 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSonic: Training-Free Temporal-Aware Decoupled Attention for Precise Audio Editing
Jun 13, 2026Text-to-audio (TTA) generation has made significant strides, yet achieving precise and consistent audio editing remains a major challenge. However, existing methods struggle to balance temporal consistency with background preservation. In this paper, we propose FreeSonic, a training-free framework leveraging the state-of-the-art Rectified Flow-based TangoFlux model. FreeSonic utilizes an optimized inversion-reverse process and joint text-audio attention maps for precise target segment extraction. For content editing, a novel scheduled attention decoupling confines modifications to target regions while preserving original acoustic context. Furthermore, task-oriented noise injection enhances versatility for tasks such as audio removal and non-rigid replacement. Extensive experimental results demonstrate that FreeSonic achieves a superior balance by providing a high-fidelity and efficient solution for precise and consistent audio editing. Project and demos: https://free-sonic.github.io/
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Follow-Your-Pose v2: Multiple-Condition Guided Character Image Animation for Stable Pose Control
Jun 05, 2024



Pose-controllable character video generation is in high demand with extensive applications for fields such as automatic advertising and content creation on social media platforms. While existing character image animation methods using pose sequences and reference images have shown promising performance, they tend to struggle with incoherent animation in complex scenarios, such as multiple character animation and body occlusion. Additionally, current methods request large-scale high-quality videos with stable backgrounds and temporal consistency as training datasets, otherwise, their performance will greatly deteriorate. These two issues hinder the practical utilization of character image animation tools. In this paper, we propose a practical and robust framework Follow-Your-Pose v2, which can be trained on noisy open-sourced videos readily available on the internet. Multi-condition guiders are designed to address the challenges of background stability, body occlusion in multi-character generation, and consistency of character appearance. Moreover, to fill the gap of fair evaluation of multi-character pose animation, we propose a new benchmark comprising approximately 4,000 frames. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a margin of over 35\% across 2 datasets and on 7 metrics. Meanwhile, qualitative assessments reveal a significant improvement in the quality of generated video, particularly in scenarios involving complex backgrounds and body occlusion of multi-character, suggesting the superiority of our approach.
SOK-Bench: A Situated Video Reasoning Benchmark with Aligned Open-World Knowledge
May 17, 2024



Learning commonsense reasoning from visual contexts and scenes in real-world is a crucial step toward advanced artificial intelligence. However, existing video reasoning benchmarks are still inadequate since they were mainly designed for factual or situated reasoning and rarely involve broader knowledge in the real world. Our work aims to delve deeper into reasoning evaluations, specifically within dynamic, open-world, and structured context knowledge. We propose a new benchmark (SOK-Bench), consisting of 44K questions and 10K situations with instance-level annotations depicted in the videos. The reasoning process is required to understand and apply situated knowledge and general knowledge for problem-solving. To create such a dataset, we propose an automatic and scalable generation method to generate question-answer pairs, knowledge graphs, and rationales by instructing the combinations of LLMs and MLLMs. Concretely, we first extract observable situated entities, relations, and processes from videos for situated knowledge and then extend to open-world knowledge beyond the visible content. The task generation is facilitated through multiple dialogues as iterations and subsequently corrected and refined by our designed self-promptings and demonstrations. With a corpus of both explicit situated facts and implicit commonsense, we generate associated question-answer pairs and reasoning processes, finally followed by manual reviews for quality assurance. We evaluated recent mainstream large vision-language models on the benchmark and found several insightful conclusions. For more information, please refer to our benchmark at www.bobbywu.com/SOKBench.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024



Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
Transformed Low-Rank Parameterization Can Help Robust Generalization for Tensor Neural Networks
Mar 01, 2023
Achieving efficient and robust multi-channel data learning is a challenging task in data science. By exploiting low-rankness in the transformed domain, i.e., transformed low-rankness, tensor Singular Value Decomposition (t-SVD) has achieved extensive success in multi-channel data representation and has recently been extended to function representation such as Neural Networks with t-product layers (t-NNs). However, it still remains unclear how t-SVD theoretically affects the learning behavior of t-NNs. This paper is the first to answer this question by deriving the upper bounds of the generalization error of both standard and adversarially trained t-NNs. It reveals that the t-NNs compressed by exact transformed low-rank parameterization can achieve a sharper adversarial generalization bound. In practice, although t-NNs rarely have exactly transformed low-rank weights, our analysis further shows that by adversarial training with gradient flow (GF), the over-parameterized t-NNs with ReLU activations are trained with implicit regularization towards transformed low-rank parameterization under certain conditions. We also establish adversarial generalization bounds for t-NNs with approximately transformed low-rank weights. Our analysis indicates that the transformed low-rank parameterization can promisingly enhance robust generalization for t-NNs.
