 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpA2V: Harnessing Spatial Auditory Cues for Audio-driven Spatially-aware Video Generation
Aug 01, 2025Audio-driven video generation aims to synthesize realistic videos that align with input audio recordings, akin to the human ability to visualize scenes from auditory input. However, existing approaches predominantly focus on exploring semantic information, such as the classes of sounding sources present in the audio, limiting their ability to generate videos with accurate content and spatial composition. In contrast, we humans can not only naturally identify the semantic categories of sounding sources but also determine their deeply encoded spatial attributes, including locations and movement directions. This useful information can be elucidated by considering specific spatial indicators derived from the inherent physical properties of sound, such as loudness or frequency. As prior methods largely ignore this factor, we present SpA2V, the first framework explicitly exploits these spatial auditory cues from audios to generate videos with high semantic and spatial correspondence. SpA2V decomposes the generation process into two stages: 1) Audio-guided Video Planning: We meticulously adapt a state-of-the-art MLLM for a novel task of harnessing spatial and semantic cues from input audio to construct Video Scene Layouts (VSLs). This serves as an intermediate representation to bridge the gap between the audio and video modalities. 2) Layout-grounded Video Generation: We develop an efficient and effective approach to seamlessly integrate VSLs as conditional guidance into pre-trained diffusion models, enabling VSL-grounded video generation in a training-free manner. Extensive experiments demonstrate that SpA2V excels in generating realistic videos with semantic and spatial alignment to the input audios.
ModelGrow: Continual Text-to-Video Pre-training with Model Expansion and Language Understanding Enhancement
Dec 25, 2024Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to "grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow. Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding. For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance. For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts. This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts. Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.
Large Motion Video Autoencoding with Cross-modal Video VAE
Dec 23, 2024



Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression. Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding. First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts. Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression. Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability. Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method. The project website can be found at~\href{https://yzxing87.github.io/vae/}{https://yzxing87.github.io/vae/}.
LLMs Meet Multimodal Generation and Editing: A Survey
May 29, 2024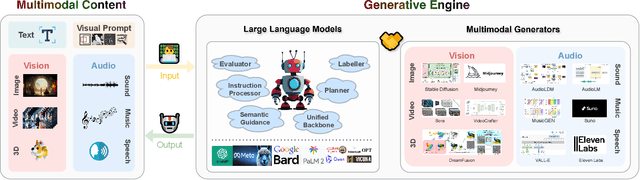
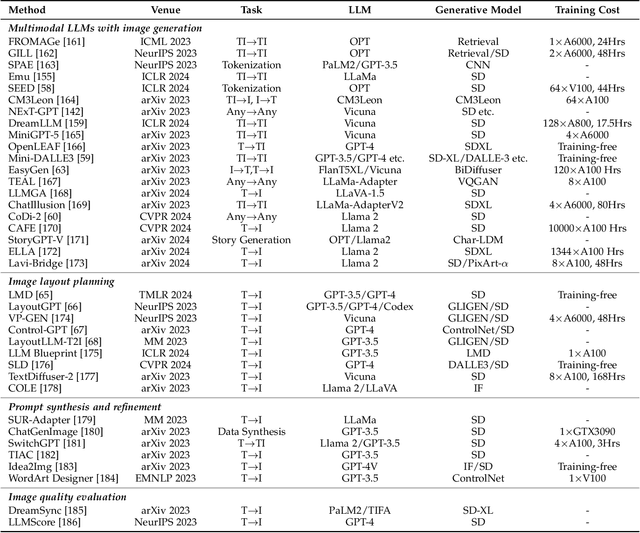
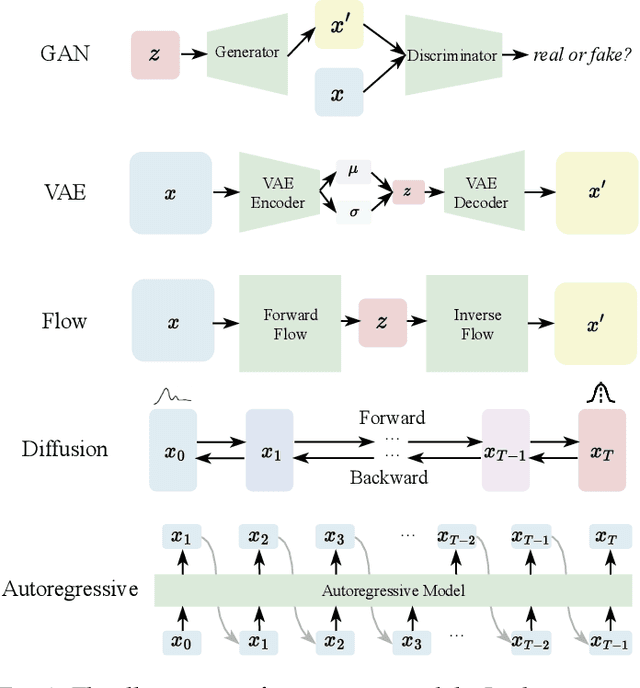
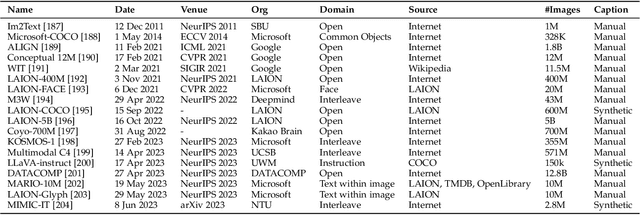
