeMe derived prompts with a reward model achieves top performance on PersonalRewardBench: a new curation of user-stratified interactions with chatbots collected from 854 users of Chatbot Arena and PRISM.
Creating General User Models from Computer Use
May 19, 2025Human-computer interaction has long imagined technology that understands us-from our preferences and habits, to the timing and purpose of our everyday actions. Yet current user models remain fragmented, narrowly tailored to specific apps, and incapable of the flexible reasoning required to fulfill these visions. This paper presents an architecture for a general user model (GUM) that learns about you by observing any interaction you have with your computer. The GUM takes as input any unstructured observation of a user (e.g., device screenshots) and constructs confidence-weighted propositions that capture user knowledge and preferences. GUMs can infer that a user is preparing for a wedding they're attending from messages with a friend. Or recognize that a user is struggling with a collaborator's feedback on a draft by observing multiple stalled edits and a switch to reading related work. GUMs introduce an architecture that infers new propositions about a user from multimodal observations, retrieves related propositions for context, and continuously revises existing propositions. To illustrate the breadth of applications that GUMs enable, we demonstrate how they augment chat-based assistants with context, manage OS notifications to selectively surface important information, and enable interactive agents that adapt to preferences across apps. We also instantiate proactive assistants (GUMBOs) that discover and execute useful suggestions on a user's behalf using their GUM. In our evaluations, we find that GUMs make calibrated and accurate inferences about users, and that assistants built on GUMs proactively identify and perform actions that users wouldn't think to request explicitly. Altogether, GUMs introduce methods that leverage multimodal models to understand unstructured context, enabling long-standing visions of HCI and entirely new interactive systems that anticipate user needs.
Navigating Rifts in Human-LLM Grounding: Study and Benchmark
Mar 18, 2025Language models excel at following instructions but often struggle with the collaborative aspects of conversation that humans naturally employ. This limitation in grounding -- the process by which conversation participants establish mutual understanding -- can lead to outcomes ranging from frustrated users to serious consequences in high-stakes scenarios. To systematically study grounding challenges in human-LLM interactions, we analyze logs from three human-assistant datasets: WildChat, MultiWOZ, and Bing Chat. We develop a taxonomy of grounding acts and build models to annotate and forecast grounding behavior. Our findings reveal significant differences in human-human and human-LLM grounding: LLMs were three times less likely to initiate clarification and sixteen times less likely to provide follow-up requests than humans. Additionally, early grounding failures predicted later interaction breakdowns. Building on these insights, we introduce RIFTS: a benchmark derived from publicly available LLM interaction data containing situations where LLMs fail to initiate grounding. We note that current frontier models perform poorly on RIFTS, highlighting the need to reconsider how we train and prompt LLMs for human interaction. To this end, we develop a preliminary intervention that mitigates grounding failures.
Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
Jun 02, 2024Language models are aligned to emulate the collective voice of many, resulting in outputs that align with no one in particular. Steering LLMs away from generic output is possible through supervised finetuning or RLHF, but requires prohibitively large datasets for new ad-hoc tasks. We argue that it is instead possible to align an LLM to a specific setting by leveraging a very small number ($<10$) of demonstrations as feedback. Our method, Demonstration ITerated Task Optimization (DITTO), directly aligns language model outputs to a user's demonstrated behaviors. Derived using ideas from online imitation learning, DITTO cheaply generates online comparison data by treating users' demonstrations as preferred over output from the LLM and its intermediate checkpoints. We evaluate DITTO's ability to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts. Additionally, we conduct a user study soliciting a range of demonstrations from participants ($N=16$). Across our benchmarks and user study, we find that win-rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. By using demonstrations as feedback directly, DITTO offers a novel method for effective customization of LLMs.
Social Skill Training with Large Language Models
Apr 05, 2024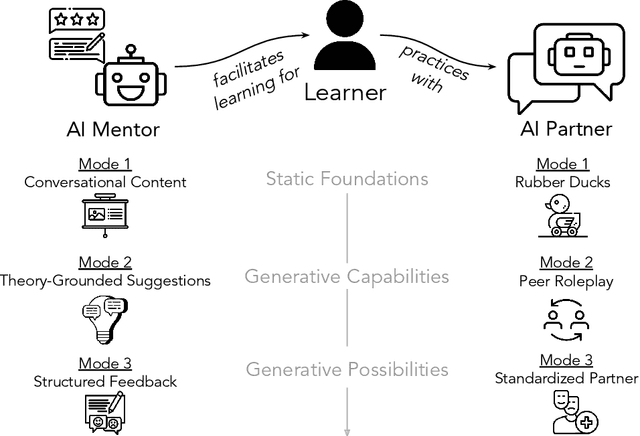
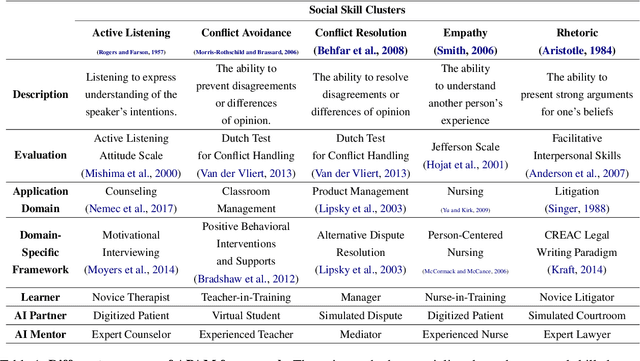
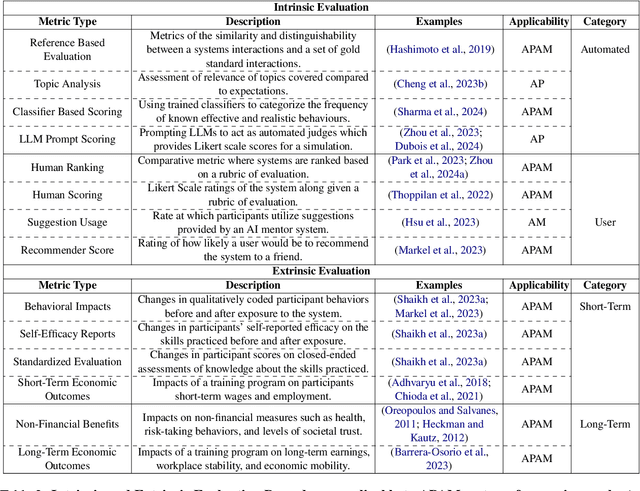
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of reach for most people. How can we make social skill training more available, accessible, and inviting? Drawing upon interdisciplinary research from communication and psychology, this perspective paper identifies social skill barriers to enter specialized fields. Then we present a solution that leverages large language models for social skill training via a generic framework. Our AI Partner, AI Mentor framework merges experiential learning with realistic practice and tailored feedback. This work ultimately calls for cross-disciplinary innovation to address the broader implications for workforce development and social equality.
