 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024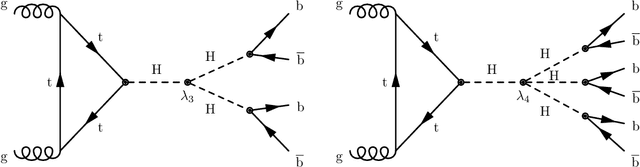



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
The Landscape of Unfolding with Machine Learning
Apr 29, 2024



Recent innovations from machine learning allow for data unfolding, without binning and including correlations across many dimensions. We describe a set of known, upgraded, and new methods for ML-based unfolding. The performance of these approaches are evaluated on the same two datasets. We find that all techniques are capable of accurately reproducing the particle-level spectra across complex observables. Given that these approaches are conceptually diverse, they offer an exciting toolkit for a new class of measurements that can probe the Standard Model with an unprecedented level of detail and may enable sensitivity to new phenomena.
End-To-End Latent Variational Diffusion Models for Inverse Problems in High Energy Physics
May 17, 2023



High-energy collisions at the Large Hadron Collider (LHC) provide valuable insights into open questions in particle physics. However, detector effects must be corrected before measurements can be compared to certain theoretical predictions or measurements from other detectors. Methods to solve this \textit{inverse problem} of mapping detector observations to theoretical quantities of the underlying collision are essential parts of many physics analyses at the LHC. We investigate and compare various generative deep learning methods to approximate this inverse mapping. We introduce a novel unified architecture, termed latent variation diffusion models, which combines the latent learning of cutting-edge generative art approaches with an end-to-end variational framework. We demonstrate the effectiveness of this approach for reconstructing global distributions of theoretical kinematic quantities, as well as for ensuring the adherence of the learned posterior distributions to known physics constraints. Our unified approach achieves a distribution-free distance to the truth of over 20 times less than non-latent state-of-the-art baseline and 3 times less than traditional latent diffusion models.
PonyGE2: Grammatical Evolution in Python
