 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Broken Symmetries with Approximate Invariance
Dec 25, 2024Recognizing symmetries in data allows for significant boosts in neural network training, which is especially important where training data are limited. In many cases, however, the exact underlying symmetry is present only in an idealized dataset, and is broken in actual data, due to asymmetries in the detector, or varying response resolution as a function of particle momentum. Standard approaches, such as data augmentation or equivariant networks fail to represent the nature of the full, broken symmetry, effectively overconstraining the response of the neural network. We propose a learning model which balances the generality and asymptotic performance of unconstrained networks with the rapid learning of constrained networks. This is achieved through a dual-subnet structure, where one network is constrained by the symmetry and the other is not, along with a learned symmetry factor. In a simplified toy example that demonstrates violation of Lorentz invariance, our model learns as rapidly as symmetry-constrained networks but escapes its performance limitations.
Reconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024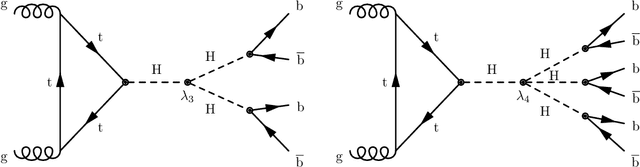



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
The Landscape of Unfolding with Machine Learning
Apr 29, 2024



Recent innovations from machine learning allow for data unfolding, without binning and including correlations across many dimensions. We describe a set of known, upgraded, and new methods for ML-based unfolding. The performance of these approaches are evaluated on the same two datasets. We find that all techniques are capable of accurately reproducing the particle-level spectra across complex observables. Given that these approaches are conceptually diverse, they offer an exciting toolkit for a new class of measurements that can probe the Standard Model with an unprecedented level of detail and may enable sensitivity to new phenomena.
Full Event Particle-Level Unfolding with Variable-Length Latent Variational Diffusion
Apr 22, 2024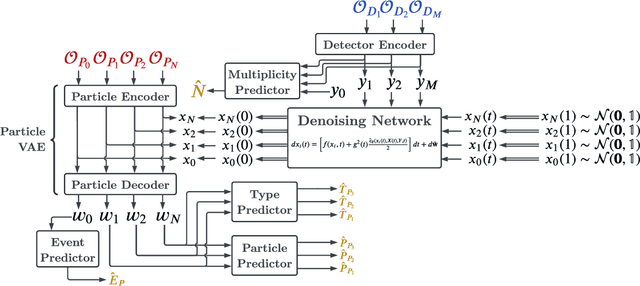

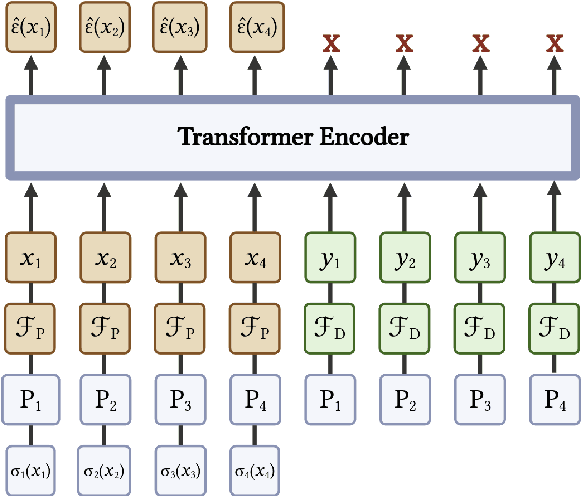

The measurements performed by particle physics experiments must account for the imperfect response of the detectors used to observe the interactions. One approach, unfolding, statistically adjusts the experimental data for detector effects. Recently, generative machine learning models have shown promise for performing unbinned unfolding in a high number of dimensions. However, all current generative approaches are limited to unfolding a fixed set of observables, making them unable to perform full-event unfolding in the variable dimensional environment of collider data. A novel modification to the variational latent diffusion model (VLD) approach to generative unfolding is presented, which allows for unfolding of high- and variable-dimensional feature spaces. The performance of this method is evaluated in the context of semi-leptonic top quark pair production at the Large Hadron Collider.