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on understanding. This survey elaborates on multimodal generation across different domains, including image, video, 3D, and audio, where we highlight the notable advancements with milestone works in these fields. Specifically, we exhaustively investigate the key technical components behind methods and multimodal datasets utilized in these studies. Moreover, we dig into tool-augmented multimodal agents that can use existing generative models for human-computer interaction. Lastly, we also comprehensively discuss the advancement in AI safety and investigate emerging applications as well as future prospects. Our work provides a systematic and insightful overview of multimodal generation, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners
Feb 27, 2024



Video and audio content creation serves as the core technique for the movie industry and professional users. Recently, existing diffusion-based methods tackle video and audio generation separately, which hinders the technique transfer from academia to industry. In this work, we aim at filling the gap, with a carefully designed optimization-based framework for cross-visual-audio and joint-visual-audio generation. We observe the powerful generation ability of off-the-shelf video or audio generation models. Thus, instead of training the giant models from scratch, we propose to bridge the existing strong models with a shared latent representation space. Specifically, we propose a multimodality latent aligner with the pre-trained ImageBind model. Our latent aligner shares a similar core as the classifier guidance that guides the diffusion denoising process during inference time. Through carefully designed optimization strategy and loss functions, we show the superior performance of our method on joint video-audio generation, visual-steered audio generation, and audio-steered visual generation tasks. The project website can be found at https://yzxing87.github.io/Seeing-and-Hearing/
Taming Latent Diffusion Models to See in the Dark
Dec 02, 2023Enhancing a low-light noisy RAW image into a well-exposed and clean sRGB image is a significant challenge in computational photography. Due to the limitation of large-scale paired data, prior approaches have difficulty in recovering fine details and true colors in extremely low-light regions. Meanwhile, recent advancements in generative diffusion models have shown promising generating capabilities, which inspires this work to explore generative priors from a diffusion model trained on a large-scale open-domain dataset to benefit the low-light image enhancement (LLIE) task. Based on this intention, we propose a novel diffusion-model-based LLIE method, dubbed LDM-SID. LDM-SID aims at inserting a set of proposed taming modules into a frozen pre-trained diffusion model to steer its generating process. Specifically, the taming module fed with low-light information serves to output a pair of affine transformation parameters to modulate the intermediate feature in the diffusion model. Additionally, based on the observation of dedicated generative priors across different portions of the diffusion model, we propose to apply 2D discrete wavelet transforms on the input RAW image, resulting in dividing the LLIE task into two essential parts: low-frequency content generation and high-frequency detail maintenance. This enables us to skillfully tame the diffusion model for optimized structural generation and detail enhancement. Extensive experiments demonstrate the proposed method not only achieves state-of-the-art performance in quantitative evaluations but also shows significant superiority in visual comparisons. These findings highlight the effectiveness of leveraging a pre-trained diffusion model as a generative prior to the LLIE task.
