 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models and Statistical Validation
May 28, 2026Generative machine learning has become an essential tool in theoretical and experimental physics, especially in the context of fast surrogates and density estimators. In this work, we first introduce the underlying framework of modern generative networks and then discuss challenges in quantifying their accuracy, precision, and statistical power.
Neural Scaling Laws for Jet Generation
May 27, 2026Recently observed empirical scaling laws describe the performance of foundation-type models as three independent key quantities -- dataset size, compute, and model parameters -- are modified. Extracting these scaling laws informs the training of large complex models for which the tuning of hyperparameters in traditional ways is not feasible. This work for the first time explores if scaling laws can also be observed for the task of particle jet generation -- both relevant as a pre-training objective for foundation models and as in-situ simulation by itself. We indeed replicate the key logarithmic scaling law behavior for model-size scaling. Beyond studying the next token prediction validation loss of the generative model, we also study the sliced Wasserstein distance of five physical quantities that are not immediately available to the model during training. Our study shows that this quantity is monotonically related to the next token prediction validation loss, meaning that this loss is indeed a good proxy for the physics performance. For the scaling with dataset size and compute, we observe substantially weaker scaling behavior of both the loss and the sliced Wasserstein distance. We analyze this behavior by introducing the concept of a learnable window, and argue that autoregressive next token prediction on jet constituents exhibits comparatively rapid saturation relative to language-model studies. We discuss possible origins of this behavior, including the stochastic nature of QCD radiation and differences between generative and supervised learning tasks in collider physics.
AllShowers: One model for all calorimeter showers
Jan 16, 2026Accurate and efficient detector simulation is essential for modern collider experiments. To reduce the high computational cost, various fast machine learning surrogate models have been proposed. Traditional surrogate models for calorimeter shower modeling train separate networks for each particle species, limiting scalability and reuse. We introduce AllShowers, a unified generative model that simulates calorimeter showers across multiple particle types using a single generative model. AllShowers is a continuous normalizing flow model with a Transformer architecture, enabling it to generate complex spatial and energy correlations in variable-length point cloud representations of showers. Trained on a diverse dataset of simulated showers in the highly granular ILD detector, the model demonstrates the ability to generate realistic showers for electrons, photons, and charged and neutral hadrons across a wide range of incident energies and angles without retraining. In addition to unifying shower generation for multiple particle