Apr 26, 2017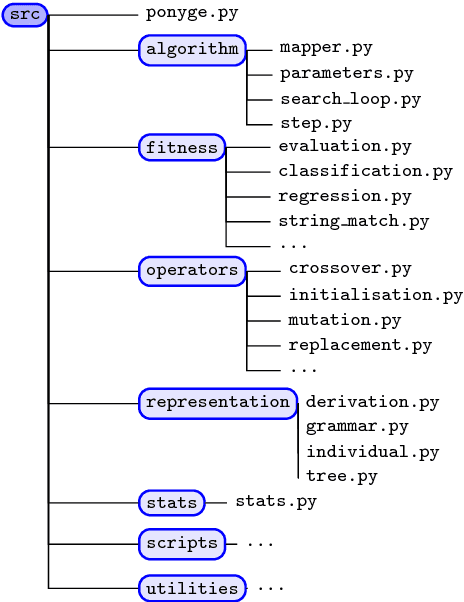
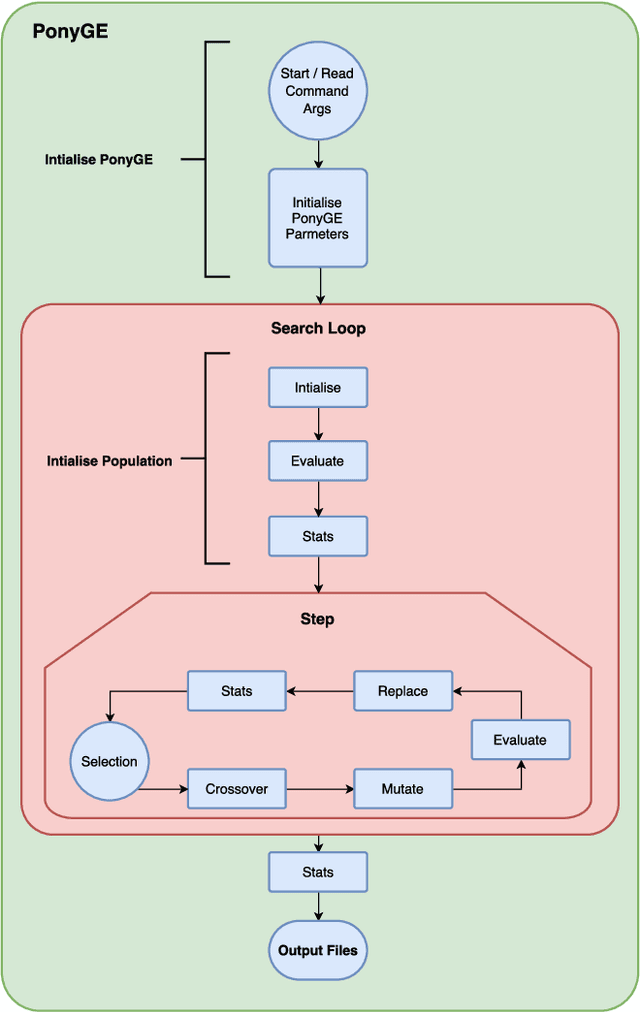
Grammatical Evolution (GE) is a population-based evolutionary algorithm, where a formal grammar is used in the genotype to phenotype mapping process. PonyGE2 is an open source implementation of GE in Python, developed at UCD's Natural Computing Research and Applications group. It is intended as an advertisement and a starting-point for those new to GE, a reference for students and researchers, a rapid-prototyping medium for our own experiments, and a Python workout. As well as providing the characteristic genotype to phenotype mapping of GE, a search algorithm engine is also provided. A number of sample problems and tutorials on how to use and adapt PonyGE2 have been developed.
* 8 pages, 4 figures, submitted to the 2017 GECCO Workshop on Evolutionary Computation Software Systems (EvoSoft)
A Search for Improved Performance in Regular Expressions
Apr 13, 2017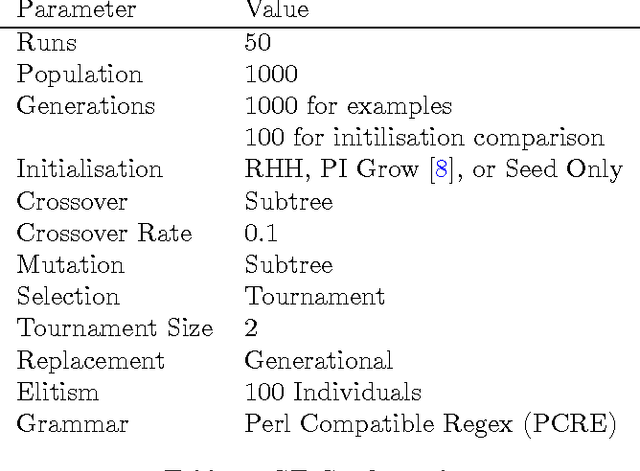
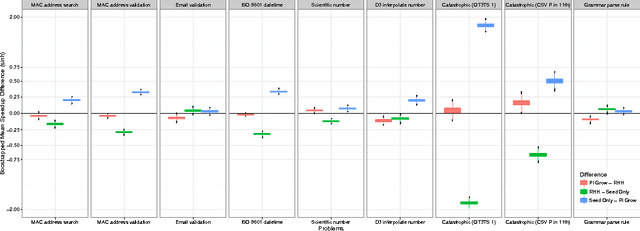


The primary aim of automated performance improvement is to reduce the running time of programs while maintaining (or improving on) functionality. In this paper, Genetic Programming is used to find performance improvements in regular expressions for an array of target programs, representing the first application of automated software improvement for run-time performance in the Regular Expression language. This particular problem is interesting as there may be many possible alternative regular expressions which perform the same task while exhibiting subtle differences in performance. A benchmark suite of candidate regular expressions is proposed for improvement. We show that the application of Genetic Programming techniques can result in performance improvements in all cases. As we start evolution from a known good regular expression, diversity is critical in escaping the local optima of the seed expression. In order to understand diversity during evolution we compare an initial population consisting of only seed programs with a population initialised using a combination of a single seed individual with individuals generated using PI Grow and Ramped-half-and-half initialisation mechanisms.