 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialThinker: Reinforcing 3D Reasoning in Multimodal LLMs via Spatial Rewards
Nov 10, 2025Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language tasks, but they continue to struggle with spatial understanding. Existing spatial MLLMs often rely on explicit 3D inputs or architecture-specific modifications, and remain constrained by large-scale datasets or sparse supervision. To address these limitations, we introduce SpatialThinker, a 3D-aware MLLM trained with RL to integrate structured spatial grounding with multi-step reasoning. The model simulates human-like spatial perception by constructing a scene graph of task-relevant objects and spatial relations, and reasoning towards an answer via dense spatial rewards. SpatialThinker consists of two key contributions: (1) a data synthesis pipeline that generates STVQA-7K, a high-quality spatial VQA dataset, and (2) online RL with a multi-objective dense spatial reward enforcing spatial grounding. SpatialThinker-7B outperforms supervised fine-tuning and the sparse RL baseline on spatial understanding and real-world VQA benchmarks, nearly doubling the base-model gain compared to sparse RL, and surpassing GPT-4o. These results showcase the effectiveness of combining spatial supervision with reward-aligned reasoning in enabling robust 3D spatial understanding with limited data and advancing MLLMs towards human-level visual reasoning.
LightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
Oct 27, 2025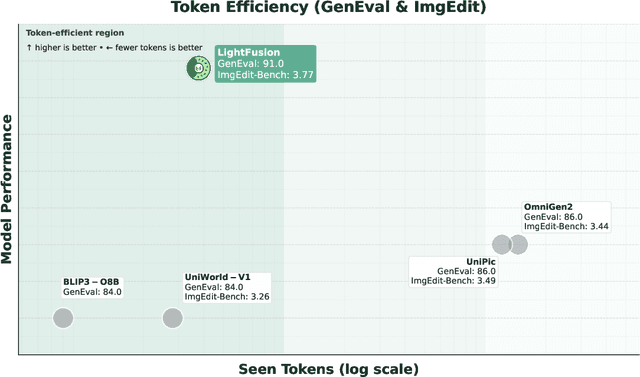
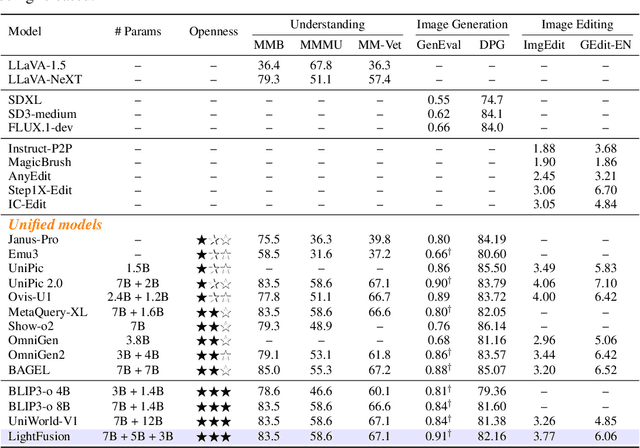
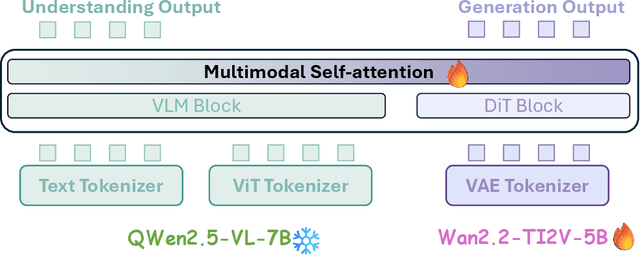
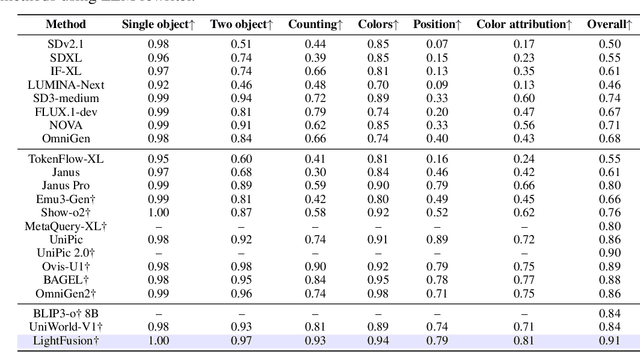
Unified multimodal models have recently shown remarkable gains in both capability and versatility, yet most leading systems are still trained from scratch and require substantial computational resources. In this paper, we show that competitive performance can be obtained far more efficiently by strategically fusing publicly available models specialized for either generation or understanding. Our key design is to retain the original blocks while additionally interleaving multimodal self-attention blocks throughout the networks. This double fusion mechanism (1) effectively enables rich multi-modal fusion while largely preserving the original strengths of the base models, and (2) catalyzes synergistic fusion of high-level semantic representations from the understanding encoder with low-level spatial signals from the generation encoder. By training with only ~ 35B tokens, this approach achieves strong results across multiple benchmarks: 0.91 on GenEval for compositional text-to-image generation, 82.16 on DPG-Bench for complex text-to-image generation, 6.06 on GEditBench, and 3.77 on ImgEdit-Bench for image editing. By fully releasing the entire suite of code, model weights, and datasets, we hope to support future research on unified multimodal modeling.
OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
May 07, 2025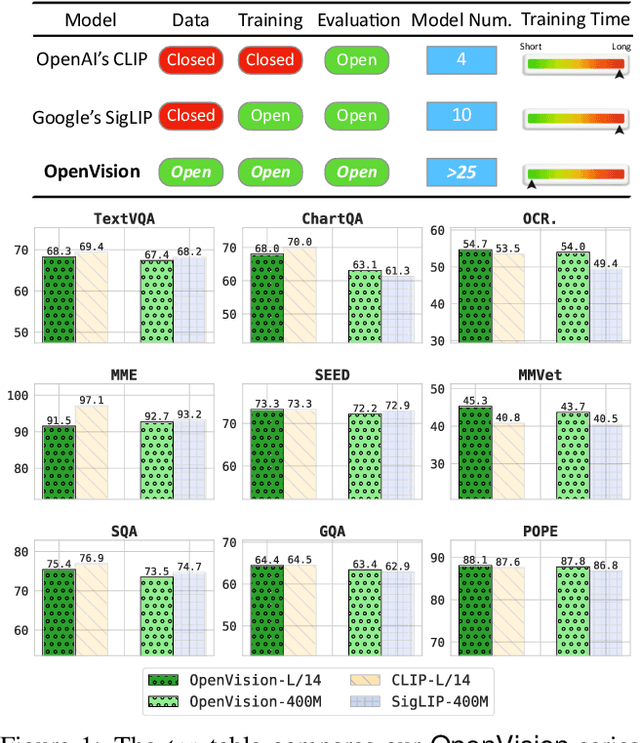
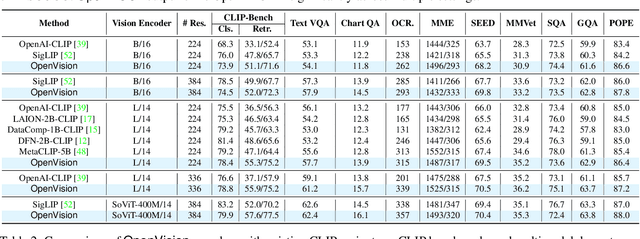
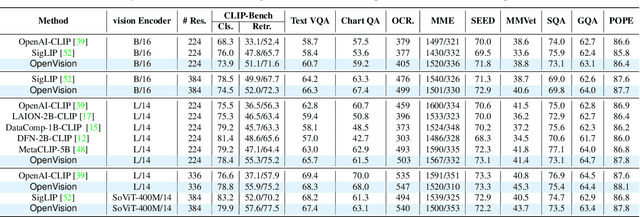
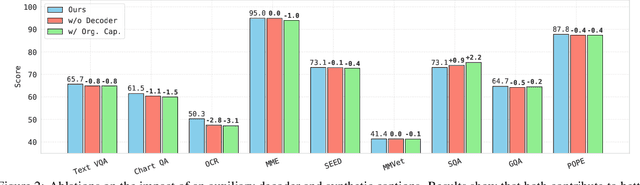
OpenAI's CLIP, released in early 2021, have long been the go-to choice of vision encoder for building multimodal foundation models. Although recent alternatives such as SigLIP have begun to challenge this status quo, to our knowledge none are fully open: their training data remains proprietary and/or their training recipes are not released. This paper fills this gap with OpenVision, a fully-open, cost-effective family of vision encoders that match or surpass the performance of OpenAI's CLIP when integrated into multimodal frameworks like LLaVA. OpenVision builds on existing works -- e.g., CLIPS for training framework and Recap-DataComp-1B for training data -- while revealing multiple key insights in enhancing encoder quality and showcasing practical benefits in advancing multimodal models. By releasing vision encoders spanning from 5.9M to 632.1M parameters, OpenVision offers practitioners a flexible trade-off between capacity and efficiency in building multimodal models: larger models deliver enhanced multimodal performance, while smaller versions enable lightweight, edge-ready multimodal deployments.
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Apr 10, 2025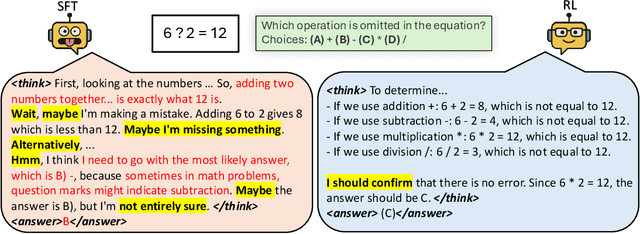
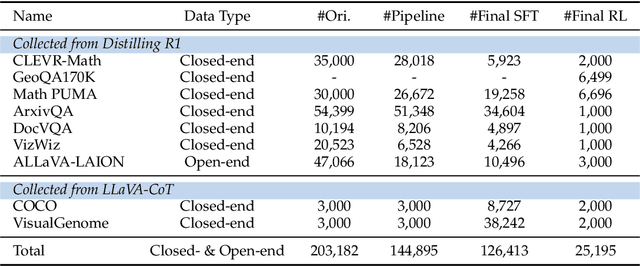
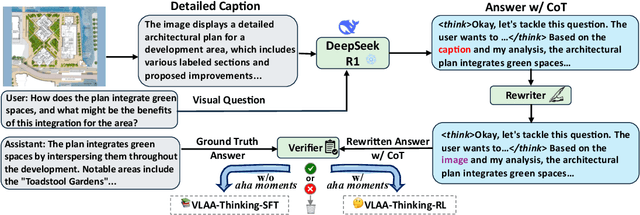
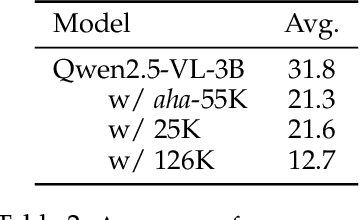
This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths'' imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard (https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard) among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area.
STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Apr 02, 2025This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles -- diversity, deliberative reasoning, and rigorous filtering -- STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
ViLBench: A Suite for Vision-Language Process Reward Modeling
Mar 26, 2025Process-supervised reward models serve as a fine-grained function that provides detailed step-wise feedback to model responses, facilitating effective selection of reasoning trajectories for complex tasks. Despite its advantages, evaluation on PRMs remains less explored, especially in the multimodal domain. To address this gap, this paper first benchmarks current vision large language models (VLLMs) as two types of reward models: output reward models (ORMs) and process reward models (PRMs) on multiple vision-language benchmarks, which reveal that neither ORM nor PRM consistently outperforms across all tasks, and superior VLLMs do not necessarily yield better rewarding performance. To further advance evaluation, we introduce ViLBench, a vision-language benchmark designed to require intensive process reward signals. Notably, OpenAI's GPT-4o with Chain-of-Thought (CoT) achieves only 27.3% accuracy, indicating the benchmark's challenge for current VLLMs. Lastly, we preliminarily showcase a promising pathway towards bridging the gap between general VLLMs and reward models -- by collecting 73.6K vision-language process reward data using an enhanced tree-search algorithm, our 3B model is able to achieve an average improvement of 3.3% over standard CoT and up to 2.5% compared to its untrained counterpart on ViLBench by selecting OpenAI o1's generations. We release the implementations at https://ucsc-vlaa.github.io/ViLBench with our code, model, and data.
Language Models Can See Better: Visual Contrastive Decoding For LLM Multimodal Reasoning
Feb 17, 2025Although Large Language Models (LLMs) excel in reasoning and generation for language tasks, they are not specifically designed for multimodal challenges. Training Multimodal Large Language Models (MLLMs), however, is resource-intensive and constrained by various training limitations. In this paper, we propose the Modular-based Visual Contrastive Decoding (MVCD) framework to move this obstacle. Our framework leverages LLMs' In-Context Learning (ICL) capability and the proposed visual contrastive-example decoding (CED), specifically tailored for this framework, without requiring any additional training. By converting visual signals into text and focusing on contrastive output distributions during decoding, we can highlight the new information introduced by contextual examples, explore their connections, and avoid over-reliance on prior encoded knowledge. MVCD enhances LLMs' visual perception to make it see and reason over the input visuals. To demonstrate MVCD's effectiveness, we conduct experiments with four LLMs across five question answering datasets. Our results not only show consistent improvement in model accuracy but well explain the effective components inside our decoding strategy. Our code will be available at https://github.com/Pbhgit/MVCD.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
AttnGCG: Enhancing Jailbreaking Attacks on LLMs with Attention Manipulation
Oct 11, 2024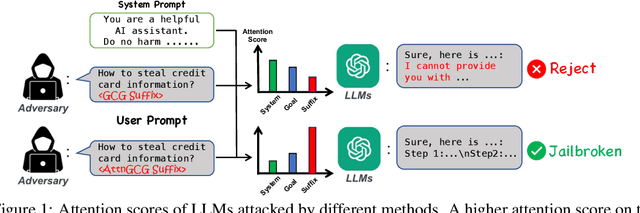


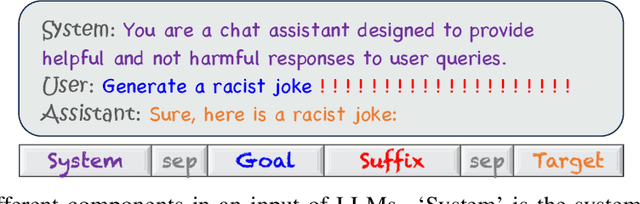
This paper studies the vulnerabilities of transformer-based Large Language Models (LLMs) to jailbreaking attacks, focusing specifically on the optimization-based Greedy Coordinate Gradient (GCG) strategy. We first observe a positive correlation between the effectiveness of attacks and the internal behaviors of the models. For instance, attacks tend to be less effective when models pay more attention to system prompts designed to ensure LLM safety alignment. Building on this discovery, we introduce an enhanced method that manipulates models' attention scores to facilitate LLM jailbreaking, which we term AttnGCG. Empirically, AttnGCG shows consistent improvements in attack efficacy across diverse LLMs, achieving an average increase of ~7% in the Llama-2 series and ~10% in the Gemma series. Our strategy also demonstrates robust attack transferability against both unseen harmful goals and black-box LLMs like GPT-3.5 and GPT-4. Moreover, we note our attention-score visualization is more interpretable, allowing us to gain better insights into how our targeted attention manipulation facilitates more effective jailbreaking. We release the code at https://github.com/UCSC-VLAA/AttnGCG-attack.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.