Extended Symmetry Preserving Attention Networks for LHC Analysis
Sep 05, 2023Reconstructing unstable heavy particles requires sophisticated techniques to sift through the large number of possible permutations for assignment of detector objects to partons. An approach based on a generalized attention mechanism, symmetry preserving attention networks (SPANet), has been previously applied to top quark pair decays at the Large Hadron Collider, which produce six hadronic jets. Here we extend the SPANet architecture to consider multiple input streams, such as leptons, as well as global event features, such as the missing transverse momentum. In addition, we provide regression and classification outputs to supplement the parton assignment. We explore the performance of the extended capability of SPANet in the context of semi-leptonic decays of top quark pairs as well as top quark pairs produced in association with a Higgs boson. We find significant improvements in the power of three representative studies: search for ttH, measurement of the top quark mass and a search for a heavy Z' decaying to top quark pairs. We present ablation studies to provide insight on what the network has learned in each case.
Generalizing to new calorimeter geometries with Geometry-Aware Autoregressive Models (GAAMs) for fast calorimeter simulation
May 19, 2023Generation of simulated detector response to collision products is crucial to data analysis in particle physics, but computationally very expensive. One subdetector, the calorimeter, dominates the computational time due to the high granularity of its cells and complexity of the interaction. Generative models can provide more rapid sample production, but currently require significant effort to optimize performance for specific detector geometries, often requiring many networks to describe the varying cell sizes and arrangements, which do not generalize to other geometries. We develop a {\it geometry-aware} autoregressive model, which learns how the calorimeter response varies with geometry, and is capable of generating simulated responses to unseen geometries without additional training. The geometry-aware model outperforms a baseline, unaware model by 50\% in metrics such as the Wasserstein distance between generated and true distributions of key quantities which summarize the simulated response. A single geometry-aware model could replace the hundreds of generative models currently designed for calorimeter simulation by physicists analyzing data collected at the Large Hadron Collider. For the study of future detectors, such a foundational model will be a crucial tool, dramatically reducing the large upfront investment usually needed to develop generative calorimeter models.
End-To-End Latent Variational Diffusion Models for Inverse Problems in High Energy Physics
May 17, 2023High-energy collisions at the Large Hadron Collider (LHC) provide valuable insights into open questions in particle physics. However, detector effects must be corrected before measurements can be compared to certain theoretical predictions or measurements from other detectors. Methods to solve this \textit{inverse problem} of mapping detector observations to theoretical quantities of the underlying collision are essential parts of many physics analyses at the LHC. We investigate and compare various generative deep learning methods to approximate this inverse mapping. We introduce a novel unified architecture, termed latent variation diffusion models, which combines the latent learning of cutting-edge generative art approaches with an end-to-end variational framework. We demonstrate the effectiveness of this approach for reconstructing global distributions of theoretical kinematic quantities, as well as for ensuring the adherence of the learned posterior distributions to known physics constraints. Our unified approach achieves a distribution-free distance to the truth of over 20 times less than non-latent state-of-the-art baseline and 3 times less than traditional latent diffusion models.
Geometry-aware Autoregressive Models for Calorimeter Shower Simulations
Dec 16, 2022Calorimeter shower simulations are often the bottleneck in simulation time for particle physics detectors. A lot of effort is currently spent on optimizing generative architectures for specific detector geometries, which generalize poorly. We develop a geometry-aware autoregressive model on a range of calorimeter geometries such that the model learns to adapt its energy deposition depending on the size and position of the cells. This is a key proof-of-concept step towards building a model that can generalize to new unseen calorimeter geometries with little to no additional training. Such a model can replace the hundreds of generative models used for calorimeter simulation in a Large Hadron Collider experiment. For the study of future detectors, such a model will dramatically reduce the large upfront investment usually needed to generate simulations.