Exploring Concept Contribution Spatially: Hidden Layer Interpretation with Spatial Activation Concept Vector
May 21, 2022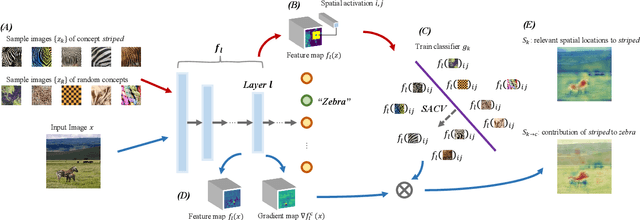

To interpret deep learning models, one mainstream is to explore the learned concepts by networks. Testing with Concept Activation Vector (TCAV) presents a powerful tool to quantify the contribution of query concepts (represented by user-defined guidance images) to a target class. For example, we can quantitatively evaluate whether and to what extent concept striped contributes to model prediction zebra with TCAV. Therefore, TCAV whitens the reasoning process of deep networks. And it has been applied to solve practical problems such as diagnosis. However, for some images where the target object only occupies a small fraction of the region, TCAV evaluation may be interfered with by redundant background features because TCAV calculates concept contribution to a target class based on a whole hidden layer. To tackle this problem, based on TCAV, we propose Spatial Activation Concept Vector (SACV) which identifies the relevant spatial locations to the query concept while evaluating their contributions to the model prediction of the target class. Experiment shows that SACV generates a more fine-grained explanation map for a hidden layer and quantifies concepts' contributions spatially. Moreover, it avoids interference from background features. The code is available on https://github.com/AntonotnaWang/Spatial-Activation-Concept-Vector.
HINT: Hierarchical Neuron Concept Explainer
Mar 27, 2022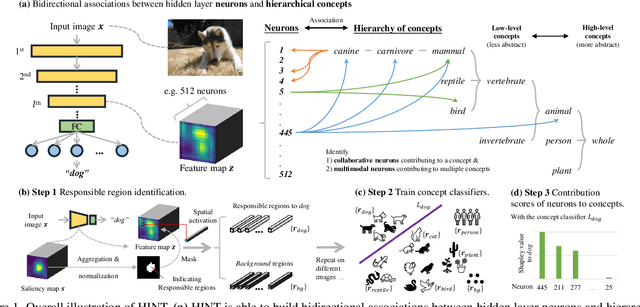
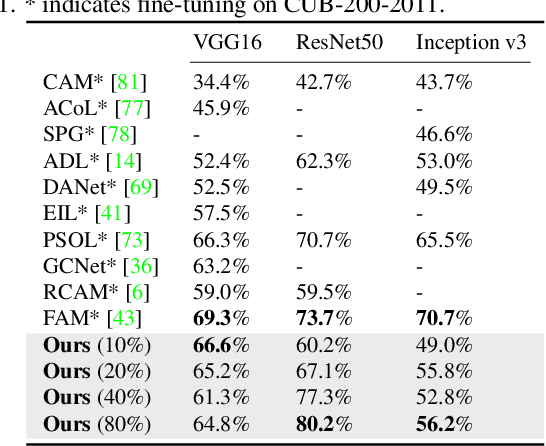

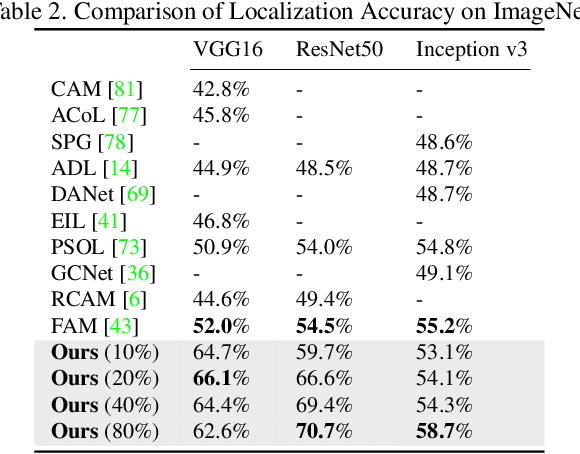
To interpret deep networks, one main approach is to associate neurons with human-understandable concepts. However, existing methods often ignore the inherent relationships of different concepts (e.g., dog and cat both belong to animals), and thus lose the chance to explain neurons responsible for higher-level concepts (e.g., animal). In this paper, we study hierarchical concepts inspired by the hierarchical cognition process of human beings. To this end, we propose HIerarchical Neuron concepT explainer (HINT) to effectively build bidirectional associations between neurons and hierarchical concepts in a low-cost and scalable manner. HINT enables us to systematically and quantitatively study whether and how the implicit hierarchical relationships of concepts are embedded into neurons, such as identifying collaborative neurons responsible to one concept and multimodal neurons for different concepts, at different semantic levels from concrete concepts (e.g., dog) to more abstract ones (e.g., animal). Finally, we verify the faithfulness of the associations using Weakly Supervised Object Localization, and demonstrate its applicability in various tasks such as discovering saliency regions and explaining adversarial attacks. Code is available on https://github.com/AntonotnaWang/HINT.
