 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Safe Traffic Sign Recognition using N-version with Weighted Voting
Jul 09, 2025Autonomous driving is rapidly advancing as a key application of machine learning, yet ensuring the safety of these systems remains a critical challenge. Traffic sign recognition, an essential component of autonomous vehicles, is particularly vulnerable to adversarial attacks that can compromise driving safety. In this paper, we propose an N-version machine learning (NVML) framework that integrates a safety-aware weighted soft voting mechanism. Our approach utilizes Failure Mode and Effects Analysis (FMEA) to assess potential safety risks and assign dynamic, safety-aware weights to the ensemble outputs. We evaluate the robustness of three-version NVML systems employing various voting mechanisms against adversarial samples generated using the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) attacks. Experimental results demonstrate that our NVML approach significantly enhances the robustness and safety of traffic sign recognition systems under adversarial conditions.
Artificial Intelligence-Enhanced Couinaud Segmentation for Precision Liver Cancer Therapy
Nov 05, 2024



Precision therapy for liver cancer necessitates accurately delineating liver sub-regions to protect healthy tissue while targeting tumors, which is essential for reducing recurrence and improving survival rates. However, the segmentation of hepatic segments, known as Couinaud segmentation, is challenging due to indistinct sub-region boundaries and the need for extensive annotated datasets. This study introduces LiverFormer, a novel Couinaud segmentation model that effectively integrates global context with low-level local features based on a 3D hybrid CNN-Transformer architecture. Additionally, a registration-based data augmentation strategy is equipped to enhance the segmentation performance with limited labeled data. Evaluated on CT images from 123 patients, LiverFormer demonstrated high accuracy and strong concordance with expert annotations across various metrics, allowing for enhanced treatment planning for surgery and radiation therapy. It has great potential to reduces complications and minimizes potential damages to surrounding tissue, leading to improved outcomes for patients undergoing complex liver cancer treatments.
Taming Latent Diffusion Models to See in the Dark
Dec 02, 2023Enhancing a low-light noisy RAW image into a well-exposed and clean sRGB image is a significant challenge in computational photography. Due to the limitation of large-scale paired data, prior approaches have difficulty in recovering fine details and true colors in extremely low-light regions. Meanwhile, recent advancements in generative diffusion models have shown promising generating capabilities, which inspires this work to explore generative priors from a diffusion model trained on a large-scale open-domain dataset to benefit the low-light image enhancement (LLIE) task. Based on this intention, we propose a novel diffusion-model-based LLIE method, dubbed LDM-SID. LDM-SID aims at inserting a set of proposed taming modules into a frozen pre-trained diffusion model to steer its generating process. Specifically, the taming module fed with low-light information serves to output a pair of affine transformation parameters to modulate the intermediate feature in the diffusion model. Additionally, based on the observation of dedicated generative priors across different portions of the diffusion model, we propose to apply 2D discrete wavelet transforms on the input RAW image, resulting in dividing the LLIE task into two essential parts: low-frequency content generation and high-frequency detail maintenance. This enables us to skillfully tame the diffusion model for optimized structural generation and detail enhancement. Extensive experiments demonstrate the proposed method not only achieves state-of-the-art performance in quantitative evaluations but also shows significant superiority in visual comparisons. These findings highlight the effectiveness of leveraging a pre-trained diffusion model as a generative prior to the LLIE task.
Video Waterdrop Removal via Spatio-Temporal Fusion in Driving Scenes
Feb 24, 2023



The waterdrops on windshields during driving can cause severe visual obstructions, which may lead to car accidents. Meanwhile, the waterdrops can also degrade the performance of a computer vision system in autonomous driving. To address these issues, we propose an attention-based framework that fuses the spatio-temporal representations from multiple frames to restore visual information occluded by waterdrops. Due to the lack of training data for video waterdrop removal, we propose a large-scale synthetic dataset with simulated waterdrops in complex driving scenes on rainy days. To improve the generality of our proposed method, we adopt a cross-modality training strategy that combines synthetic videos and real-world images. Extensive experiments show that our proposed method can generalize well and achieve the best waterdrop removal performance in complex real-world driving scenes.
Optimizing Video Prediction via Video Frame Interpolation
Jun 27, 2022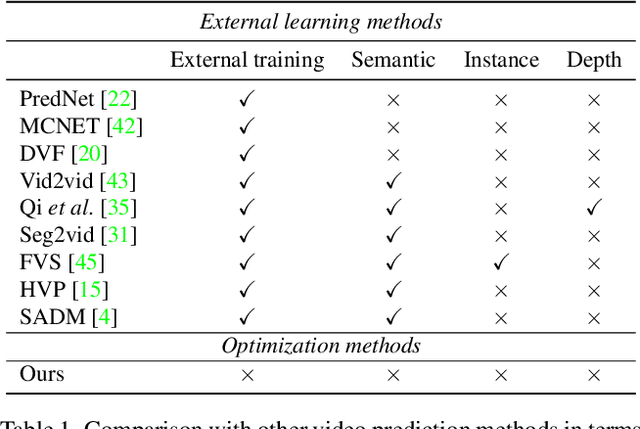
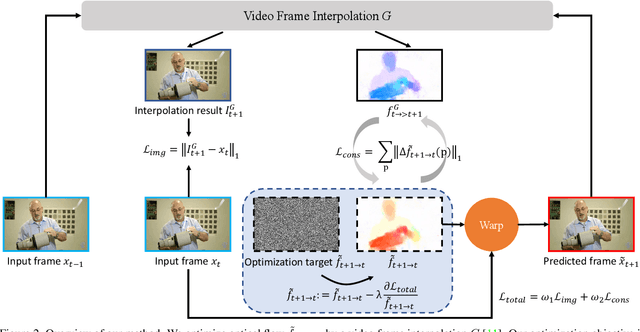
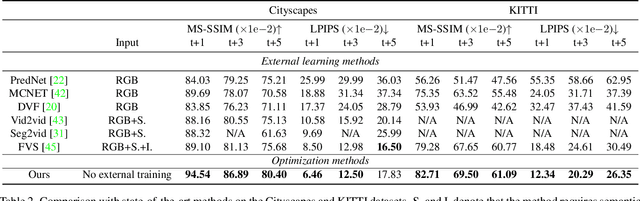

