 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-5: Vision Transformers for The Mid-2020s
Feb 08, 2026This work presents a systematic investigation into modernizing Vision Transformer backbones by leveraging architectural advancements from the past five years. While preserving the canonical Attention-FFN structure, we conduct a component-wise refinement involving normalization, activation functions, positional encoding, gating mechanisms, and learnable tokens. These updates form a new generation of Vision Transformers, which we call ViT-5. Extensive experiments demonstrate that ViT-5 consistently outperforms state-of-the-art plain Vision Transformers across both understanding and generation benchmarks. On ImageNet-1k classification, ViT-5-Base reaches 84.2\% top-1 accuracy under comparable compute, exceeding DeiT-III-Base at 83.8\%. ViT-5 also serves as a stronger backbone for generative modeling: when plugged into an SiT diffusion framework, it achieves 1.84 FID versus 2.06 with a vanilla ViT backbone. Beyond headline metrics, ViT-5 exhibits improved representation learning and favorable spatial reasoning behavior, and transfers reliably across tasks. With a design aligned with contemporary foundation-model practices, ViT-5 offers a simple drop-in upgrade over vanilla ViT for mid-2020s vision backbones.
WorldEdit: Towards Open-World Image Editing with a Knowledge-Informed Benchmark
Feb 06, 2026Recent advances in image editing models have demonstrated remarkable capabilities in executing explicit instructions, such as attribute manipulation, style transfer, and pose synthesis. However, these models often face challenges when dealing with implicit editing instructions, which describe the cause of a visual change without explicitly detailing the resulting outcome. These limitations arise because existing models rely on uniform editing strategies that are not equipped to handle the complex world knowledge and reasoning required for implicit instructions. To address this gap, we introduce \textbf{WorldEdit}, a dataset specifically designed to enable world-driven image editing. WorldEdit consists of high-quality editing samples, guided by paraphrased instructions that align with real-world causal logic. Furthermore, we provide \textbf{WorldEdit-Test} for evaluating the existing model's performance on causal editing scenarios. With WorldEdit, we use a two-stage training framework for fine-tuning models like Bagel, integrating with a causal verification reward. Our results show that the proposed dataset and methods significantly narrow the gap with GPT-4o and Nano-Banana, demonstrating competitive performance not only in instruction following but also in knowledge plausibility, where many open-source systems typically struggle.
CoPE: Clipped RoPE as A Scalable Free Lunch for Long Context LLMs
Feb 05, 2026Rotary Positional Embedding (RoPE) is a key component of context scaling in Large Language Models (LLMs). While various methods have been proposed to adapt RoPE to longer contexts, their guiding principles generally fall into two categories: (1) out-of-distribution (OOD) mitigation, which scales RoPE frequencies to accommodate unseen positions, and (2) Semantic Modeling, which posits that the attention scores computed with RoPE should always prioritize semantically similar tokens. In this work, we unify these seemingly distinct objectives through a minimalist intervention, namely CoPE: soft clipping lowfrequency components of RoPE. CoPE not only eliminates OOD outliers and refines semantic signals, but also prevents spectral leakage caused by hard clipping. Extensive experiments demonstrate that simply applying our soft clipping strategy to RoPE yields significant performance gains that scale up to 256k context length, validating our theoretical analysis and establishing CoPE as a new state-of-the-art for length generalization. Our code, data, and models are available at https://github.com/hrlics/CoPE.
Spiral RoPE: Rotate Your Rotary Positional Embeddings in the 2D Plane
Feb 03, 2026Rotary Position Embedding (RoPE) is the de facto positional encoding in large language models due to its ability to encode relative positions and support length extrapolation. When adapted to vision transformers, the standard axial formulation decomposes two-dimensional spatial positions into horizontal and vertical components, implicitly restricting positional encoding to axis-aligned directions. We identify this directional constraint as a fundamental limitation of the standard axial 2D RoPE, which hinders the modeling of oblique spatial relationships that naturally exist in natural images. To overcome this limitation, we propose Spiral RoPE, a simple yet effective extension that enables multi-directional positional encoding by partitioning embedding channels into multiple groups associated with uniformly distributed directions. Each group is rotated according to the projection of the patch position onto its corresponding direction, allowing spatial relationships to be encoded beyond the horizontal and vertical axes. Across a wide range of vision tasks including classification, segmentation, and generation, Spiral RoPE consistently improves performance. Qualitative analysis of attention maps further show that Spiral RoPE exhibits more concentrated activations on semantically relevant objects and better respects local object boundaries, highlighting the importance of multi-directional positional encoding in vision transformers.
