 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
Follow-Your-Emoji: Fine-Controllable and Expressive Freestyle Portrait Animation
Jun 04, 2024



We present Follow-Your-Emoji, a diffusion-based framework for portrait animation, which animates a reference portrait with target landmark sequences. The main challenge of portrait animation is to preserve the identity of the reference portrait and transfer the target expression to this portrait while maintaining temporal consistency and fidelity. To address these challenges, Follow-Your-Emoji equipped the powerful Stable Diffusion model with two well-designed technologies. Specifically, we first adopt a new explicit motion signal, namely expression-aware landmark, to guide the animation process. We discover this landmark can not only ensure the accurate motion alignment between the reference portrait and target motion during inference but also increase the ability to portray exaggerated expressions (i.e., large pupil movements) and avoid identity leakage. Then, we propose a facial fine-grained loss to improve the model's ability of subtle expression perception and reference portrait appearance reconstruction by using both expression and facial masks. Accordingly, our method demonstrates significant performance in controlling the expression of freestyle portraits, including real humans, cartoons, sculptures, and even animals. By leveraging a simple and effective progressive generation strategy, we extend our model to stable long-term animation, thus increasing its potential application value. To address the lack of a benchmark for this field, we introduce EmojiBench, a comprehensive benchmark comprising diverse portrait images, driving videos, and landmarks. We show extensive evaluations on EmojiBench to verify the superiority of Follow-Your-Emoji.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024



Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
Robustness-Guided Image Synthesis for Data-Free Quantization
Oct 05, 2023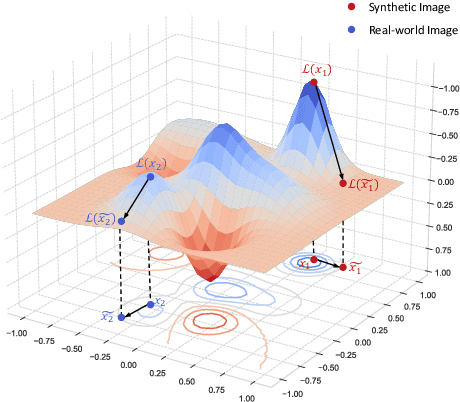
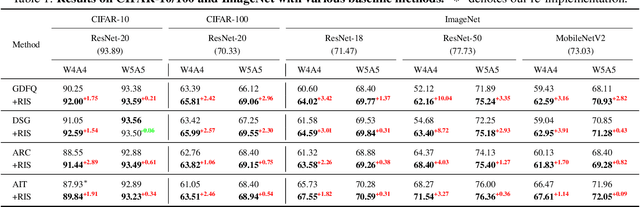
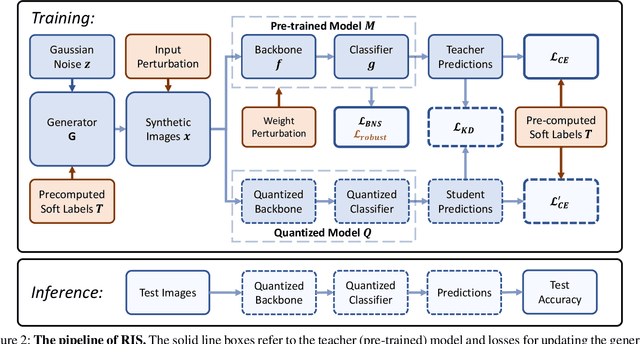
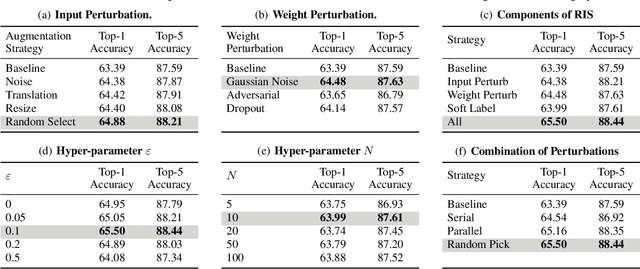
Quantization has emerged as a promising direction for model compression. Recently, data-free quantization has been widely studied as a promising method to avoid privacy concerns, which synthesizes images as an alternative to real training data. Existing methods use classification loss to ensure the reliability of the synthesized images. Unfortunately, even if these images are well-classified by the pre-trained model, they still suffer from low semantics and homogenization issues. Intuitively, these low-semantic images are sensitive to perturbations, and the pre-trained model tends to have inconsistent output when the generator synthesizes an image with poor semantics. To this end, we propose Robustness-Guided Image Synthesis (RIS), a simple but effective method to enrich the semantics of synthetic images and improve image diversity, further boosting the performance of downstream data-free compression tasks. Concretely, we first introduce perturbations on input and model weight, then define the inconsistency metrics at feature and prediction levels before and after perturbations. On the basis of inconsistency on two levels, we design a robustness optimization objective to enhance the semantics of synthetic images. Moreover, we also make