 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-evolving LLM agents with in-distribution Optimization
Jun 05, 2026Large Language Models (LLMs) have recently emerged as powerful controllers for interactive agents in complex environments, yet training them to perform reliable long-horizon decision making remains a fundamental challenge. A key difficulty lies in credit assignment: agents often receive delayed rewards only at the end of episodes. In this paper, we propose Q-Evolve, a self-evolving framework for LLM agents that unifies automatic process-reward labeling and policy learning within a principled in-distribution reinforcement learning paradigm. In each evolving iteration, our method learns an in-distribution critic from a hybrid off-policy dataset that combines expert demonstrations with agent-generated trajectories, stabilizing Bellman backups in sparse-reward settings via a weighted Implicit Q-Learning objective. The learned value function is then used to derive step-wise process rewards through advantage estimation, enabling dense and reliable supervision without environment backtracking or human annotation. Leveraging these signals, we perform behavior-proximal policy optimization that evolves the agent over the data used for process reward labeling, allowing iterative self-improvement without exacerbating distribution shift. We evaluate our method on AlfWorld, WebShop, and ScienceWorld, showing Q-Evolve outperforms strong baselines in sample efficiency, robustness, and overall task performance. Our results demonstrate that stable agent self-evolution is achievable through the co-evolution of process-level supervision and policy, both grounded within a shared in-distribution learning loop.
VEBench:Benchmarking Large Multimodal Models for Real-World Video Editing
May 05, 2026Real-world video editing demands not only expert knowledge of cinematic techniques but also multimodal reasoning to select, align, and combine footage into coherent narratives. While recent Large Multimodal Models (LMMs) have shown remarkable progress in general video understanding, their abilities in multi-video reasoning and operational editing workflows remain largely unexplored. We introduce VEBENCH, the first comprehensive benchmark designed to evaluate both editing knowledge understanding and operational reasoning in realistic video editing scenarios. VEBENCH contains 3.9K high-quality edited videos (over 257 hours) and 3,080 human-verified QA pairs, built through a three-round human-AI collaborative annotation pipeline that ensures precise temporal labeling and semantic consistency. It features two complementary QA tasks: 1) Video Editing Technique Recognition, assessing models' ability to identify 7 editing techniques using multimodal cues; and 2) Video Editing Operation Simulation, modeling real-world editing workflows by requiring the selection and temporal localization of relevant clips from multiple candidates. Extensive experiments across proprietary (e.g., Gemini-2.5-Pro) and open-source LMMs reveal a large gap between current model performance and human-level editing cognition. These results highlight the urgent need for bridging video understanding with creative operational reasoning. We envision VEBENCH as a foundation for advancing intelligent video editing systems and driving future research on complex reasoning.
Scene-agnostic Pose Regression for Visual Localization
Mar 25, 2025



Absolute Pose Regression (APR) predicts 6D camera poses but lacks the adaptability to unknown environments without retraining, while Relative Pose Regression (RPR) generalizes better yet requires a large image retrieval database. Visual Odometry (VO) generalizes well in unseen environments but suffers from accumulated error in open trajectories. To address this dilemma, we introduce a new task, Scene-agnostic Pose Regression (SPR), which can achieve accurate pose regression in a flexible way while eliminating the need for retraining or databases. To benchmark SPR, we created a large-scale dataset, 360SPR, with over 200K photorealistic panoramas, 3.6M pinhole images and camera poses in 270 scenes at three different sensor heights. Furthermore, a SPR-Mamba model is initially proposed to address SPR in a dual-branch manner. Extensive experiments and studies demonstrate the effectiveness of our SPR paradigm, dataset, and model. In the unknown scenes of both 360SPR and 360Loc datasets, our method consistently outperforms APR, RPR and VO. The dataset and code are available at https://junweizheng93.github.io/publications/SPR/SPR.html.