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
Grouping First, Attending Smartly: Training-Free Acceleration for Diffusion Transformers
May 20, 2025
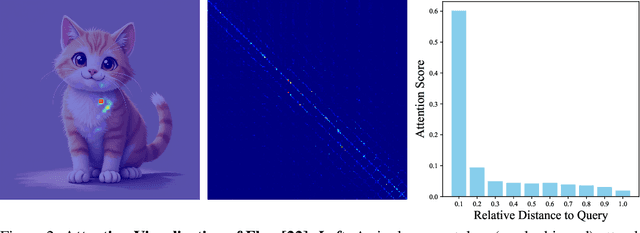
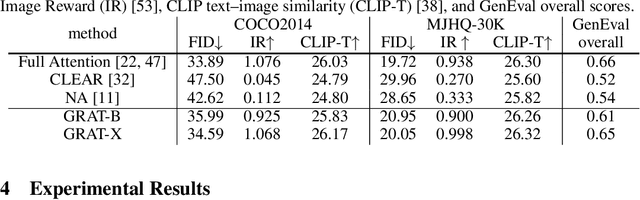
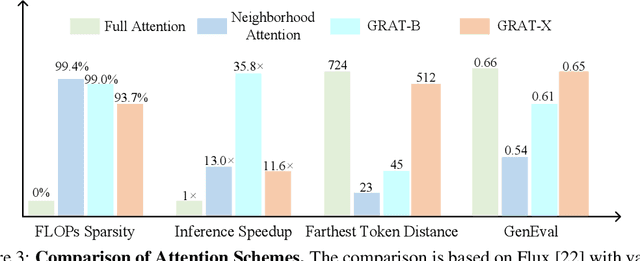
Diffusion-based Transformers have demonstrated impressive generative capabilities, but their high computational costs hinder practical deployment, for example, generating an $8192\times 8192$ image can take over an hour on an A100 GPU. In this work, we propose GRAT (\textbf{GR}ouping first, \textbf{AT}tending smartly), a training-free attention acceleration strategy for fast image and video generation without compromising output quality. The key insight is to exploit the inherent sparsity in learned attention maps (which tend to be locally focused) in pretrained Diffusion Transformers and leverage better GPU parallelism. Specifically, GRAT first partitions contiguous tokens into non-overlapping groups, aligning both with GPU execution patterns and the local attention structures learned in pretrained generative Transformers. It then accelerates attention by having all query tokens within the same group share a common set of attendable key and value tokens. These key and value tokens are further restricted to structured regions, such as surrounding blocks or criss-cross regions, significantly reducing computational overhead (e.g., attaining a \textbf{35.8$\times$} speedup over full attention when generating $8192\times 8192$ images) while preserving essential attention patterns and long-range context. We validate GRAT on pretrained Flux and HunyuanVideo for image and video generation, respectively. In both cases, GRAT achieves substantially faster inference without any fine-tuning, while maintaining the performance of full attention. We hope GRAT will inspire future research on accelerating Diffusion Transformers for scalable visual generation.
Beyond Next-Token: Next-X Prediction for Autoregressive Visual Generation
Feb 27, 2025Autoregressive (AR) modeling, known for its next-token prediction paradigm, underpins state-of-the-art language and visual generative models. Traditionally, a ``token'' is treated as the smallest prediction unit, often a discrete symbol in language or a quantized patch in vision. However, the optimal token definition for 2D image structures remains an open question. Moreover, AR models suffer from exposure bias, where teacher forcing during training leads to error accumulation at inference. In this paper, we propose xAR, a generalized AR framework that extends the notion of a token to an entity X, which can represent an individual patch token, a cell (a $k\times k$ grouping of neighboring patches), a subsample (a non-local grouping of distant patches), a scale (coarse-to-fine resolution), or even a whole image. Additionally, we reformulate discrete token classification as \textbf{continuous entity regression}, leveraging flow-matching methods at each AR step. This approach conditions training on noisy entities instead of ground truth tokens, leading to Noisy Context Learning, which effectively alleviates exposure bias. As a result, xAR offers two key advantages: (1) it enables flexible prediction units that capture different contextual granularity and spatial structures, and (2) it mitigates exposure bias by avoiding reliance on teacher forcing. On ImageNet-256 generation benchmark, our base model, xAR-B (172M), outperforms DiT-XL/SiT-XL (675M) while achieving 20$\times$ faster inference. Meanwhile, xAR-H sets a new state-of-the-art with an FID of 1.24, running 2.2$\times$ faster than the previous best-performing model without relying on vision foundation modules (\eg, DINOv2) or advanced guidance interval sampling.