NaviAirway: a bronchiole-sensitive deep learning-based airway segmentation pipeline for planning of navigation bronchoscopy
Mar 08, 2022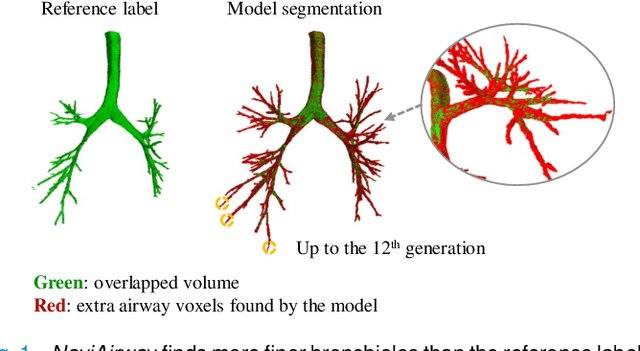

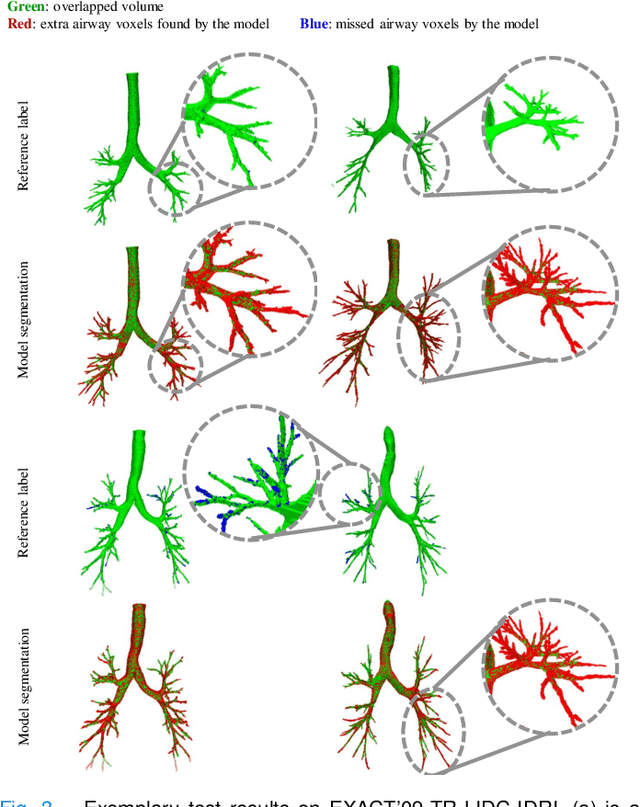
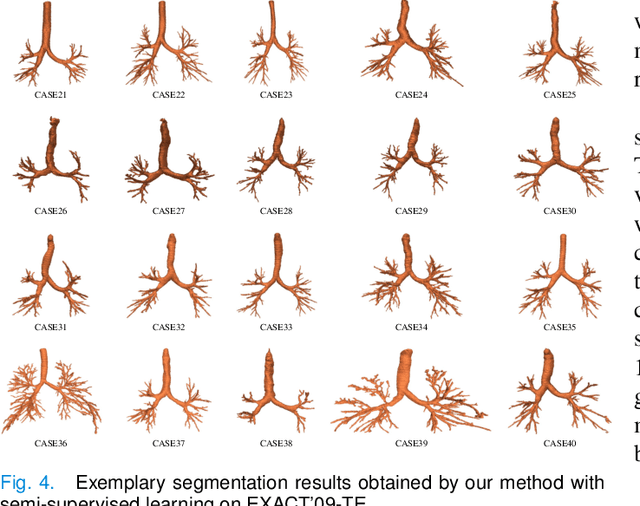
Navigation bronchoscopy is a minimally invasive procedure in which doctors pass a bronchoscope into a subject's airways to sample the target pulmonary lesion. A three-dimensional (3D) airway roadmap reconstructed from Computer Tomography (CT) scans is a prerequisite for this procedure, especially when the target is distally located. Therefore, an accurate and efficient airway segmentation algorithm is essential to reduce bronchoscopists' burden of pre-procedural airway identification as well as patients' discomfort during the prolonged procedure. However, airway segmentation remains a challenging task because of the intrinsic complex tree-like structure, imbalanced sizes of airway branches, potential domain shifts of CT scans, and few available labeled images. To address these problems, we present a deep learning-based pipeline, denoted as NaviAirway, which finds finer bronchioles through four major novel components - feature extractor modules in model architecture design, a bronchiole-sensitive loss function, a human-vision-inspired iterative training strategy, and a semi-supervised learning framework to utilize unlabeled CT images. Experimental results showed that NaviAirway outperformed existing methods, particularly in identification of higher generation bronchioles and robustness to new CT scans. On average, NaviAirway takes five minutes to segment the CT scans of one patient on a GPU-embedded computer. Moreover, we propose two new metrics to complement conventional ones for a more comprehensive and fairer evaluation of deep learning-based airway segmentation approaches. The code is publicly available on https://github.com/AntonotnaWang/NaviAirway.