Scaling Autonomous Agents via Automatic Reward Modeling And Planning
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a range of text-generation tasks. However, LLMs still struggle with problems requiring multi-step decision-making and environmental feedback, such as online shopping, scientific reasoning, and mathematical problem-solving. Unlike pure text data, collecting large-scale decision-making data is challenging. Moreover, many powerful LLMs are only accessible through APIs, which hinders their fine-tuning for agent tasks due to cost and complexity. To address LLM agents' limitations, we propose a framework that can automatically learn a reward model from the environment without human annotations. This model can be used to evaluate the action trajectories of LLM agents and provide heuristics for task planning. Specifically, our approach involves employing one LLM-based agent to navigate an environment randomly, generating diverse action trajectories. Subsequently, a separate LLM is leveraged to assign a task intent and synthesize a negative response alongside the correct response for each trajectory. These triplets (task intent, positive response, and negative response) are then utilized as training data to optimize a reward model capable of scoring action trajectories. The effectiveness and generalizability of our framework are demonstrated through evaluations conducted on different agent benchmarks. In conclusion, our proposed framework represents a significant advancement in enhancing LLM agents' decision-making capabilities. By automating the learning of reward models, we overcome the challenges of data scarcity and API limitations, potentially revolutionizing the application of LLMs in complex and interactive environments. This research paves the way for more sophisticated AI agents capable of tackling a wide range of real-world problems requiring multi-step decision-making.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
Compositional Physical Reasoning of Objects and Events from Videos
Aug 02, 2024Understanding and reasoning about objects' physical properties in the natural world is a fundamental challenge in artificial intelligence. While some properties like colors and shapes can be directly observed, others, such as mass and electric charge, are hidden from the objects' visual appearance. This paper addresses the unique challenge of inferring these hidden physical properties from objects' motion and interactions and predicting corresponding dynamics based on the inferred physical properties. We first introduce the Compositional Physical Reasoning (ComPhy) dataset. For a given set of objects, ComPhy includes limited videos of them moving and interacting under different initial conditions. The model is evaluated based on its capability to unravel the compositional hidden properties, such as mass and charge, and use