 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Engineering Scaling Laws with Pretraining Data Composition
Jun 18, 2026Neural scaling laws describe how model performance improves as a power law in compute, model size, and dataset size. While well-established for large language models, these relationships are emerging for large models in particle physics. As with language, empirical studies show that the performance scales as a power law. However, unlike natural language or image domains, fundamental physics has high-fidelity simulators that produce synthetic data cheaply. This favors scaling regimes where additional data is cheaper than additional parameters, and allows the pretraining dataset itself to be engineered to influence the scaling. For the task of classifying hadronic jets produced in collisions of high-energy particle beams, we show that the scaling behavior can be engineered towards requiring more data rather than larger models by inclusion of pretraining data which is more diverse and better aligned with the downstream classification task.
Pre-Training for Simulation-Based Science: A Study on Jet Foundation Model Training Objectives
Jun 12, 2026Foundation models (FMs) trained on large datasets and fine-tuned on downstream tasks have emerged as a powerful paradigm in AI for science. Industrial FMs are typically trained using self-supervision with masking due to the lack of labels. In many scientific domains, accurate simulations are plentiful and facilitate large, labeled datasets. This opens up new possibilities for pre-training. We present a systematic comparison of pre-training methods using the OmniLearned High Energy Physics FM framework. We test supervised classification, flow-matching generation, and self-supervised masked particle modeling. All models are pre-trained on the JetClass dataset and fine-tuned on two representative downstream tasks, top jet classification and JetNet conditional generation. Among other observations, for classification tasks, we find that pure classifier pre-training is optimal when downstream labels and model capacity are plentiful, but combining it with self-supervised masked particle modeling (MPM) is uniquely powerful in the low-finetuning label regime. Flow matching-based generative pre-training seems to provide little benefit for downstream classification, and interestingly, for downstream generation, we find that flow matching must be in the pre-training objective to see a significant finetuning advantage, hinting at the orthogonality of classification and generation tasks. That is, for a model to transfer to both generative and classification downstream tasks, it must be pre-trained on both. This study provides a template for controlled scaling analysis of pre-training objectives for foundation models in simulation-based sciences.
FAIR Universe Weak Lensing ML Uncertainty Challenge: Handling Uncertainties and Distribution Shifts for Precision Cosmology
Apr 15, 2026Weak gravitational lensing, the correlated distortion of background galaxy shapes by foreground structures, is a powerful probe of the matter distribution in our universe and allows accurate constraints on the cosmological model. In recent years, high-order statistics and machine learning (ML) techniques have been applied to weak lensing data to extract the nonlinear information beyond traditional two-point analysis. However, these methods typically rely on cosmological simulations, which poses several challenges: simulations are computationally expensive, limiting most realistic setups to a low training data regime; inaccurate modeling of systematics in the simulations create distribution shifts that can bias cosmological parameter constraints; and varying simulation setups across studies make method comparison difficult. To address these difficulties, we present the first weak lensing benchmark dataset with several realistic systematics and launch the FAIR Universe Weak Lensing Machine Learning Uncertainty Challenge. The challenge focuses on measuring the fundamental properties of the universe from weak lensing data with limited training set and potential distribution shifts, while providing a standardized benchmark for rigorous comparison across methods. Organized in two phases, the challenge will bring together the physics and ML communities to advance the methodologies for handling systematic uncertainties, data efficiency, and distribution shifts in weak lensing analysis with ML, ultimately facilitating the deployment of ML approaches into upcoming weak lensing survey analysis.
Cross-Domain Transfer with Particle Physics Foundation Models: From Jets to Neutrino Interactions
Apr 14, 2026Future AI-based studies in particle physics will likely start from a foundation model to accelerate training and enhance sensitivity. As a step towards a general-purpose foundation model for particle physics, we investigate whether the OmniLearned foundation model pre-trained on diverse high-$Q^2$ simulated and real $pp$ and $ep$ collisions can be effectively transferred to a few-GeV fixed-target neutrino experiment. We process MINERvA neutrino--nucleus scattering events and evaluate pre-trained models on two types of tasks: regression of available energy and binary classification of charged-current pion final states ($\mathrm{CC1π^{\pm}}$, $\mathrm{CCNπ^{\pm}}$, and $\mathrm{CC1π^{0}}$). Pre-trained OmniLearned models consistently outperform similarly sized models trained from scratch, achieving better overall performance at the same compute budget, as well as achieving better performance at the same number of training steps. These results suggest that particle-level foundation models acquire inductive biases that generalize across large differences in energy scale, detector technology, and underlying physics processes, pointing toward a paradigm of detector-agnostic inference in particle physics.