Grounding or Guesswork? Large Language Models are Presumptive Grounders
Nov 15, 2023Effective conversation requires common ground: a shared understanding between the participants. Common ground, however, does not emerge spontaneously in conversation. Speakers and listeners work together to both identify and construct a shared basis while avoiding misunderstanding. To accomplish grounding, humans rely on a range of dialogue acts, like clarification (What do you mean?) and acknowledgment (I understand.). In domains like teaching and emotional support, carefully constructing grounding prevents misunderstanding. However, it is unclear whether large language models (LLMs) leverage these dialogue acts in constructing common ground. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify attempted grounding. We study whether LLMs use these grounding acts, simulating them taking turns from several dialogue datasets, and comparing the results to humans. We find that current LLMs are presumptive grounders, biased towards assuming common ground without using grounding acts. To understand the roots of this behavior, we examine the role of instruction tuning and reinforcement learning with human feedback (RLHF), finding that RLHF leads to less grounding. Altogether, our work highlights the need for more research investigating grounding in human-AI interaction.
Rehearsal: Simulating Conflict to Teach Conflict Resolution
Sep 21, 2023



Interpersonal conflict is an uncomfortable but unavoidable fact of life. Navigating conflict successfully is a skill -- one that can be learned through deliberate practice -- but few have access to effective training or feedback. To expand this access, we introduce Rehearsal, a system that allows users to rehearse conflicts with a believable simulated interlocutor, explore counterfactual "what if?" scenarios to identify alternative conversational paths, and learn through feedback on how and when to apply specific conflict strategies. Users can utilize Rehearsal to practice handling a variety of predefined conflict scenarios, from office disputes to relationship issues, or they can choose to create their own. To enable Rehearsal, we develop IRP prompting, a method of conditioning output of a large language model on the influential Interest-Rights-Power (IRP) theory from conflict resolution. Rehearsal uses IRP to generate utterances grounded in conflict resolution theory, guiding users towards counterfactual conflict resolution strategies that help de-escalate difficult conversations. In a between-subjects evaluation, 40 participants engaged in an actual conflict with a confederate after training. Compared to a control group with lecture material covering the same IRP theory, participants with simulated training from Rehearsal significantly improved their performance in the unaided conflict: they reduced their use of escalating competitive strategies by an average of 67%, while doubling their use of cooperative strategies. Overall, Rehearsal highlights the potential effectiveness of language models as tools for learning and practicing interpersonal skills.
Modeling Cross-Cultural Pragmatic Inference with Codenames Duet
Jun 04, 2023



Pragmatic reference enables efficient interpersonal communication. Prior work uses simple reference games to test models of pragmatic reasoning, often with unidentified speakers and listeners. In practice, however, speakers' sociocultural background shapes their pragmatic assumptions. For example, readers of this paper assume NLP refers to "Natural Language Processing," and not "Neuro-linguistic Programming." This work introduces the Cultural Codes dataset, which operationalizes sociocultural pragmatic inference in a simple word reference game. Cultural Codes is based on the multi-turn collaborative two-player game, Codenames Duet. Our dataset consists of 794 games with 7,703 turns, distributed across 153 unique players. Alongside gameplay, we collect information about players' personalities, values, and demographics. Utilizing theories of communication and pragmatics, we predict each player's actions via joint modeling of their sociocultural priors and the game context. Our experiments show that accounting for background characteristics significantly improves model performance for tasks related to both clue giving and guessing, indicating that sociocultural priors play a vital role in gameplay decisions.
Can Large Language Models Transform Computational Social Science?
Apr 12, 2023Large Language Models (LLMs) like ChatGPT are capable of successfully performing many language processing tasks zero-shot (without the need for training data). If this capacity also applies to the coding of social phenomena like persuasiveness and political ideology, then LLMs could effectively transform Computational Social Science (CSS). This work provides a road map for using LLMs as CSS tools. Towards this end, we contribute a set of prompting best practices and an extensive evaluation pipeline to measure the zero-shot performance of 13 language models on 24 representative CSS benchmarks. On taxonomic labeling tasks (classification), LLMs fail to outperform the best fine-tuned models but still achieve fair levels of agreement with humans. On free-form coding tasks (generation), LLMs produce explanations that often exceed the quality of crowdworkers' gold references. We conclude that today's LLMs can radically augment the CSS research pipeline in two ways: (1) serving as zero-shot data annotators on human annotation teams, and (2) bootstrapping challenging creative generation tasks (e.g., explaining the hidden meaning behind text). In summary, LLMs can significantly reduce costs and increase efficiency of social science analysis in partnership with humans.