this knowledge to answer a set of questions. Besides the synthetic videos from simulators, we also collect a real-world dataset to show further test physical reasoning abilities of different models. We evaluate state-of-the-art video reasoning models on ComPhy and reveal their limited ability to capture these hidden properties, which leads to inferior performance. We also propose a novel neuro-symbolic framework, Physical Concept Reasoner (PCR), that learns and reasons about both visible and hidden physical properties from question answering. After training, PCR demonstrates remarkable capabilities. It can detect and associate objects across frames, ground visible and hidden physical properties, make future and counterfactual predictions, and utilize these extracted representations to answer challenging questions.
FlexAttention for Efficient High-Resolution Vision-Language Models
Jul 29, 2024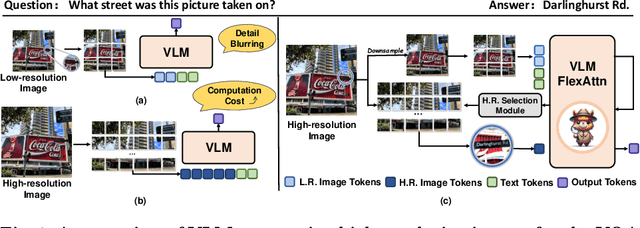
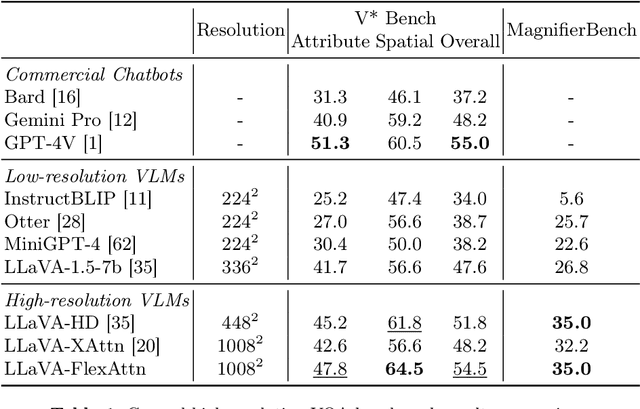
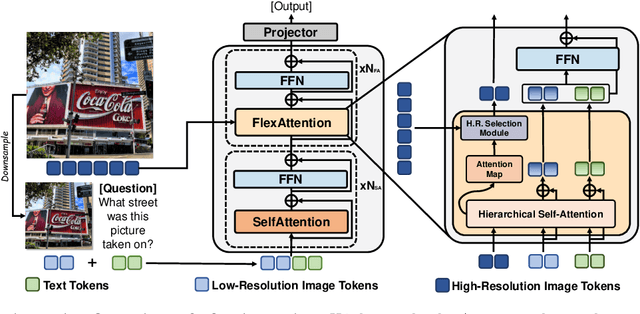
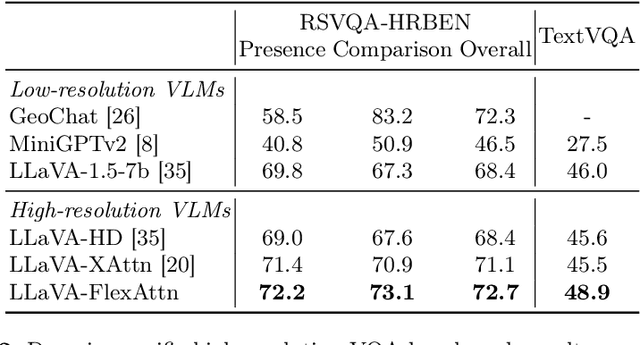
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.
SOK-Bench: A Situated Video Reasoning Benchmark with Aligned Open-World Knowledge
May 17, 2024



Learning commonsense reasoning from visual contexts and scenes in real-world is a crucial step toward advanced artificial intelligence. However, existing video reasoning benchmarks are still inadequate since they were mainly designed for factual or situated reasoning and rarely involve broader knowledge in the real world. Our work aims to delve deeper into reasoning evaluations, specifically within dynamic, open-world, and structured context knowledge. We propose a new benchmark (SOK-Bench), consisting of 44K questions and 10K situations with instance-level annotations depicted in the videos. The reasoning process is required to understand and apply situated knowledge and general knowledge for problem-solving. To create such a dataset, we propose an automatic and scalable generation method to generate question-answer pairs, knowledge graphs, and rationales by instructing the combinations of LLMs and MLLMs. Concretely, we first extract observable situated entities, relations, and processes from videos for situated knowledge and then extend to open-world knowledge beyond the visible content. The task generation is facilitated through multiple dialogues as iterations and subsequently corrected and refined by our designed self-promptings and demonstrations. With a corpus of both explicit situated facts and implicit commonsense, we generate associated question-answer pairs and reasoning processes, finally followed by manual reviews for quality assurance. We evaluated recent mainstream large vision-language models on the benchmark and found several insightful conclusions. For more information, please refer to our benchmark at www.bobbywu.com/SOKBench.
