 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
Dec 05, 2024Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.
Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training
Oct 28, 2024



Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on standard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find increasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
Stable Code Technical Report
Apr 01, 2024



We introduce Stable Code, the first in our new-generation of code language models series, which serves as a general-purpose base code language model targeting code completion, reasoning, math, and other software engineering-based tasks. Additionally, we introduce an instruction variant named Stable Code Instruct that allows conversing with the model in a natural chat interface for performing question-answering and instruction-based tasks. In this technical report, we detail the data and training procedure leading to both models. Their weights are available via Hugging Face for anyone to download and use at https://huggingface.co/stabilityai/stable-code-3b and https://huggingface.co/stabilityai/stable-code-instruct-3b. This report contains thorough evaluations of the models, including multilingual programming benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of its release, Stable Code is the state-of-the-art open model under 3B parameters and even performs comparably to larger models of sizes 7 billion and 15 billion parameters on the popular Multi-PL benchmark. Stable Code Instruct also exhibits state-of-the-art performance on the MT-Bench coding tasks and on Multi-PL completion compared to other instruction tuned models. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Stable LM 2 1.6B Technical Report
Feb 27, 2024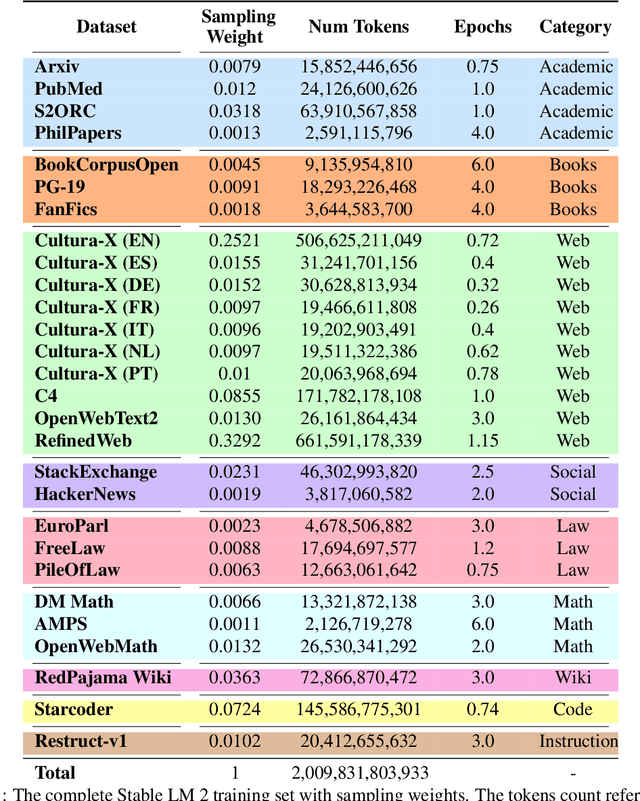
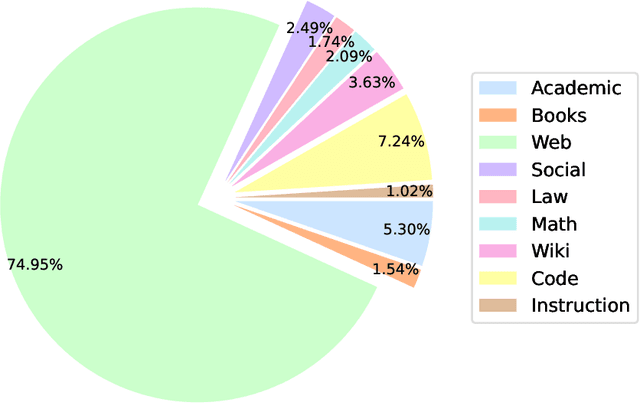
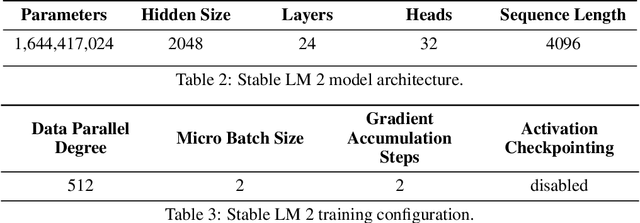
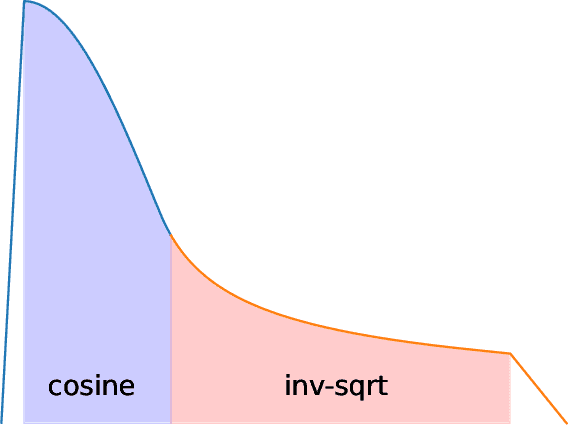
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Holistic Evaluation of Text-To-Image Models
Nov 07, 2023



