 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVid: A Multimodal Emotion Video Dataset for Emotion-Centric Video Understanding and Generation
Nov 14, 2025



Emotion plays a pivotal role in video-based expression, but existing video generation systems predominantly focus on low-level visual metrics while neglecting affective dimensions. Although emotion analysis has made progress in the visual domain, the video community lacks dedicated resources to bridge emotion understanding with generative tasks, particularly for stylized and non-realistic contexts. To address this gap, we introduce EmoVid, the first multimodal, emotion-annotated video dataset specifically designed for creative media, which includes cartoon animations, movie clips, and animated stickers. Each video is annotated with emotion labels, visual attributes (brightness, colorfulness, hue), and text captions. Through systematic analysis, we uncover spatial and temporal patterns linking visual features to emotional perceptions across diverse video forms. Building on these insights, we develop an emotion-conditioned video generation technique by fine-tuning the Wan2.1 model. The results show a significant improvement in both quantitative metrics and the visual quality of generated videos for text-to-video and image-to-video tasks. EmoVid establishes a new benchmark for affective video computing. Our work not only offers valuable insights into visual emotion analysis in artistically styled videos, but also provides practical methods for enhancing emotional expression in video generation.
SpA2V: Harnessing Spatial Auditory Cues for Audio-driven Spatially-aware Video Generation
Aug 01, 2025Audio-driven video generation aims to synthesize realistic videos that align with input audio recordings, akin to the human ability to visualize scenes from auditory input. However, existing approaches predominantly focus on exploring semantic information, such as the classes of sounding sources present in the audio, limiting their ability to generate videos with accurate content and spatial composition. In contrast, we humans can not only naturally identify the semantic categories of sounding sources but also determine their deeply encoded spatial attributes, including locations and movement directions. This useful information can be elucidated by considering specific spatial indicators derived from the inherent physical properties of sound, such as loudness or frequency. As prior methods largely ignore this factor, we present SpA2V, the first framework explicitly exploits these spatial auditory cues from audios to generate videos with high semantic and spatial correspondence. SpA2V decomposes the generation process into two stages: 1) Audio-guided Video Planning: We meticulously adapt a state-of-the-art MLLM for a novel task of harnessing spatial and semantic cues from input audio to construct Video Scene Layouts (VSLs). This serves as an intermediate representation to bridge the gap between the audio and video modalities. 2) Layout-grounded Video Generation: We develop an efficient and effective approach to seamlessly integrate VSLs as conditional guidance into pre-trained diffusion models, enabling VSL-grounded video generation in a training-free manner. Extensive experiments demonstrate that SpA2V excels in generating realistic videos with semantic and spatial alignment to the input audios.
ModelGrow: Continual Text-to-Video Pre-training with Model Expansion and Language Understanding Enhancement
Dec 25, 2024Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to "grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow. Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding. For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance. For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts. This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts. Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.
Large Motion Video Autoencoding with Cross-modal Video VAE
Dec 23, 2024



Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression. Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding. First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts. Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression. Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability. Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method. The project website can be found at~\href{https://yzxing87.github.io/vae/}{https://yzxing87.github.io/vae/}.
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation
Dec 18, 2024



Recent progress in generative diffusion models has greatly advanced text-to-video generation. While text-to-video models trained on large-scale, diverse datasets can produce varied outputs, these generations often deviate from user preferences, highlighting the need for preference alignment on pre-trained models. Although Direct Preference Optimization (DPO) has demonstrated significant improvements in language and image generation, we pioneer its adaptation to video diffusion models and propose a VideoDPO pipeline by making several key adjustments. Unlike previous image alignment methods that focus solely on either (i) visual quality or (ii) semantic alignment between text and videos, we comprehensively consider both dimensions and construct a preference score accordingly, which we term the OmniScore. We design a pipeline to automatically collect preference pair data based on the proposed OmniScore and discover that re-weighting these pairs based on the score significantly impacts overall preference alignment. Our experiments demonstrate substantial improvements in both visual quality and semantic alignment, ensuring that no preference aspect is neglected. Code and data will be shared at https://videodpo.github.io/.
HiPrompt: Tuning-free Higher-Resolution Generation with Hierarchical MLLM Prompts
Sep 04, 2024