STAR: A Benchmark for Situated Reasoning in Real-World Videos
May 15, 2024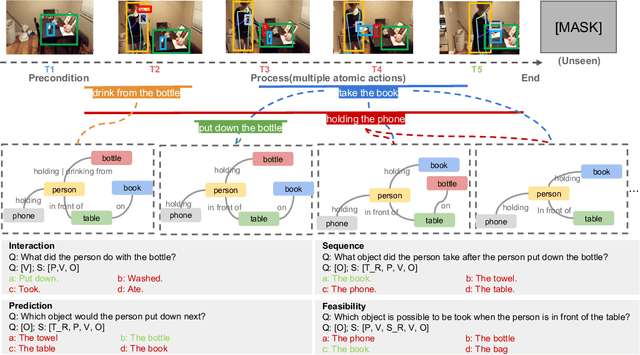
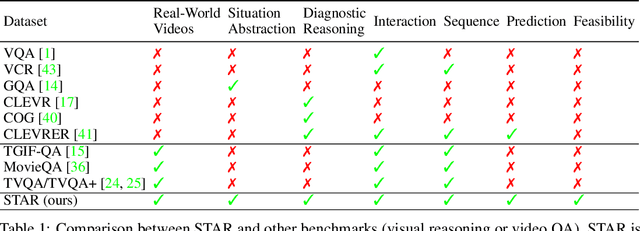
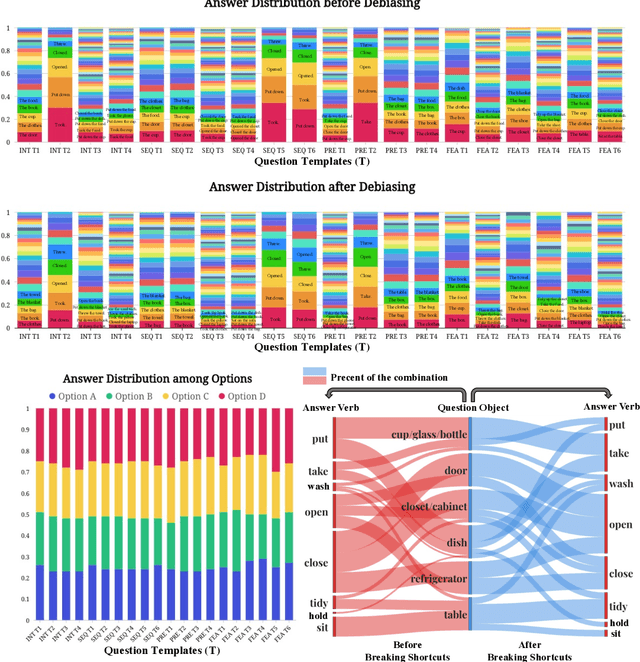
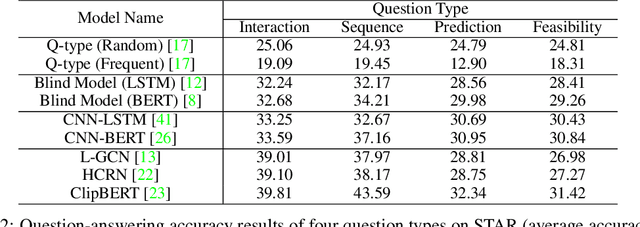
Reasoning in the real world is not divorced from situations. How to capture the present knowledge from surrounding situations and perform reasoning accordingly is crucial and challenging for machine intelligence. This paper introduces a new benchmark that evaluates the situated reasoning ability via situation abstraction and logic-grounded question answering for real-world videos, called Situated Reasoning in Real-World Videos (STAR Benchmark). This benchmark is built upon the real-world videos associated with human actions or interactions, which are naturally dynamic, compositional, and logical. The dataset includes four types of questions, including interaction, sequence, prediction, and feasibility. We represent the situations in real-world videos by hyper-graphs connecting extracted atomic entities and relations (e.g., actions, persons, objects, and relationships). Besides visual perception, situated reasoning also requires structured situation comprehension and logical reasoning. Questions and answers are procedurally generated. The answering logic of each question is represented by a functional program based on a situation hyper-graph. We compare various existing video reasoning models and find that they all struggle on this challenging situated reasoning task. We further propose a diagnostic neuro-symbolic model that can disentangle visual perception, situation abstraction, language understanding, and functional reasoning to understand the challenges of this benchmark.