Snowmass 2021 Computational Frontier CompF03 Topical Group Report: Machine Learning
Sep 15, 2022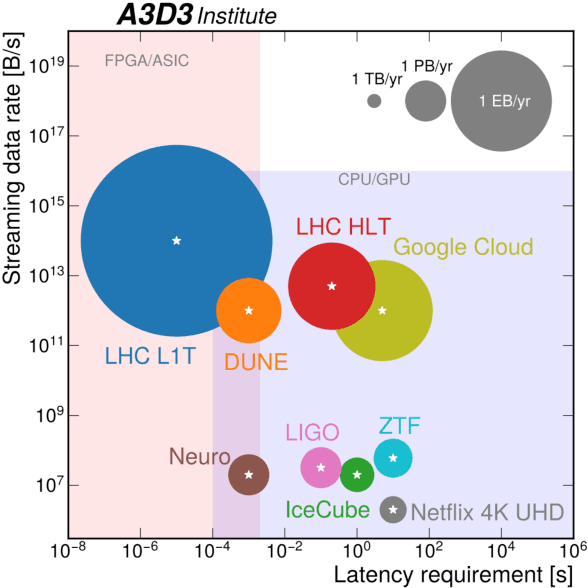
The rapidly-developing intersection of machine learning (ML) with high-energy physics (HEP) presents both opportunities and challenges to our community. Far beyond applications of standard ML tools to HEP problems, genuinely new and potentially revolutionary approaches are being developed by a generation of talent literate in both fields. There is an urgent need to support the needs of the interdisciplinary community driving these developments, including funding dedicated research at the intersection of the two fields, investing in high-performance computing at universities and tailoring allocation policies to support this work, developing of community tools and standards, and providing education and career paths for young researchers attracted by the intellectual vitality of machine learning for high energy physics.
SPANet: Generalized Permutationless Set Assignment for Particle Physics using Symmetry Preserving Attention
Jun 07, 2021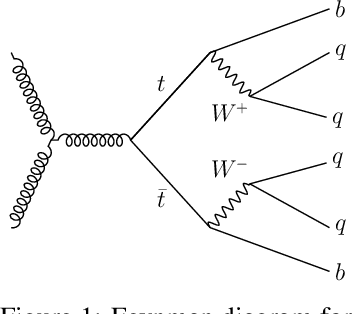
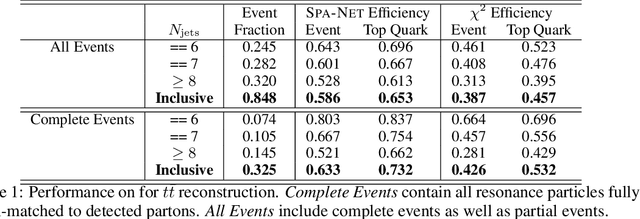
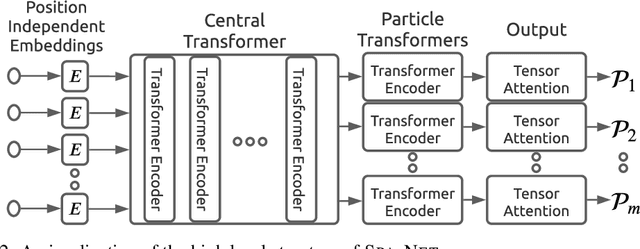
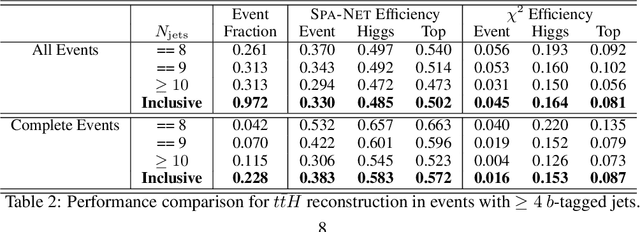
The creation of unstable heavy particles at the Large Hadron Collider is the most direct way to address some of the deepest open questions in physics. Collisions typically produce variable-size sets of observed particles which have inherent ambiguities complicating the assignment of observed particles to the decay products of the heavy particles. Current strategies for tackling these challenges in the physics community ignore the physical symmetries of the decay products and consider all possible assignment permutations and do not scale to complex configurations. Attention based deep learning methods for sequence modelling have achieved state-of-the-art performance in natural language processing, but they lack built-in mechanisms to deal with the unique symmetries found in physical set-assignment problems. We introduce a novel method for constructing symmetry-preserving attention networks which reflect the problem's natural invariances to efficiently find assignments without evaluating all permutations. This general approach is applicable to arbitrarily complex configurations and significantly outperforms current methods, improving reconstruction efficiency between 19\% - 35\% on typical benchmark problems while decreasing inference time by two to five orders of magnitude on the most complex events, making many important and previously intractable cases tractable. A full code repository containing a general library, the specific configuration used, and a complete dataset release, are avaiable at https://github.com/Alexanders101/SPANet