types, AllShowers surpasses the fidelity of previous single-particle-type models for hadronic showers. Key innovations include the use of a layer embedding, allowing the model to learn all relevant calorimeter layer properties; a custom attention masking scheme to reduce computational demands and introduce a helpful inductive bias; and a shower- and layer-wise optimal transport mapping to improve training convergence and sample quality. AllShowers marks a significant step towards a universal model for calorimeter shower simulations in collider experiments.
How to pick the best anomaly detector?
Nov 18, 2025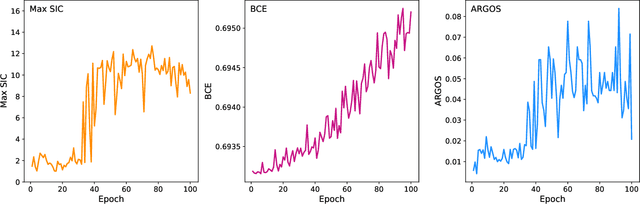
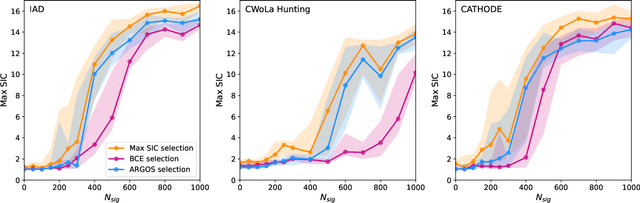
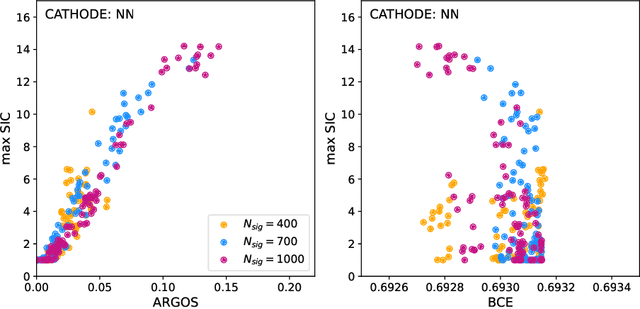
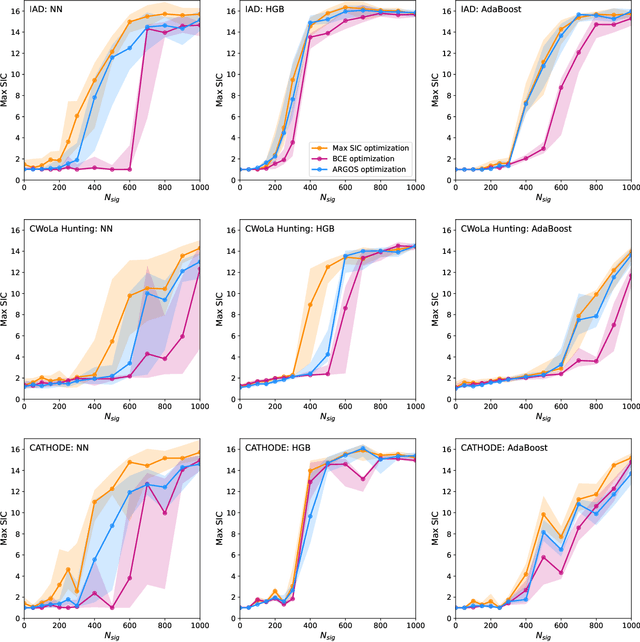
Anomaly detection has the potential to discover new physics in unexplored regions of the data. However, choosing the best anomaly detector for a given data set in a model-agnostic way is an important challenge which has hitherto largely been neglected. In this paper, we introduce the data-driven ARGOS metric, which has a sound theoretical foundation and is empirically shown to robustly select the most sensitive anomaly detection model given the data. Focusing on weakly-supervised, classifier-based anomaly detection methods, we show that the ARGOS metric outperforms other model selection metrics previously used in the literature, in particular the binary cross-entropy loss. We explore several realistic applications, including hyperparameter tuning as well as architecture and feature selection, and in all cases we demonstrate that ARGOS is robust to the noisy conditions of anomaly detection.
Agents of Discovery
Sep 10, 2025The substantial data volumes encountered in modern particle physics and other domains of fundamental physics research allow (and require) the use of increasingly complex data analysis tools and workflows. While the use of machine learning (ML) tools for data analysis has recently proliferated, these tools are typically special-purpose algorithms that rely, for example, on encoded physics knowledge to reach optimal performance. In this work, we investigate a new and orthogonal direction: Using recent progress in large language models (LLMs) to create a team of agents -- instances of LLMs with specific subtasks -- that jointly solve data analysis-based research problems in a way similar to how a human researcher might: by creating code to operate standard tools and libraries (including ML systems) and by building on results of previous iterations. If successful, such agent-based systems could be deployed to automate routine analysis components to counteract the increasing complexity of modern tool chains. To investigate the capabilities of current-generation commercial LLMs, we consider the task of anomaly detection via the publicly available and highly-studied LHC Olympics dataset. Several current models by OpenAI (GPT-4o, o4-mini, GPT-4.1, and GPT-5) are investigated and their stability tested. Overall, we observe the capacity of the agent-based system to solve this data analysis problem. The best agent-created solutions mirror the performance of human state-of-the-art results.