Generalizable Foundation Models for Calorimetry via Mixtures-of-Experts and Parameter Efficient Fine Tuning
Mar 27, 2026Modern particle physics experiments face an increasing demand for high-fidelity detector simulation as luminosities rise and computational requirements approach the limits of available resources. Deep generative models have emerged as promising surrogates for traditional Monte Carlo simulation, with recent advances drawing inspiration from large language models (LLM) and next-token prediction paradigms. In this work, we introduce a generalizable foundation model for calorimetry built on next-token transformer backbones, designed to support modular adaptation across materials, particle species, and detector configurations. Our approach combines Mixture-of-Experts pre-training with parameter-efficient fine-tuning strategies to enable controlled, additive model expansion without catastrophic forgetting. A pre-trained backbone is trained to generate electromagnetic showers across multiple absorber materials, while new materials are incorporated through the addition and tuning of lightweight expert modules. Extensions to new particle types are achieved via parameter-efficient fine-tuning and modular vocabularies, preserving the integrity of the base model. This design enables efficient, incremental knowledge integration as new simulation datasets become available, a critical requirement in realistic detector-development workflows. In addition, we demonstrate that next-token calorimeter models are computationally competitive with standard generative approaches under established LLM optimization procedures. These results establish next-token architectures as a viable path toward extensible, physics-aware foundation models for calorimetry and future high-energy physics experiments.
Unfolding with a Wasserstein Loss
Mar 21, 2026Data unfolding -- the removal of noise or artifacts from measurements -- is a fundamental task across the experimental sciences. Of particular interest are applications in physics, where the dominant approach is Richardson-Lucy (RL) deconvolution. The classical RL approach aims to find denoised data that, once passed through the noise model, is as close as possible to the measured data in terms of Kullback-Leibler (KL) divergence. This requires that the support of the measured data overlaps with the output of the noise model, a hypothesis typically enforced by binning, which introduces numerical error. As a counterpoint, the present work studies an alternative formulation using a Wasserstein loss. We establish sharp conditions for existence and uniqueness of optimizers, answering open questions of Li, et al., regarding necessary conditions for existence and uniqueness in the case of transport map noise models. We then develop a provably convergent generalized Sinkhorn algorithm to compute approximate optimizers. Our algorithm requires only empirical observations of the noise model and measured data and scales with the size of the data, rather than the ambient dimension. Numerical experiments on one- and two-dimensional problems inspired by jet mass unfolding in particle physics demonstrate that the optimal transport approach offers robust, accurate performance compared to classical RL deconvolution, particularly when binning artifacts are significant.
EveNet: A Foundation Model for Particle Collision Data Analysis
Jan 23, 2026While deep learning is transforming data analysis in high-energy physics, computational challenges limit its potential. We address these challenges in the context of collider physics by introducing EveNet, an event-level foundation model pretrained on 500 million simulated collision events using a hybrid objective of self-supervised learning and physics-informed supervision. By leveraging a shared particle-cloud representation, EveNet outperforms state-of-the-art baselines across diverse tasks, including searches for heavy resonances and exotic Higgs decays, and demonstrates exceptional data efficiency in low-statistics regimes. Crucially, we validate the transferability of the model to experimental data by rediscovering the $Υ$ meson in CMS Open Data and show its capacity for precision physics through the robust extraction of quantum correlation observables stable against systematic uncertainties. These results indicate that EveNet can successfully encode the fundamental physical structure of particle interactions, which offers a unified and resource-efficient framework to accelerate discovery at current and future colliders.
