 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
May 29, 2026We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
InsEdit: Towards Instruction-based Visual Editing via Data-Efficient Video Diffusion Models Adaptation
Apr 09, 2026Instruction-based video editing is a natural way to control video content with text, but adapting a video generation model into an editor usually appears data-hungry. At the same time, high-quality video editing data remains scarce. In this paper, we show that a video generation backbone can become a strong video editor without large scale video editing data. We present InsEdit, an instruction-based editing model built on HunyuanVideo-1.5. InsEdit combines a visual editing architecture with a video data pipeline based on Mutual Context Attention (MCA), which creates aligned video pairs where edits can begin in the middle of a clip rather than only from the first frame. With only O(100)K video editing data, InsEdit achieves state-of-the-art results among open-source methods on our video instruction editing benchmarks. In addition, because our training recipe also includes image editing data, the final model supports image editing without any modification.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
ModelGrow: Continual Text-to-Video Pre-training with Model Expansion and Language Understanding Enhancement
Dec 25, 2024Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to "grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow. Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding. For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance. For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts. This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts. Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.
ENTED: Enhanced Neural Texture Extraction and Distribution for Reference-based Blind Face Restoration
Jan 13, 2024We present ENTED, a new framework for blind face restoration that aims to restore high-quality and realistic portrait images. Our method involves repairing a single degraded input image using a high-quality reference image. We utilize a texture extraction and distribution framework to transfer high-quality texture features between the degraded input and reference image. However, the StyleGAN-like architecture in our framework requires high-quality latent codes to generate realistic images. The latent code extracted from the degraded input image often contains corrupted features, making it difficult to align the semantic information from the input with the high-quality textures from the reference. To overcome this challenge, we employ two special techniques. The first technique, inspired by vector quantization, replaces corrupted semantic features with high-quality code words. The second technique generates style codes that carry photorealistic texture information from a more informative latent space developed using the high-quality features in the reference image's manifold. Extensive experiments conducted on synthetic and real-world datasets demonstrate that our method produces results with more realistic contextual details and outperforms state-of-the-art methods. A thorough ablation study confirms the effectiveness of each proposed module.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
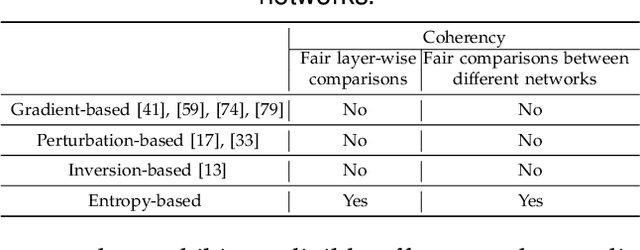
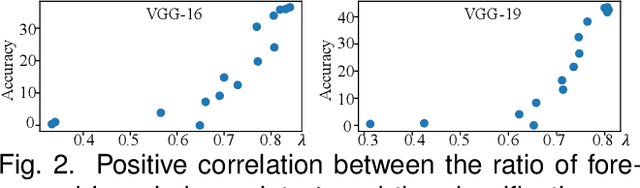
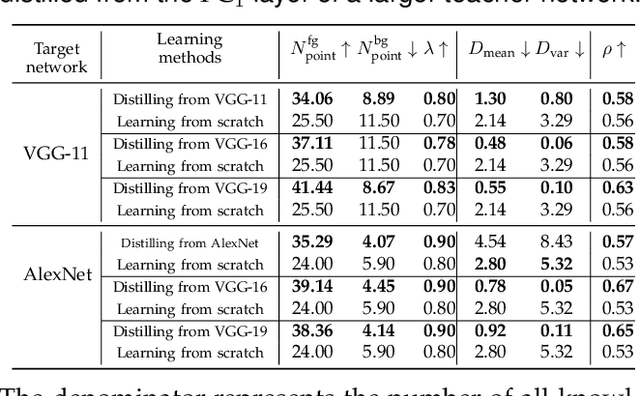
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Explaining Knowledge Distillation by Quantifying the Knowledge
Mar 07, 2020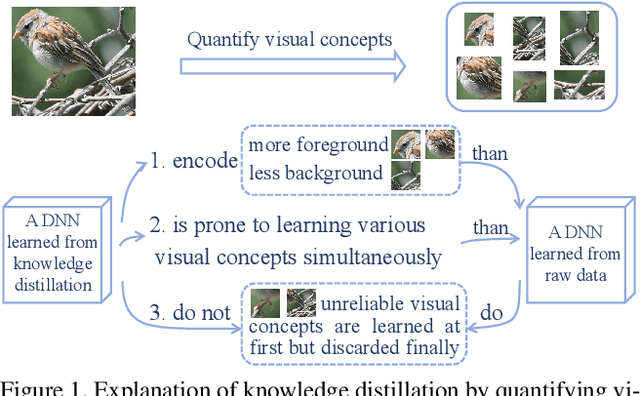
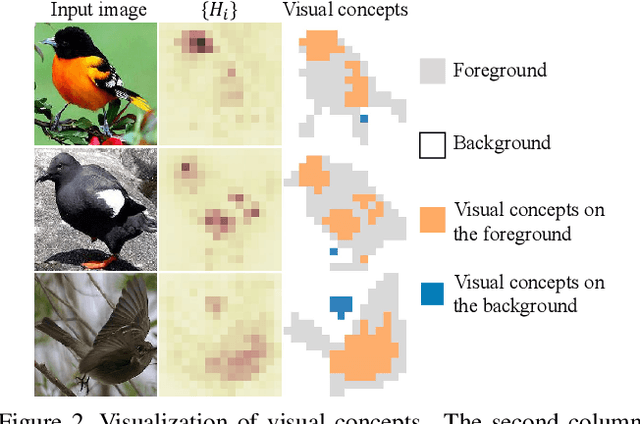
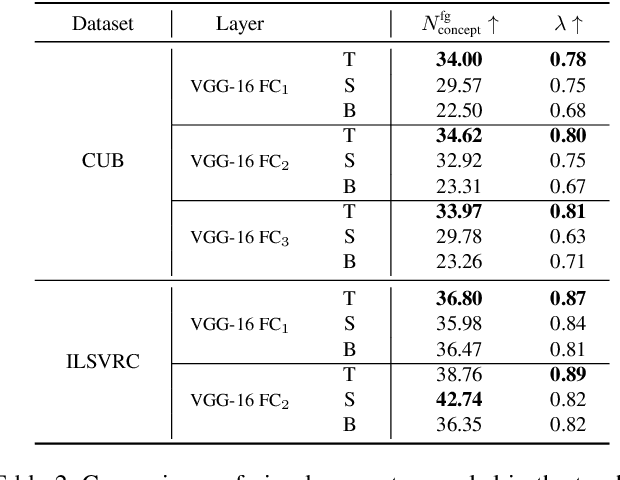
This paper presents a method to interpret the success of knowledge distillation by quantifying and analyzing task-relevant and task-irrelevant visual concepts that are encoded in intermediate layers of a deep neural network (DNN). More specifically, three hypotheses are proposed as follows. 1. Knowledge distillation makes the DNN learn more visual concepts than learning from raw data. 2. Knowledge distillation ensures that the DNN is prone to learning various visual concepts simultaneously. Whereas, in the scenario of learning from raw data, the DNN learns visual concepts sequentially. 3. Knowledge distillation yields more stable optimization directions than learning from raw data. Accordingly, we design three types of mathematical metrics to evaluate feature representations of the DNN. In experiments, we diagnosed various DNNs, and above hypotheses were verified.