Online Overexposed Pixels Hallucination in Videos with Adaptive Reference Frame Selection
Aug 29, 2023Low dynamic range (LDR) cameras cannot deal with wide dynamic range inputs, frequently leading to local overexposure issues. We present a learning-based system to reduce these artifacts without resorting to complex acquisition mechanisms like alternating exposures or costly processing that are typical of high dynamic range (HDR) imaging. We propose a transformer-based deep neural network (DNN) to infer the missing HDR details. In an ablation study, we show the importance of using a multiscale DNN and train it with the proper cost function to achieve state-of-the-art quality. To aid the reconstruction of the overexposed areas, our DNN takes a reference frame from the past as an additional input. This leverages the commonly occurring temporal instabilities of autoexposure to our advantage: since well-exposed details in the current frame may be overexposed in the future, we use reinforcement learning to train a reference frame selection DNN that decides whether to adopt the current frame as a future reference. Without resorting to alternating exposures, we obtain therefore a causal, HDR hallucination algorithm with potential application in common video acquisition settings. Our demo video can be found at https://drive.google.com/file/d/1-r12BKImLOYCLUoPzdebnMyNjJ4Rk360/view
Deep Video Prior for Video Consistency and Propagation
Jan 27, 2022Applying an image processing algorithm independently to each video frame often leads to temporal inconsistency in the resulting video. To address this issue, we present a novel and general approach for blind video temporal consistency. Our method is only trained on a pair of original and processed videos directly instead of a large dataset. Unlike most previous methods that enforce temporal consistency with optical flow, we show that temporal consistency can be achieved by training a convolutional neural network on a video with Deep Video Prior (DVP). Moreover, a carefully designed iteratively reweighted training strategy is proposed to address the challenging multimodal inconsistency problem. We demonstrate the effectiveness of our approach on 7 computer vision tasks on videos. Extensive quantitative and perceptual experiments show that our approach obtains superior performance than state-of-the-art methods on blind video temporal consistency. We further extend DVP to video propagation and demonstrate its effectiveness in propagating three different types of information (color, artistic style, and object segmentation). A progressive propagation strategy with pseudo labels is also proposed to enhance DVP's performance on video propagation. Our source codes are publicly available at https://github.com/ChenyangLEI/deep-video-prior.
Unsupervised Portrait Shadow Removal via Generative Priors
Aug 07, 2021



Portrait images often suffer from undesirable shadows cast by casual objects or even the face itself. While existing methods for portrait shadow removal require training on a large-scale synthetic dataset, we propose the first unsupervised method for portrait shadow removal without any training data. Our key idea is to leverage the generative facial priors embedded in the off-the-shelf pretrained StyleGAN2. To achieve this, we formulate the shadow removal task as a layer decomposition problem: a shadowed portrait image is constructed by the blending of a shadow image and a shadow-free image. We propose an effective progressive optimization algorithm to learn the decomposition process. Our approach can also be extended to portrait tattoo removal and watermark removal. Qualitative and quantitative experiments on a real-world portrait shadow dataset demonstrate that our approach achieves comparable performance with supervised shadow removal methods. Our source code is available at https://github.com/YingqingHe/Shadow-Removal-via-Generative-Priors.
Invertible Image Signal Processing
Apr 06, 2021
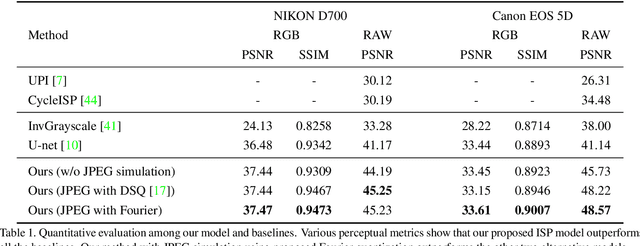
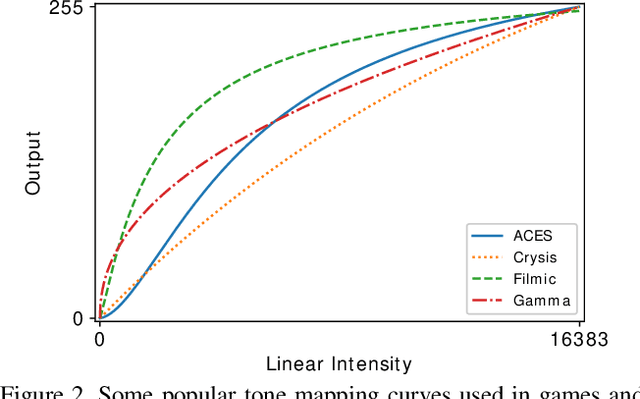

Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.