 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2AHP: Inferring Structured Multi-Criteria Decision Models via Semantic Trees with LLMs
Jan 23, 2026While Large Language Models (LLMs) demonstrate remarkable proficiency in semantic understanding, they often struggle to ensure structural consistency and reasoning reliability in complex decision-making tasks that demand rigorous logic. Although classical decision theories, such as the Analytic Hierarchy Process (AHP), offer systematic rational frameworks, their construction relies heavily on labor-intensive domain expertise, creating an "expert bottleneck" that hinders scalability in general scenarios. To bridge the gap between the generalization capabilities of LLMs and the rigor of decision theory, we propose Doc2AHP, a novel structured inference framework guided by AHP principles. Eliminating the need for extensive annotated data or manual intervention, our approach leverages the structural principles of AHP as constraints to direct the LLM in a constrained search within the unstructured document space, thereby enforcing the logical entailment between parent and child nodes. Furthermore, we introduce a multi-agent weighting mechanism coupled with an adaptive consistency optimization strategy to ensure the numerical consistency of weight allocation. Empirical results demonstrate that Doc2AHP not only empowers non-expert users to construct high-quality decision models from scratch but also significantly outperforms direct generative baselines in both logical completeness and downstream task accuracy.
Virtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

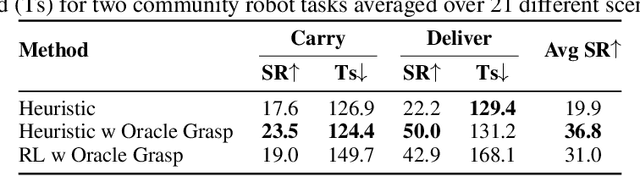

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
Retrieval Augmented Decision-Making: A Requirements-Driven, Multi-Criteria Framework for Structured Decision Support
May 24, 2025Various industries have produced a large number of documents such as industrial plans, technical guidelines, and regulations that are structurally complex and content-wise fragmented. This poses significant challenges for experts and decision-makers in terms of retrieval and understanding. Although existing LLM-based Retrieval-Augmented Generation methods can provide context-related suggestions, they lack quantitative weighting and traceable reasoning paths, making it difficult to offer multi-level and transparent decision support. To address this issue, this paper proposes the RAD method, which integrates Multi-Criteria Decision Making with the semantic understanding capabilities of LLMs. The method automatically extracts key criteria from industry documents, builds a weighted hierarchical decision model, and generates structured reports under model guidance. The RAD framework introduces explicit weight assignment and reasoning chains in decision generation to ensure accuracy, completeness, and traceability. Experiments show that in various decision-making tasks, the decision reports generated by RAD significantly outperform existing methods in terms of detail, rationality, and structure, demonstrating its application value and potential in complex decision support scenarios.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
TesserAct: Learning 4D Embodied World Models
Apr 29, 2025



This paper presents an effective approach for learning novel 4D embodied world models, which predict the dynamic evolution of 3D scenes over time in response to an embodied agent's actions, providing both spatial and temporal consistency. We propose to learn a 4D world model by training on RGB-DN (RGB, Depth, and Normal) videos. This not only surpasses traditional 2D models by incorporating detailed shape, configuration, and temporal changes into their predictions, but also allows us to effectively learn accurate inverse dynamic models for an embodied agent. Specifically, we first extend existing robotic manipulation video datasets with depth and normal information leveraging off-the-shelf models. Next, we fine-tune a video generation model on this annotated dataset, which jointly predicts RGB-DN (RGB, Depth, and Normal) for each frame. We then present an algorithm to directly convert generated RGB, Depth, and Normal videos into a high-quality 4D scene of the world. Our method ensures temporal and spatial coherence in 4D scene predictions from embodied scenarios, enables novel view synthesis for embodied environments, and facilitates policy learning that significantly outperforms those derived from prior video-based world models.
SnapMem: Snapshot-based 3D Scene Memory for Embodied Exploration and Reasoning
Nov 23, 2024



