 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

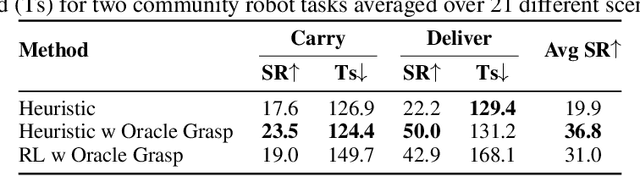

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
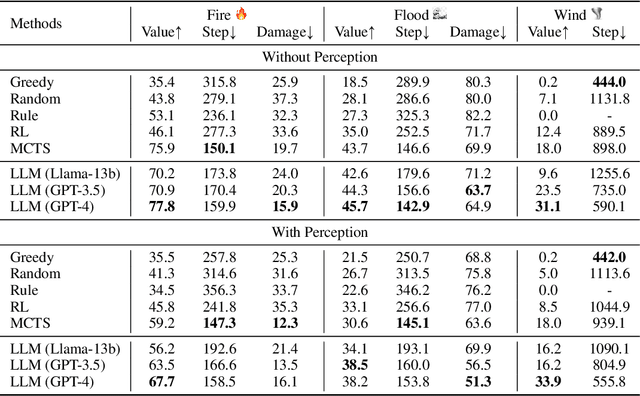

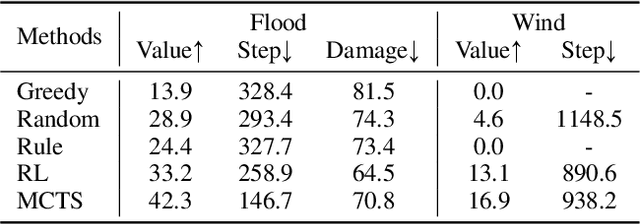
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.
SALMON: Self-Alignment with Principle-Following Reward Models
Oct 09, 2023



Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON (Self-ALignMent with principle-fOllowiNg reward models), to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is a principle-following reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the reward model, subsequently influencing the behavior of the RL-trained policies, and eliminating the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.
Building Cooperative Embodied Agents Modularly with Large Language Models
Jul 05, 2023Large Language Models (LLMs) have demonstrated impressive planning abilities in single-agent embodied tasks across various domains. However, their capacity for planning and communication in multi-agent cooperation remains unclear, even though these are crucial skills for intelligent embodied agents. In this paper, we present a novel framework that utilizes LLMs for multi-agent cooperation and tests it in various embodied environments. Our framework enables embodied agents to plan, communicate, and cooperate with other embodied agents or humans to accomplish long-horizon tasks efficiently. We demonstrate that recent LLMs, such as GPT-4, can surpass strong planning-based methods and exhibit emergent effective communication using our framework without requiring fine-tuning or few-shot prompting. We also discover that LLM-based agents that communicate in natural language can earn more trust and cooperate more effectively with humans. Our research underscores the potential of LLMs for embodied AI and lays the foundation for future research in multi-agent cooperation. Videos can be found on the project website https://vis-www.cs.umass.edu/Co-LLM-Agents/.
Bridging the Gap between Decision and Logits in Decision-based Knowledge Distillation for Pre-trained Language Models
Jun 15, 2023Conventional knowledge distillation (KD) methods require access to the internal information of teachers, e.g., logits. However, such information may not always be accessible for large pre-trained language models (PLMs). In this work, we focus on decision-based KD for PLMs, where only teacher decisions (i.e., top-1 labels) are accessible. Considering the information gap between logits and decisions, we propose a novel method to estimate logits from the decision distributions. Specifically, decision distributions can be both derived as a function of logits theoretically and estimated with test-time data augmentation empirically. By combining the theoretical and empirical estimations of the decision distributions together, the estimation of logits can be successfully reduced to a simple root-finding problem. Extensive experiments show that our method significantly outperforms strong baselines on both natural language understanding and machine reading comprehension datasets.
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
May 04, 2023



Recent AI-assistant agents, such as ChatGPT, predominantly rely on supervised fine-tuning (SFT) with human annotations and reinforcement learning from human feedback (RLHF) to align the output of large language models (LLMs) with human intentions, ensuring they are helpful, ethical, and reliable. However, this dependence can significantly constrain the true potential of AI-assistant agents due to the high cost of obtaining human supervision and the related issues on quality, reliability, diversity, self-consistency, and undesirable biases. To address these challenges, we propose a novel approach called SELF-ALIGN, which combines principle-driven reasoning and the generative power of LLMs for the self-alignment of AI agents with minimal human supervision. Our approach encompasses four stages: first, we use an LLM to generate synthetic prompts, and a topic-guided method to augment the prompt diversity; second, we use a small set of human-written principles for AI models to follow, and guide the LLM through in-context learning from demonstrations (of principles application) to produce helpful, ethical, and reliable responses to user's queries; third, we fine-tune the original LLM with the high-quality self-aligned responses so that the resulting model can generate desirable responses for each query directly without the principle set and the demonstrations anymore; and finally, we offer a refinement step to address the issues of overly-brief or indirect responses. Applying SELF-ALIGN to the LLaMA-65b base language model, we develop an AI assistant named Dromedary. With fewer than 300 lines of human annotations (including < 200 seed prompts, 16 generic principles, and 5 exemplars for in-context learning). Dromedary significantly surpasses the performance of several state-of-the-art AI systems, including Text-Davinci-003 and Alpaca, on benchmark datasets with various settings.
See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge-based Visual Reasoning
Jan 12, 2023Large pre-trained vision and language models have demonstrated remarkable capacities for various tasks. However, solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect the external world knowledge, and perform step-by-step reasoning to answer the questions correctly. To this end, we propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge-based visual reasoning. IPVR contains three stages, see, think and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend to the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rationale to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. We conduct experiments on a range of knowledge-based visual reasoning datasets. We found our IPVR enjoys several benefits, 1). it achieves better performance than the previous few-shot learning baselines; 2). it enjoys the total transparency and trustworthiness of the whole reasoning process by providing rationales for each reasoning step; 3). it is computation-efficient compared with other fine-tuning baselines.