The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase.
Quality-Diversity through AI Feedback
Oct 31, 2023



In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
MultiFusion: Fusing Pre-Trained Models for Multi-Lingual, Multi-Modal Image Generation
May 24, 2023The recent popularity of text-to-image diffusion models (DM) can largely be attributed to the intuitive interface they provide to users. The intended generation can be expressed in natural language, with the model producing faithful interpretations of text prompts. However, expressing complex or nuanced ideas in text alone can be difficult. To ease image generation, we propose MultiFusion that allows one to express complex and nuanced concepts with arbitrarily interleaved inputs of multiple modalities and languages. MutliFusion leverages pre-trained models and aligns them for integration into a cohesive system, thereby avoiding the need for extensive training from scratch. Our experimental results demonstrate the efficient transfer of capabilities from individual modules to the downstream model. Specifically, the fusion of all independent components allows the image generation module to utilize multilingual, interleaved multimodal inputs despite being trained solely on monomodal data in a single language.
M-VADER: A Model for Diffusion with Multimodal Context
Dec 07, 2022We introduce M-VADER: a diffusion model (DM) for image generation where the output can be specified using arbitrary combinations of images and text. We show how M-VADER enables the generation of images specified using combinations of image and text, and combinations of multiple images. Previously, a number of successful DM image generation algorithms have been introduced that make it possible to specify the output image using a text prompt. Inspired by the success of those models, and led by the notion that language was already developed to describe the elements of visual contexts that humans find most important, we introduce an embedding model closely related to a vision-language model. Specifically, we introduce the embedding model S-MAGMA: a 13 billion parameter multimodal decoder combining components from an autoregressive vision-language model MAGMA and biases finetuned for semantic search.
Latent Space Refinement for Deep Generative Models
Jun 01, 2021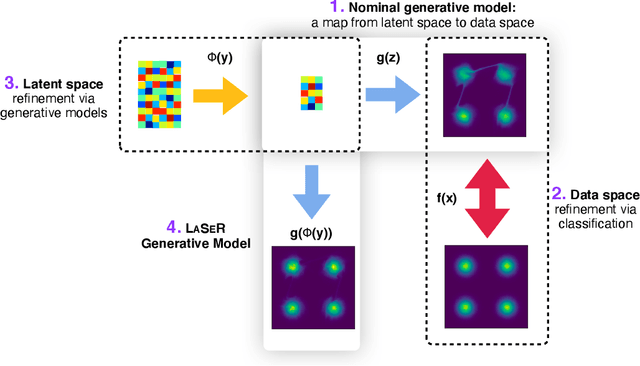

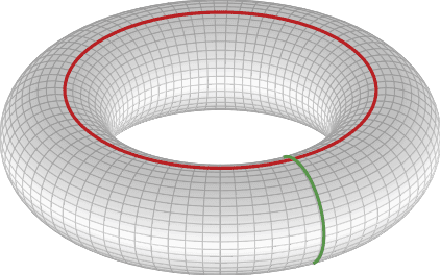

Deep generative models are becoming widely used across science and industry for a variety of purposes. A common challenge is achieving a precise implicit or explicit representation of the data probability density. Recent proposals have suggested using classifier weights to refine the learned density of deep generative models. We extend this idea to all types of generative models and show how latent space refinement via iterated generative modeling can circumvent topological obstructions and improve precision. This methodology also applies to cases were the target model is non-differentiable and has many internal latent dimensions which must be marginalized over before refinement. We demonstrate our Latent Space Refinement (LaSeR) protocol on a variety of examples, focusing on the combinations of Normalizing Flows and Generative Adversarial Networks.