Constructing compact and informative 3D scene representations is essential for effective embodied exploration and reasoning, especially in complex environments over long periods. Existing scene representations, such as object-centric 3D scene graphs, have significant limitations. They oversimplify spatial relationships by modeling scenes as individual objects, with inter-object relationships described by restrictive texts, making it difficult to answer queries that require nuanced spatial understanding. Furthermore, these representations lack natural mechanisms for active exploration and memory management, which hampers their application to lifelong autonomy. In this work, we propose SnapMem, a novel snapshot-based scene representation serving as 3D scene memory for embodied agents. SnapMem employs informative images, termed Memory Snapshots, to capture rich visual information of explored regions. It also integrates frontier-based exploration by introducing Frontier Snapshots-glimpses of unexplored areas-that enable agents to make informed exploration decisions by considering both known and potential new information. Meanwhile, to support lifelong memory in active exploration settings, we further present an incremental construction pipeline for SnapMem, as well as an effective memory retrieval technique for memory management. Experimental results on three benchmarks demonstrate that SnapMem significantly enhances agents' exploration and reasoning capabilities in 3D environments over extended periods, highlighting its potential for advancing applications in embodied AI.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation
Apr 16, 2024In this paper, we investigate the problem of embodied multi-agent cooperation, where decentralized agents must cooperate given only partial egocentric views of the world. To effectively plan in this setting, in contrast to learning world dynamics in a single-agent scenario, we must simulate world dynamics conditioned on an arbitrary number of agents' actions given only partial egocentric visual observations of the world. To address this issue of partial observability, we first train generative models to estimate the overall world state given partial egocentric observations. To enable accurate simulation of multiple sets of actions on this world state, we then propose to learn a compositional world model for multi-agent cooperation by factorizing the naturally composable joint actions of multiple agents and compositionally generating the video. By leveraging this compositional world model, in combination with Vision Language Models to infer the actions of other agents, we can use a tree search procedure to integrate these modules and facilitate online cooperative planning. To evaluate the efficacy of our methods, we create two challenging embodied multi-agent long-horizon cooperation tasks using the ThreeDWorld simulator and conduct experiments with 2-4 agents. The results show our compositional world model is effective and the framework enables the embodied agents to cooperate efficiently with different agents across various tasks and an arbitrary number of agents, showing the promising future of our proposed framework. More videos can be found at https://vis-www.cs.umass.edu/combo/.
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
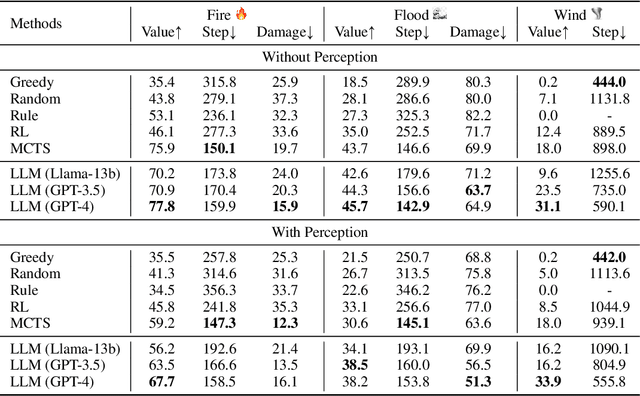

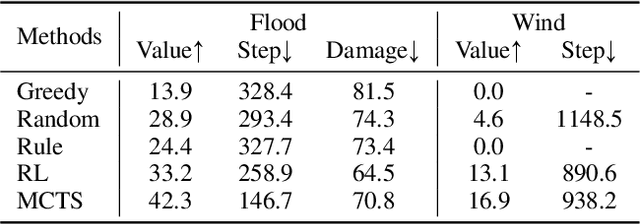
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.
SALMON: Self-Alignment with Principle-Following Reward Models
Oct 09, 2023



Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON (Self-ALignMent with principle-fOllowiNg reward models), to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is a principle-following reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the reward model, subsequently influencing the behavior of the RL-trained policies, and eliminating the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.