 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErrorMap and ErrorAtlas: Charting the Failure Landscape of Large Language Models
Jan 22, 2026Large Language Models (LLM) benchmarks tell us when models fail, but not why they fail. A wrong answer on a reasoning dataset may stem from formatting issues, calculation errors, or dataset noise rather than weak reasoning. Without disentangling such causes, benchmarks remain incomplete and cannot reliably guide model improvement. We introduce ErrorMap, the first method to chart the sources of LLM failure. It extracts a model's unique "failure signature", clarifies what benchmarks measure, and broadens error identification to reduce blind spots. This helps developers debug models, aligns benchmark goals with outcomes, and supports informed model selection. ErrorMap works on any model or dataset with the same logic. Applying our method to 35 datasets and 83 models we generate ErrorAtlas, a taxonomy of model errors, revealing recurring failure patterns. ErrorAtlas highlights error types that are currently underexplored in LLM research, such as omissions of required details in the output and question misinterpretation. By shifting focus from where models succeed to why they fail, ErrorMap and ErrorAtlas enable advanced evaluation - one that exposes hidden weaknesses and directs progress. Unlike success, typically measured by task-level metrics, our approach introduces a deeper evaluation layer that can be applied globally across models and tasks, offering richer insights into model behavior and limitations. We make the taxonomy and code publicly available with plans to periodically update ErrorAtlas as new benchmarks and models emerge.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Judging LLMs on a Simplex
May 28, 2025Automated evaluation of free-form outputs from large language models (LLMs) is challenging because many distinct answers can be equally valid. A common practice is to use LLMs themselves as judges, but the theoretical properties of this approach are not yet well understood. We show that a geometric framework that represents both judges and candidates as points on a probability simplex can provide helpful insight on what is or is not identifiable using LLM judges. Our theoretical analysis uncovers a "phase transition" in ranking identifiability: for binary scoring systems, true rankings are identifiable even with weak judges under mild assumptions, while rankings become non-identifiable for three or more scoring levels even with infinite data, absent additional prior knowledge. This non-identifiability highlights how uncertainty in rankings stems from not only aleatoric uncertainty (i.e., inherent stochasticity in the data) but also epistemic uncertainty regarding which assumptions hold, an aspect that has received limited attention until now. To integrate both types of uncertainty, we use Bayesian inference to encode assumptions as priors and conduct sensitivity analysis of ranking estimates and credible intervals. Empirical evaluations across multiple benchmarks demonstrate that Bayesian inference yields more accurate rankings and substantially improves coverage rates. These results underscore the importance of taking a more holistic approach to uncertainty quantification when using LLMs as judges.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
SEA-HELM: Southeast Asian Holistic Evaluation of Language Models
Feb 20, 2025



With the rapid emergence of novel capabilities in Large Language Models (LLMs), the need for rigorous multilingual and multicultural benchmarks that are integrated has become more pronounced. Though existing LLM benchmarks are capable of evaluating specific capabilities of LLMs in English as well as in various mid- to low-resource languages, including those in the Southeast Asian (SEA) region, a comprehensive and authentic evaluation suite for the SEA languages has not been developed thus far. Here, we present SEA-HELM, a holistic linguistic and cultural LLM evaluation suite that emphasizes SEA languages, comprising five core pillars: (1) NLP Classics, (2) LLM-specifics, (3) SEA Linguistics, (4) SEA Culture, (5) Safety. SEA-HELM currently supports Filipino, Indonesian, Tamil, Thai, and Vietnamese. We also introduce the SEA-HELM leaderboard, which allows users to understand models' multilingual and multicultural performance in a systematic and user-friendly manner.
Image2Struct: Benchmarking Structure Extraction for Vision-Language Models
Oct 29, 2024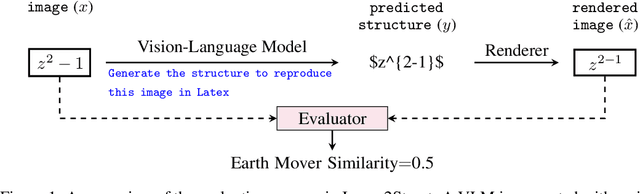

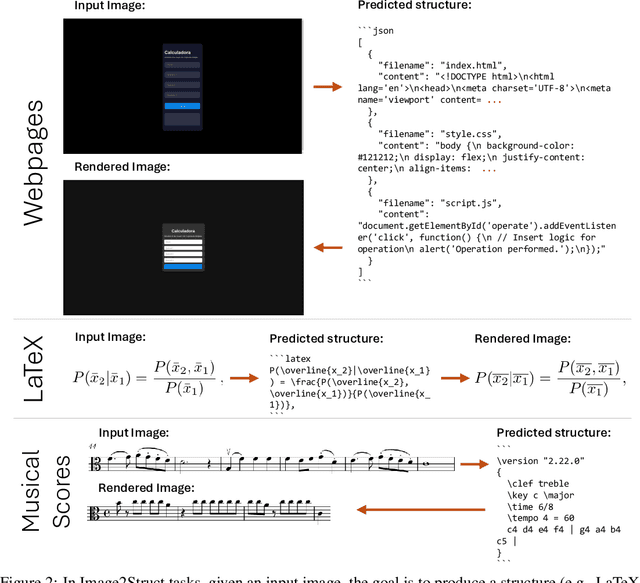
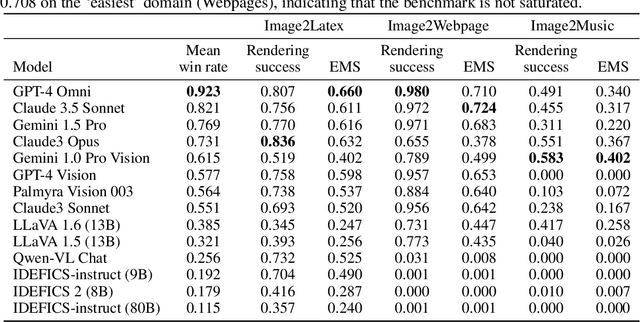
We introduce Image2Struct, a benchmark to evaluate vision-language models (VLMs) on extracting structure from images. Our benchmark 1) captures real-world use cases, 2) is fully automatic and does not require human judgment, and 3) is based on a renewable stream of fresh data. In Image2Struct, VLMs are prompted to generate the underlying structure (e.g., LaTeX code or HTML) from an input image (e.g., webpage screenshot). The structure is then rendered to produce an output image (e.g., rendered webpage), which is compared against the input image to produce a similarity score. This round-trip evaluation allows us to quantitatively evaluate VLMs on tasks with multiple valid structures. We create a pipeline that downloads fresh data from active online communities upon execution and evaluates the VLMs without human intervention. We introduce three domains (Webpages, LaTeX, and Musical Scores) and use five image metrics (pixel similarity, cosine similarity between the Inception vectors, learned perceptual image patch similarity, structural similarity index measure, and earth mover similarity) that allow efficient and automatic comparison between pairs of images. We evaluate Image2Struct on 14 prominent VLMs and find that scores vary widely, indicating that Image2Struct can differentiate between the performances of different VLMs. Additionally, the best score varies considerably across domains (e.g., 0.402 on sheet music vs. 0.830 on LaTeX equations), indicating that Image2Struct contains tasks of varying difficulty. For transparency, we release the full results at https://crfm.stanford.edu/helm/image2struct/v1.0.1/.
Language model developers should report train-test overlap
Oct 10, 2024

Language models are extensively evaluated, but correctly interpreting evaluation results requires knowledge of train-test overlap which refers to the extent to which the language model is trained on the very data it is being tested on. The public currently lacks adequate information about train-test overlap: most models have no public train-test overlap statistics, and third parties cannot directly measure train-test overlap since they do not have access to the training data. To make this clear, we document the practices of 30 model developers, finding that just 9 developers report train-test overlap: 4 developers release training data under open-source licenses, enabling the community to directly measure train-test overlap, and 5 developers publish their train-test overlap methodology and statistics. By engaging with language model developers, we provide novel information about train-test overlap for three additional developers. Overall, we take the position that language model developers should publish train-test overlap statistics and/or training data whenever they report evaluation results on public test sets. We hope our work increases transparency into train-test overlap to increase the community-wide trust in model evaluations.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.