our approach diversity-aware by forcing the generator to synthesize images with small correlations in the label space. With RIS, we achieve state-of-the-art performance for various settings on data-free quantization and can be extended to other data-free compression tasks.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023
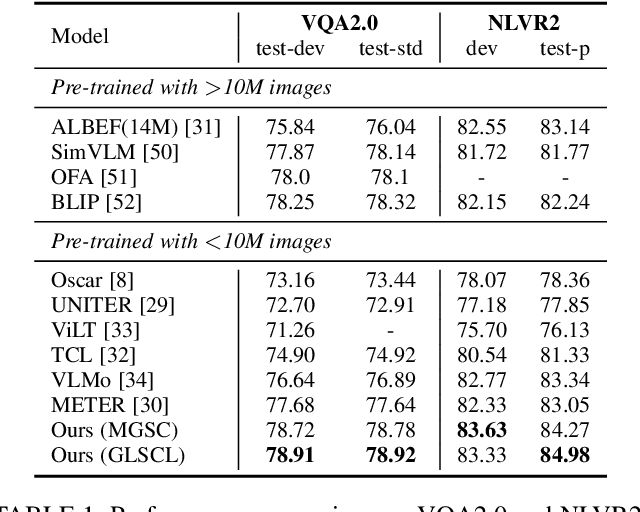
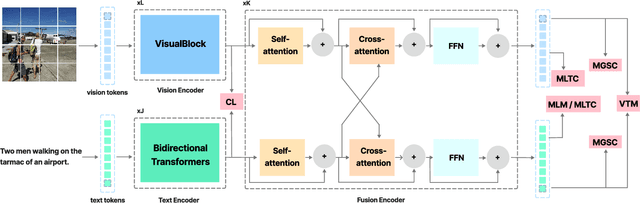
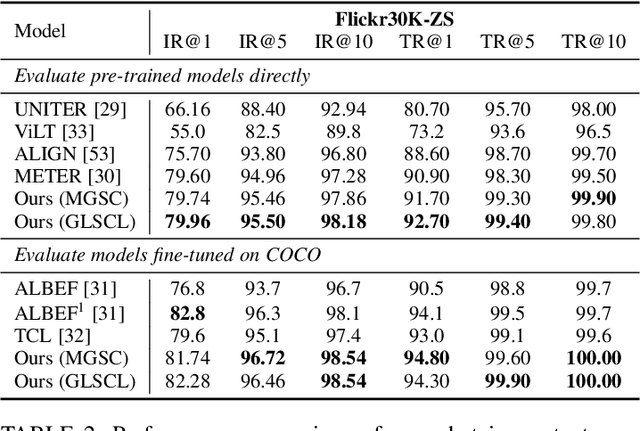
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Unsupervised Hashing with Semantic Concept Mining
Sep 23, 2022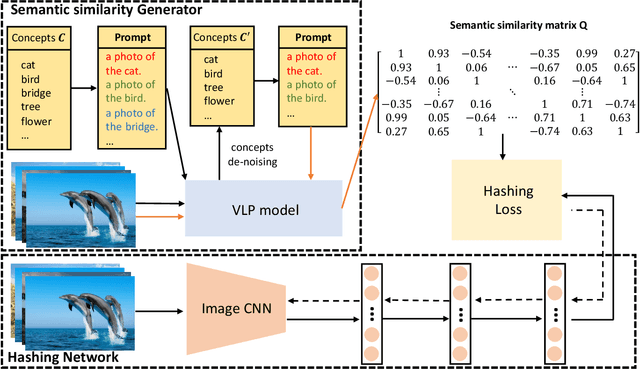


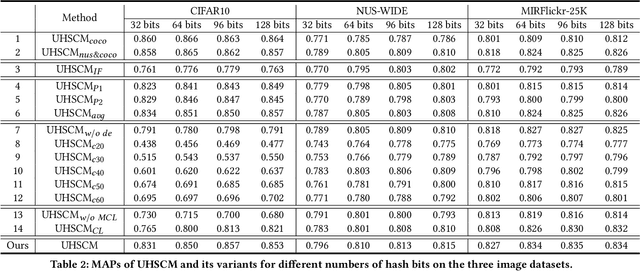
Recently, to improve the unsupervised image retrieval performance, plenty of unsupervised hashing methods have been proposed by designing a semantic similarity matrix, which is based on the similarities between image features extracted by a pre-trained CNN model. However, most of these methods tend to ignore high-level abstract semantic concepts contained in images. Intuitively, concepts play an important role in calculating the similarity among images. In real-world scenarios, each image is associated with some concepts, and the similarity between two images will be larger if they share more identical concepts. Inspired by the above intuition, in this work, we propose a novel Unsupervised Hashing with Semantic Concept Mining, called UHSCM, which leverages a VLP model to construct a high-quality similarity matrix. Specifically, a set of randomly chosen concepts is first collected. Then, by employing a vision-language pretraining (VLP) model with the prompt engineering which has shown strong power in visual representation learning, the set of concepts