Semantic-Sparse Colorization Network for Deep Exemplar-based Colorization
Dec 02, 2021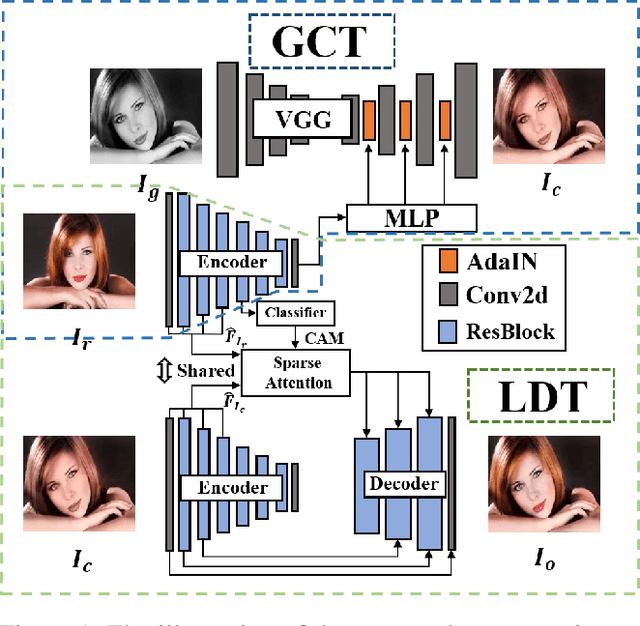
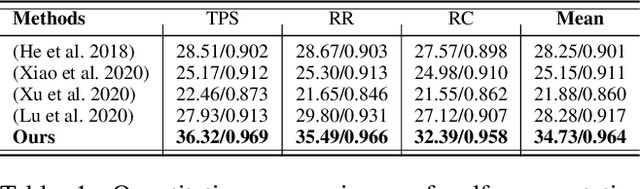
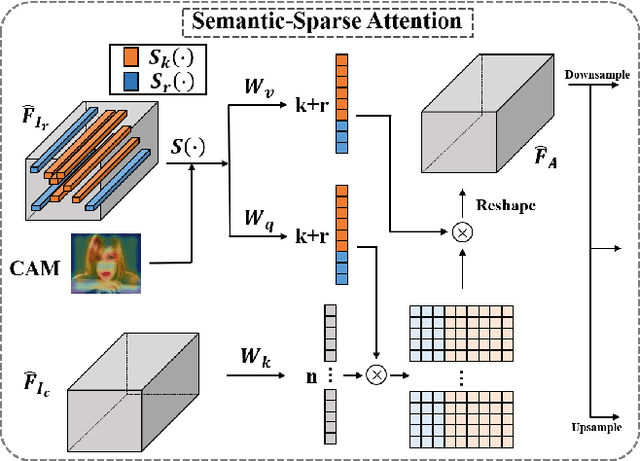
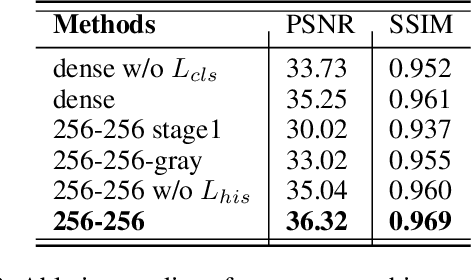
Exemplar-based colorization approaches rely on reference image to provide plausible colors for target gray-scale image. The key and difficulty of exemplar-based colorization is to establish an accurate correspondence between these two images. Previous approaches have attempted to construct such a correspondence but are faced with two obstacles. First, using luminance channels for the calculation of correspondence is inaccurate. Second, the dense correspondence they built introduces wrong matching results and increases the computation burden. To address these two problems, we propose Semantic-Sparse Colorization Network (SSCN) to transfer both the global image style and detailed semantic-related colors to the gray-scale image in a coarse-to-fine manner. Our network can perfectly balance the global and local colors while alleviating the ambiguous matching problem. Experiments show that our method outperforms existing methods in both quantitative and qualitative evaluation and achieves state-of-the-art performance.