The potential for higher-resolution image generation using pretrained diffusion models is immense, yet these models often struggle with issues of object repetition and structural artifacts especially when scaling to 4K resolution and higher. We figure out that the problem is caused by that, a single prompt for the generation of multiple scales provides insufficient efficacy. In response, we propose HiPrompt, a new tuning-free solution that tackles the above problems by introducing hierarchical prompts. The hierarchical prompts offer both global and local guidance. Specifically, the global guidance comes from the user input that describes the overall content, while the local guidance utilizes patch-wise descriptions from MLLMs to elaborately guide the regional structure and texture generation. Furthermore, during the inverse denoising process, the generated noise is decomposed into low- and high-frequency spatial components. These components are conditioned on multiple prompt levels, including detailed patch-wise descriptions and broader image-level prompts, facilitating prompt-guided denoising under hierarchical semantic guidance. It further allows the generation to focus more on local spatial regions and ensures the generated images maintain coherent local and global semantics, structures, and textures with high definition. Extensive experiments demonstrate that HiPrompt outperforms state-of-the-art works in higher-resolution image generation, significantly reducing object repetition and enhancing structural quality.
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
Jul 30, 2024



Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
Jun 24, 2024

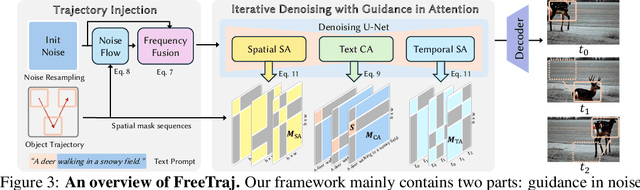
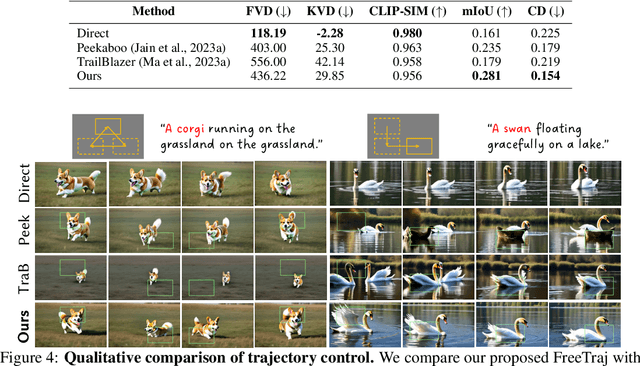
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomenons and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.
Follow-Your-Emoji: Fine-Controllable and Expressive Freestyle Portrait Animation
Jun 04, 2024