Discriminative versus Generative Approaches to Simulation-based Inference
Mar 11, 2025Most of the fundamental, emergent, and phenomenological parameters of particle and nuclear physics are determined through parametric template fits. Simulations are used to populate histograms which are then matched to data. This approach is inherently lossy, since histograms are binned and low-dimensional. Deep learning has enabled unbinned and high-dimensional parameter estimation through neural likelihiood(-ratio) estimation. We compare two approaches for neural simulation-based inference (NSBI): one based on discriminative learning (classification) and one based on generative modeling. These two approaches are directly evaluated on the same datasets, with a similar level of hyperparameter optimization in both cases. In addition to a Gaussian dataset, we study NSBI using a Higgs boson dataset from the FAIR Universe Challenge. We find that both the direct likelihood and likelihood ratio estimation are able to effectively extract parameters with reasonable uncertainties. For the numerical examples and within the set of hyperparameters studied, we found that the likelihood ratio method is more accurate and/or precise. Both methods have a significant spread from the network training and would require ensembling or other mitigation strategies in practice.
Generative Unfolding with Distribution Mapping
Nov 04, 2024



Machine learning enables unbinned, highly-differential cross section measurements. A recent idea uses generative models to morph a starting simulation into the unfolded data. We show how to extend two morphing techniques, Schr\"odinger Bridges and Direct Diffusion, in order to ensure that the models learn the correct conditional probabilities. This brings distribution mapping to a similar level of accuracy as the state-of-the-art conditional generative unfolding methods. Numerical results are presented with a standard benchmark dataset of single jet substructure as well as for a new dataset describing a 22-dimensional phase space of Z + 2-jets.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024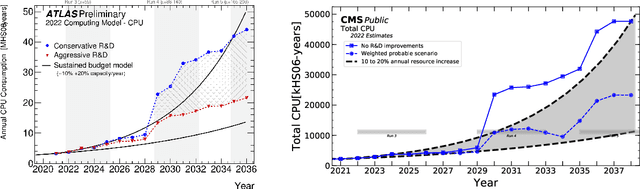
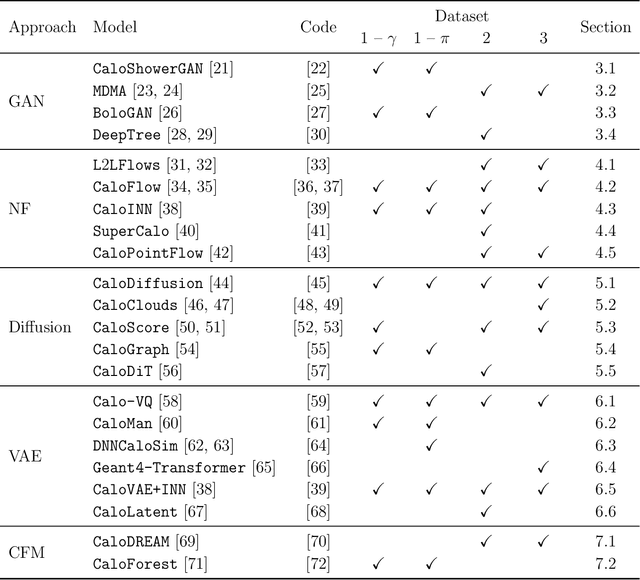
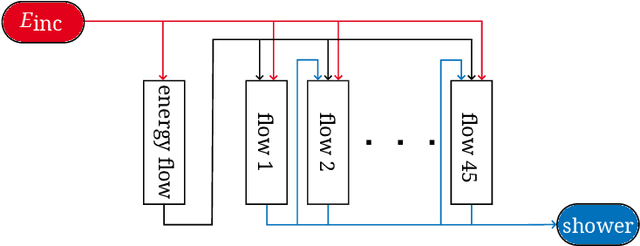
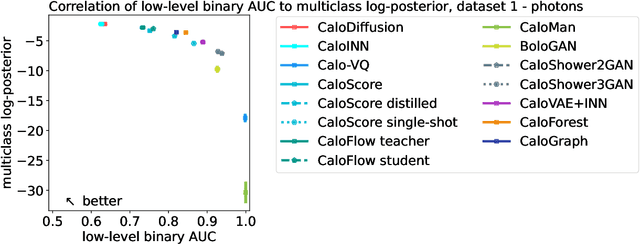
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.