ContPhy: Continuum Physical Concept Learning and Reasoning from Videos
Feb 09, 2024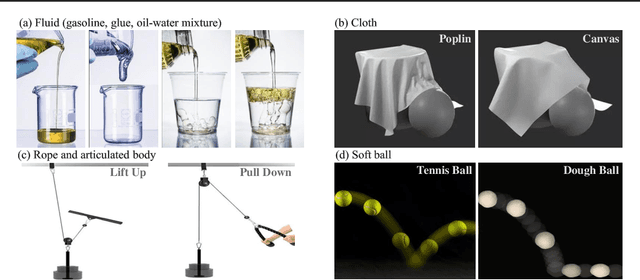
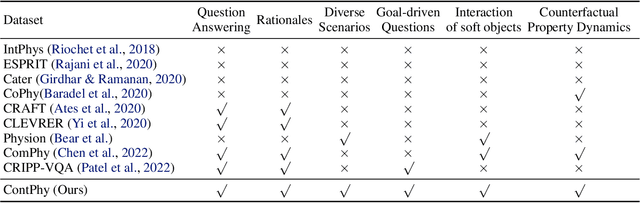
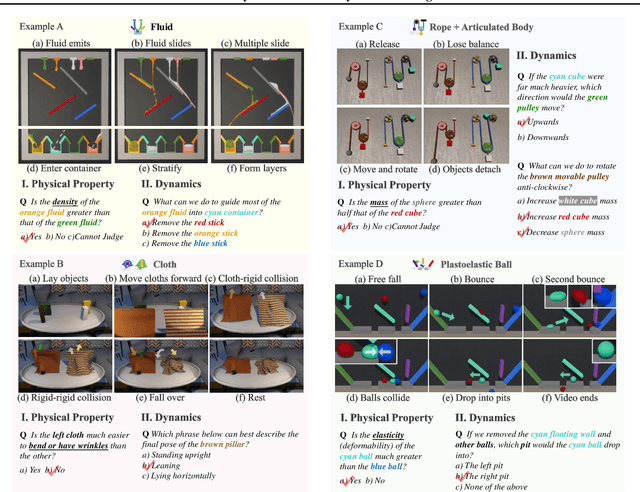
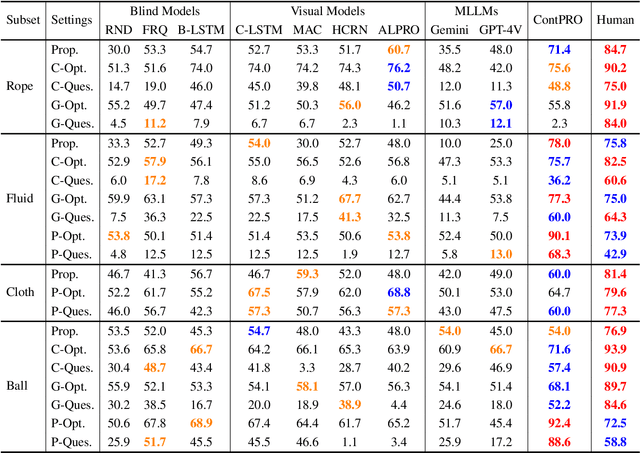
We introduce the Continuum Physical Dataset (ContPhy), a novel benchmark for assessing machine physical commonsense. ContPhy complements existing physical reasoning benchmarks by encompassing the inference of diverse physical properties, such as mass and density, across various scenarios and predicting corresponding dynamics. We evaluated a range of AI models and found that they still struggle to achieve satisfactory performance on ContPhy, which shows that the current AI models still lack physical commonsense for the continuum, especially soft-bodies, and illustrates the value of the proposed dataset. We also introduce an oracle model (ContPRO) that marries the particle-based physical dynamic models with the recent large language models, which enjoy the advantages of both models, precise dynamic predictions, and interpretable reasoning. ContPhy aims to spur progress in perception and reasoning within diverse physical settings, narrowing the divide between human and machine intelligence in understanding the physical world. Project page: https://physical-reasoning-project.github.io.