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
Dec 19, 2024Autoregressive (AR) modeling has achieved remarkable success in natural language processing by enabling models to generate text with coherence and contextual understanding through next token prediction. Recently, in image generation, VAR proposes scale-wise autoregressive modeling, which extends the next token prediction to the next scale prediction, preserving the 2D structure of images. However, VAR encounters two primary challenges: (1) its complex and rigid scale design limits generalization in next scale prediction, and (2) the generator's dependence on a discrete tokenizer with the same complex scale structure restricts modularity and flexibility in updating the tokenizer. To address these limitations, we introduce FlowAR, a general next scale prediction method featuring a streamlined scale design, where each subsequent scale is simply double the previous one. This eliminates the need for VAR's intricate multi-scale residual tokenizer and enables the use of any off-the-shelf Variational AutoEncoder (VAE). Our simplified design enhances generalization in next scale prediction and facilitates the integration of Flow Matching for high-quality image synthesis. We validate the effectiveness of FlowAR on the challenging ImageNet-256 benchmark, demonstrating superior generation performance compared to previous methods. Codes will be available at \url{https://github.com/OliverRensu/FlowAR}.
HResFormer: Hybrid Residual Transformer for Volumetric Medical Image Segmentation
Dec 16, 2024



Vision Transformer shows great superiority in medical image segmentation due to the ability in learning long-range dependency. For medical image segmentation from 3D data, such as computed tomography (CT), existing methods can be broadly classified into 2D-based and 3D-based methods. One key limitation in 2D-based methods is that the intra-slice information is ignored, while the limitation in 3D-based methods is the high computation cost and memory consumption, resulting in a limited feature representation for inner-slice information. During the clinical examination, radiologists primarily use the axial plane and then routinely review both axial and coronal planes to form a 3D understanding of anatomy. Motivated by this fact, our key insight is to design a hybrid model which can first learn fine-grained inner-slice information and then generate a 3D understanding of anatomy by incorporating 3D information. We present a novel \textbf{H}ybrid \textbf{Res}idual trans\textbf{Former} \textbf{(HResFormer)} for 3D medical image segmentation. Building upon standard 2D and 3D Transformer backbones, HResFormer involves two novel key designs: \textbf{(1)} a \textbf{H}ybrid \textbf{L}ocal-\textbf{G}lobal fusion \textbf{M}odule \textbf{(HLGM)} to effectively and adaptively fuse inner-slice information from 2D Transformer and intra-slice information from 3D volumes for 3D Transformer with local fine-grained and global long-range representation. \textbf{(2)} a residual learning of the hybrid model, which can effectively leverage the inner-slice and intra-slice information for better 3D understanding of anatomy. Experiments show that our HResFormer outperforms prior art on widely-used medical image segmentation benchmarks. This paper sheds light on an important but neglected way to design Transformers for 3D medical image segmentation.
M-VAR: Decoupled Scale-wise Autoregressive Modeling for High-Quality Image Generation
Nov 15, 2024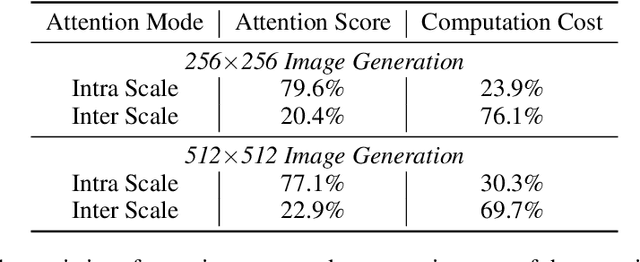



There exists recent work in computer vision, named VAR, that proposes a new autoregressive paradigm for image generation. Diverging from the vanilla next-token prediction, VAR structurally reformulates the image generation into a coarse to fine next-scale prediction. In this paper, we show that this scale-wise autoregressive framework can be effectively decoupled into \textit{intra-scale modeling}, which captures local spatial dependencies within each scale, and \textit{inter-scale modeling}, which models cross-scale relationships progressively from coarse-to-fine scales. This decoupling structure allows to rebuild VAR in a more computationally efficient manner. Specifically, for intra-scale modeling -- crucial for generating high-fidelity images -- we retain the original bidirectional self-attention design to ensure comprehensive modeling; for inter-scale modeling, which semantically connects different scales but is computationally intensive, we apply linear-complexity mechanisms like Mamba to substantially reduce computational overhead. We term this new framework M-VAR. Extensive experiments demonstrate that our method outperforms existing models in both image quality and generation speed. For example, our 1.5B model, with fewer parameters and faster inference speed, outperforms the largest VAR-d30-2B. Moreover, our largest model M-VAR-d32 impressively registers 1.78 FID on ImageNet 256$\times$256 and outperforms the prior-art autoregressive models LlamaGen/VAR by 0.4/0.19 and popular diffusion models LDM/DiT by 1.82/0.49, respectively. Code is avaiable at \url{https://github.com/OliverRensu/MVAR}.