We present Follow-Your-Emoji, a diffusion-based framework for portrait animation, which animates a reference portrait with target landmark sequences. The main challenge of portrait animation is to preserve the identity of the reference portrait and transfer the target expression to this portrait while maintaining temporal consistency and fidelity. To address these challenges, Follow-Your-Emoji equipped the powerful Stable Diffusion model with two well-designed technologies. Specifically, we first adopt a new explicit motion signal, namely expression-aware landmark, to guide the animation process. We discover this landmark can not only ensure the accurate motion alignment between the reference portrait and target motion during inference but also increase the ability to portray exaggerated expressions (i.e., large pupil movements) and avoid identity leakage. Then, we propose a facial fine-grained loss to improve the model's ability of subtle expression perception and reference portrait appearance reconstruction by using both expression and facial masks. Accordingly, our method demonstrates significant performance in controlling the expression of freestyle portraits, including real humans, cartoons, sculptures, and even animals. By leveraging a simple and effective progressive generation strategy, we extend our model to stable long-term animation, thus increasing its potential application value. To address the lack of a benchmark for this field, we introduce EmojiBench, a comprehensive benchmark comprising diverse portrait images, driving videos, and landmarks. We show extensive evaluations on EmojiBench to verify the superiority of Follow-Your-Emoji.
LLMs Meet Multimodal Generation and Editing: A Survey
May 29, 2024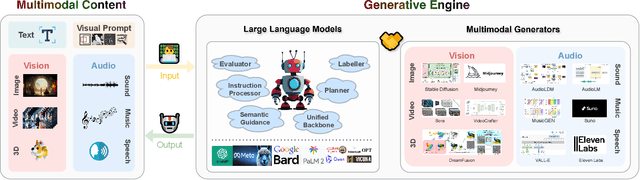
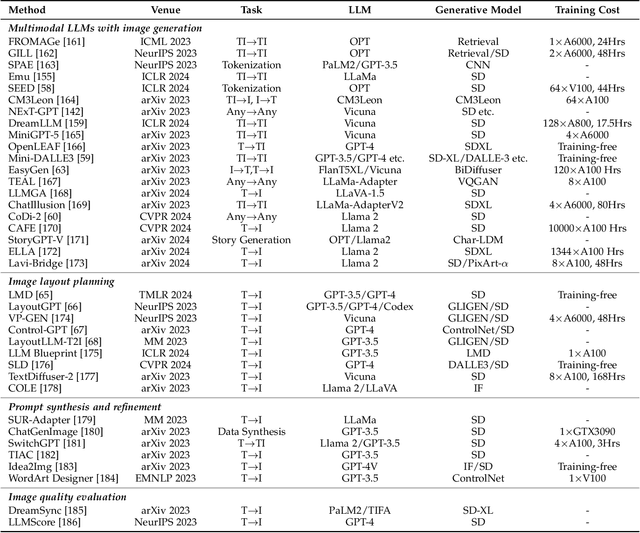
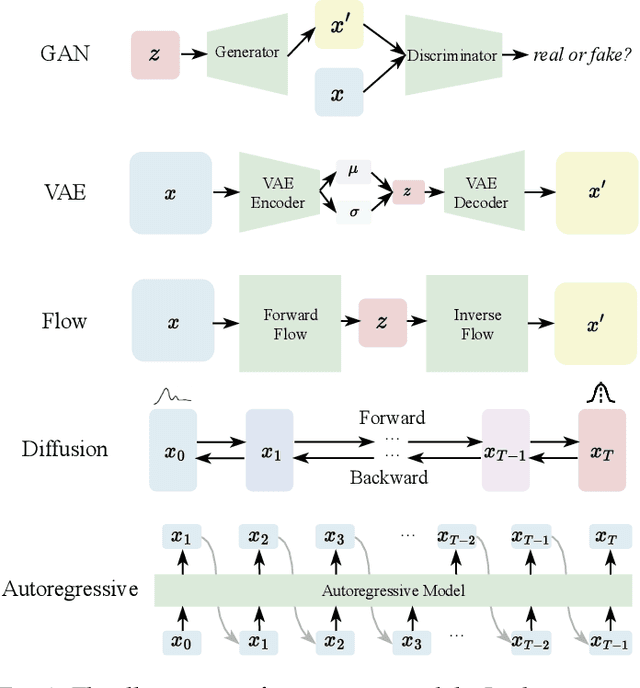
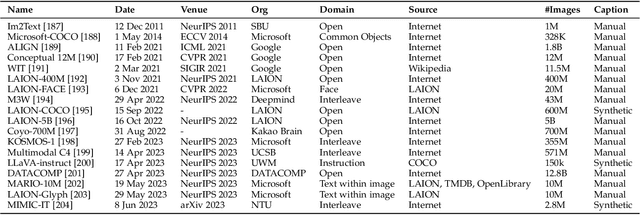
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on understanding. This survey elaborates on multimodal generation across different domains, including image, video, 3D, and audio, where we highlight the notable advancements with milestone works in these fields. Specifically, we exhaustively investigate the key technical components behind methods and multimodal datasets utilized in these studies. Moreover, we dig into tool-augmented multimodal agents that can use existing generative models for human-computer interaction. Lastly, we also comprehensively discuss the advancement in AI safety and investigate emerging applications as well as future prospects. Our work provides a systematic and insightful overview of multimodal generation, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation