 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Image2Struct: Benchmarking Structure Extraction for Vision-Language Models
Oct 29, 2024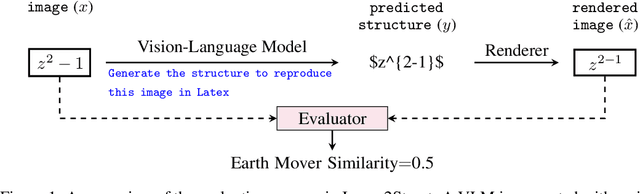

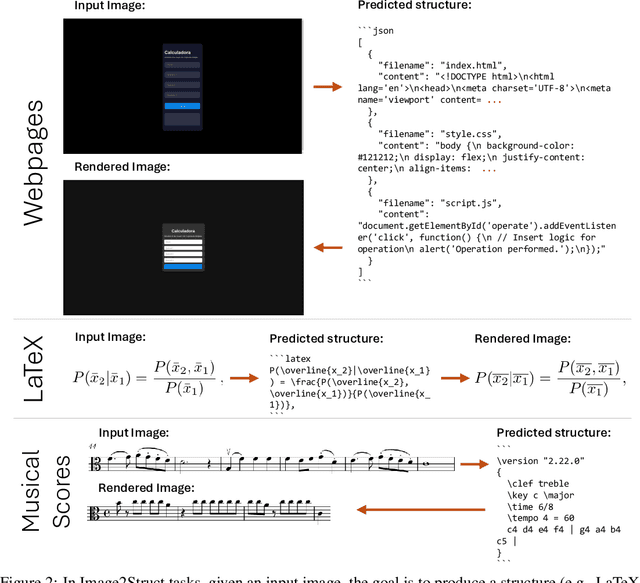
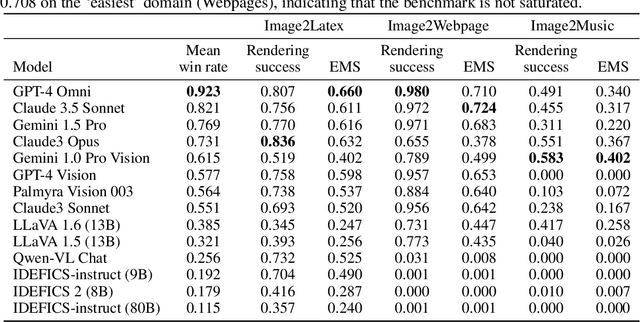
We introduce Image2Struct, a benchmark to evaluate vision-language models (VLMs) on extracting structure from images. Our benchmark 1) captures real-world use cases, 2) is fully automatic and does not require human judgment, and 3) is based on a renewable stream of fresh data. In Image2Struct, VLMs are prompted to generate the underlying structure (e.g., LaTeX code or HTML) from an input image (e.g., webpage screenshot). The structure is then rendered to produce an output image (e.g., rendered webpage), which is compared against the input image to produce a similarity score. This round-trip evaluation allows us to quantitatively evaluate VLMs on tasks with multiple valid structures. We create a pipeline that downloads fresh data from active online communities upon execution and evaluates the VLMs without human intervention. We introduce three domains (Webpages, LaTeX, and Musical Scores) and use five image metrics (pixel similarity, cosine similarity between the Inception vectors, learned perceptual image patch similarity, structural similarity index measure, and earth mover similarity) that allow efficient and automatic comparison between pairs of images. We evaluate Image2Struct on 14 prominent VLMs and find that scores vary widely, indicating that Image2Struct can differentiate between the performances of different VLMs. Additionally, the best score varies considerably across domains (e.g., 0.402 on sheet music vs. 0.830 on LaTeX equations), indicating that Image2Struct contains tasks of varying difficulty. For transparency, we release the full results at https://crfm.stanford.edu/helm/image2struct/v1.0.1/.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
Projected Task-Specific Layers for Multi-Task Reinforcement Learning
Sep 15, 2023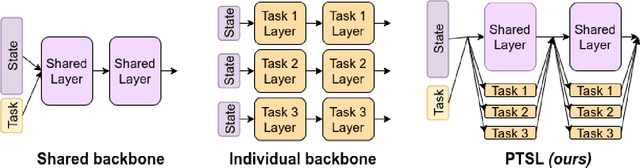
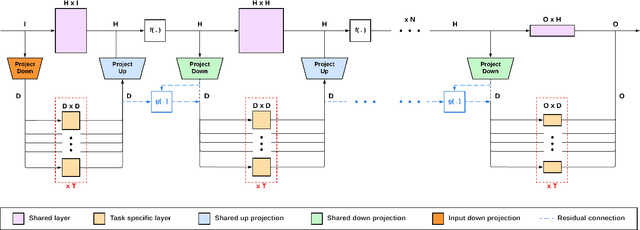
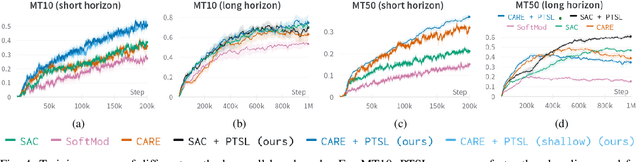
Multi-task reinforcement learning could enable robots to scale across a wide variety of manipulation tasks in homes and workplaces. However, generalizing from one task to another and mitigating negative task interference still remains a challenge. Addressing this challenge by successfully sharing information across tasks will depend on how well the structure underlying the tasks is captured. In this work, we introduce our new architecture, Projected Task-Specific Layers (PTSL), that leverages a common policy with dense task-specific corrections through task-specific layers to better express shared and variable task information. We then show that our model outperforms the state of the art on the MT10 and MT50 benchmarks of Meta-World consisting of 10 and 50 goal-conditioned tasks for a Sawyer arm.
A Skeleton-based Approach For Rock Crack Detection Towards A Climbing Robot Application
Sep 10, 2023



Conventional wheeled robots are unable to traverse scientifically interesting, but dangerous, cave environments. Multi-limbed climbing robot designs, such as ReachBot, are able to grasp irregular surface features and execute climbing motions to overcome obstacles, given suitable grasp locations. To support grasp site identification, we present a method for detecting rock cracks and edges, the SKeleton Intersection Loss (SKIL). SKIL is a loss designed for thin object segmentation that leverages the skeleton of the label. A dataset of rock face images was collected, manually annotated, and augmented with generated data. A new group of metrics, LineAcc, has been proposed for thin object segmentation such that the impact of the object width on the score is minimized. In addition, the metric is less sensitive to translation which can often lead to a score of zero when computing classical metrics such as Dice on thin objects. Our fine-tuned models outperform previous methods on similar thin object segmentation tasks such as blood vessel segmentation and show promise for integration onto a robotic system.