Video prediction is an extrapolation task that predicts future frames given past frames, and video frame interpolation is an interpolation task that estimates intermediate frames between two frames. We have witnessed the tremendous advancement of video frame interpolation, but the general video prediction in the wild is still an open question. Inspired by the photo-realistic results of video frame interpolation, we present a new optimization framework for video prediction via video frame interpolation, in which we solve an extrapolation problem based on an interpolation model. Our video prediction framework is based on optimization with a pretrained differentiable video frame interpolation module without the need for a training dataset, and thus there is no domain gap issue between training and test data. Also, our approach does not need any additional information such as semantic or instance maps, which makes our framework applicable to any video. Extensive experiments on the Cityscapes, KITTI, DAVIS, Middlebury, and Vimeo90K datasets show that our video prediction results are robust in general scenarios, and our approach outperforms other video prediction methods that require a large amount of training data or extra semantic information.
Unifying Global-Local Representations in Salient Object Detection with Transformer
Aug 05, 2021
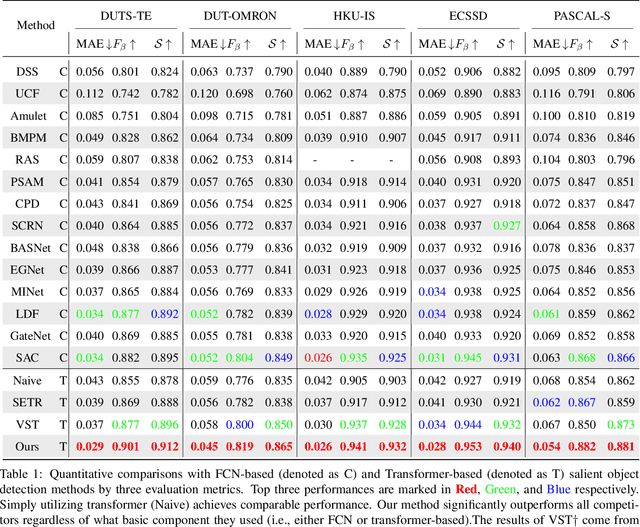

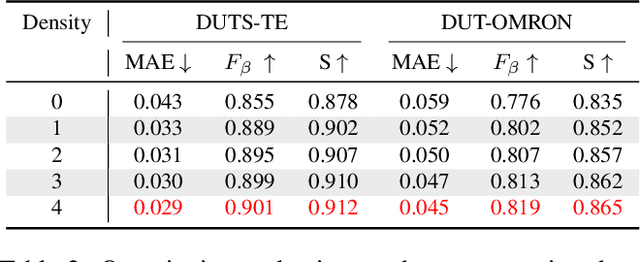
The fully convolutional network (FCN) has dominated salient object detection for a long period. However, the locality of CNN requires the model deep enough to have a global receptive field and such a deep model always leads to the loss of local details. In this paper, we introduce a new attention-based encoder, vision transformer, into salient object detection to ensure the globalization of the representations from shallow to deep layers. With the global view in very shallow layers, the transformer encoder preserves more local representations to recover the spatial details in final saliency maps. Besides, as each layer can capture a global view of its previous layer, adjacent layers can implicitly maximize the representation differences and minimize the redundant features, making that every output feature of transformer layers contributes uniquely for final prediction. To decode features from the transformer, we propose a simple yet effective deeply-transformed decoder. The decoder densely decodes and upsamples the transformer features, generating the final saliency map with less noise injection. Experimental results demonstrate that our method significantly outperforms other FCN-based and transformer-based methods in five benchmarks by a large margin, with an average of 12.17% improvement in terms of Mean Absolute Error (MAE). Code will be available at https://github.com/OliverRensu/GLSTR.