is denoised according to the training images. Next, the proposed method UHSCM applies the VLP model with prompting again to mine the concept distribution of each image and construct a high-quality semantic similarity matrix based on the mined concept distributions. Finally, with the semantic similarity matrix as guiding information, a novel hashing loss with a modified contrastive loss based regularization item is proposed to optimize the hashing network. Extensive experiments on three benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022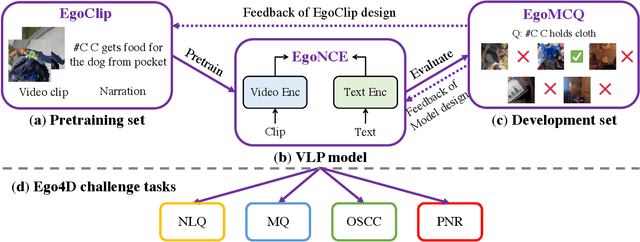
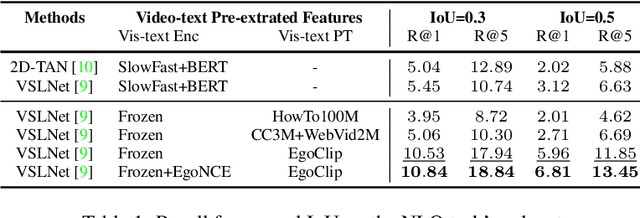
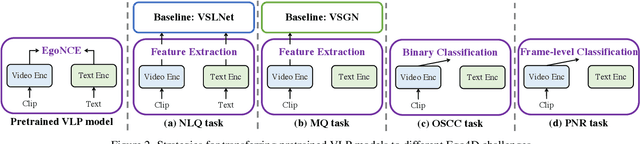
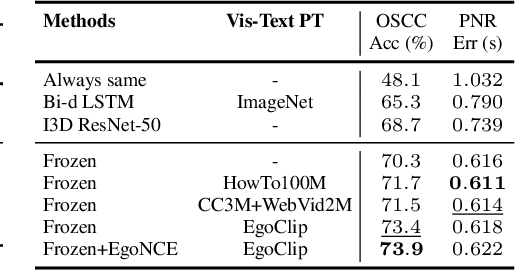
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining @ EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jul 04, 2022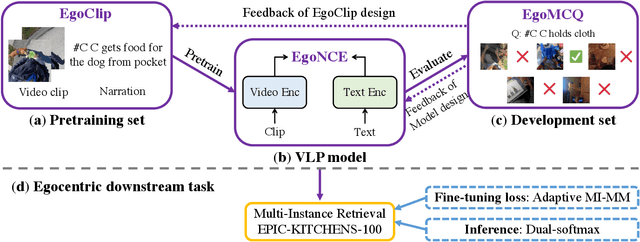
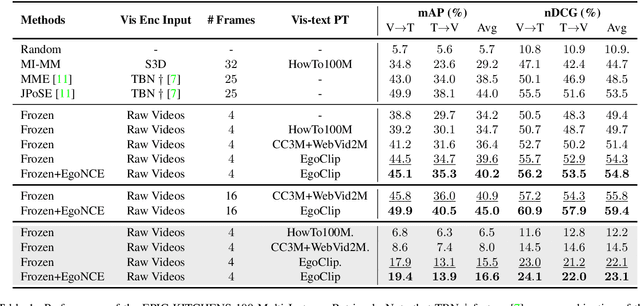
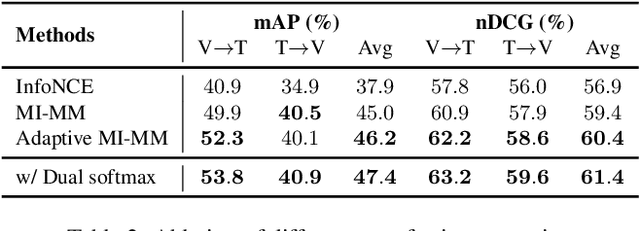
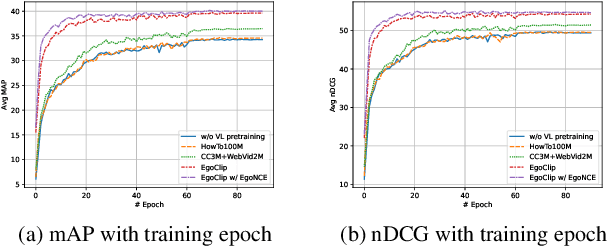
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for the EPIC-KITCHENS-100 Multi-Instance Retrieval (MIR) challenge. Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation to MIR benchmark. Furthermore, we devise an adaptive multi-instance max-margin loss to effectively fine-tune the model and equip the dual-softmax technique for reliable inference. Our best single model obtains strong performance on the challenge test set with 47.39% mAP and 61.44% nDCG. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining
Jun 03, 2022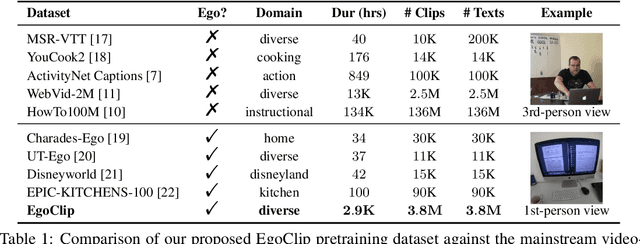
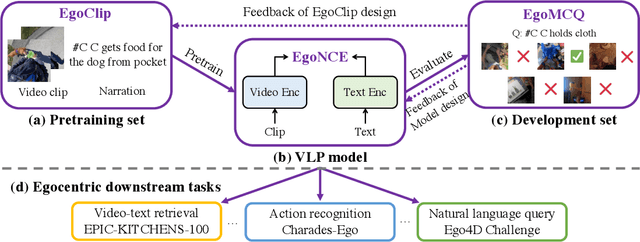

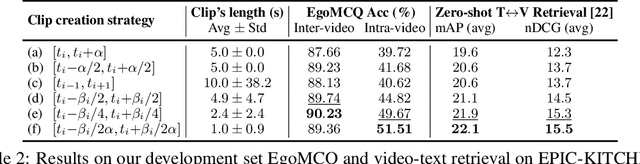
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.