OmniJet-${α_{ C}}$: Learning point cloud calorimeter simulations using generative transformers
Jan 09, 2025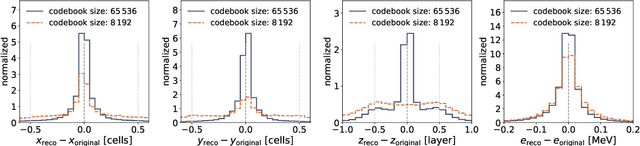
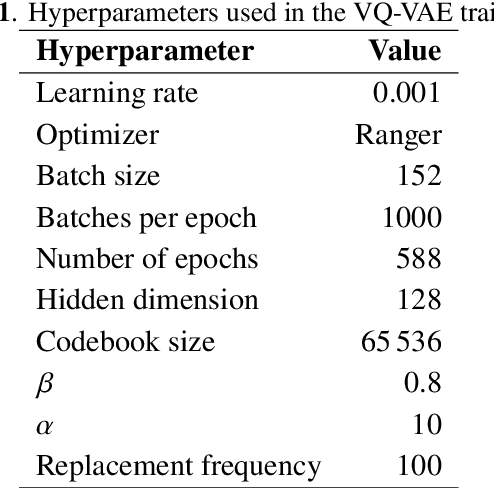
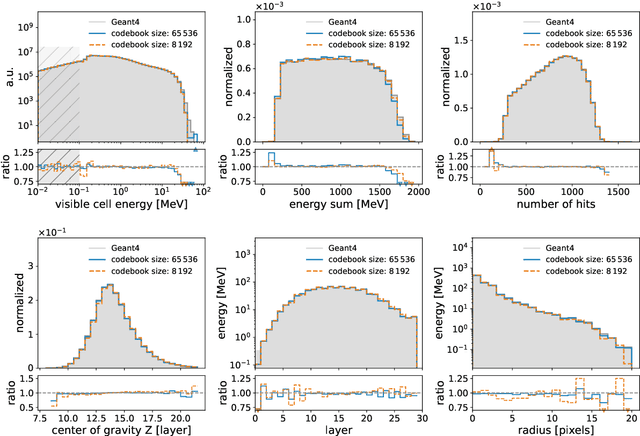
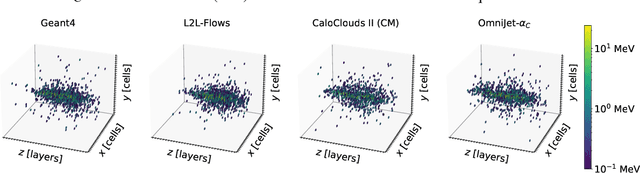
We show the first use of generative transformers for generating calorimeter showers as point clouds in a high-granularity calorimeter. Using the tokenizer and generative part of the OmniJet-${\alpha}$ model, we represent the hits in the detector as sequences of integers. This model allows variable-length sequences, which means that it supports realistic shower development and does not need to be conditioned on the number of hits. Since the tokenization represents the showers as point clouds, the model learns the geometry of the showers without being restricted to any particular voxel grid.
Large Physics Models: Towards a collaborative approach with Large Language Models and Foundation Models
Jan 09, 2025

This paper explores ideas and provides a potential roadmap for the development and evaluation of physics-specific large-scale AI models, which we call Large Physics Models (LPMs). These models, based on foundation models such as Large Language Models (LLMs) - trained on broad data - are tailored to address the demands of physics research. LPMs can function independently or as part of an integrated framework. This framework can incorporate specialized tools, including symbolic reasoning modules for mathematical manipulations, frameworks to analyse specific experimental and simulated data, and mechanisms for synthesizing theories and scientific literature. We begin by examining whether the physics community should actively develop and refine dedicated models, rather than relying solely on commercial LLMs. We then outline how LPMs can be realized through interdisciplinary collaboration among experts in physics, computer science, and philosophy of science. To integrate these models effectively, we identify three key pillars: Development, Evaluation, and Philosophical Reflection. Development focuses on constructing models capable of processing physics texts, mathematical formulations, and diverse physical data. Evaluation assesses accuracy and reliability by testing and benchmarking. Finally, Philosophical Reflection encompasses the analysis of broader implications of LLMs in physics, including their potential to generate new scientific understanding and what novel collaboration dynamics might arise in research. Inspired by the organizational structure of experimental collaborations in particle physics, we propose a similarly interdisciplinary and collaborative approach to building and refining Large Physics Models. This roadmap provides specific objectives, defines pathways to achieve them, and identifies challenges that must be addressed to realise physics-specific large scale AI models.
Learning Broken Symmetries with Approximate Invariance
Dec 25, 2024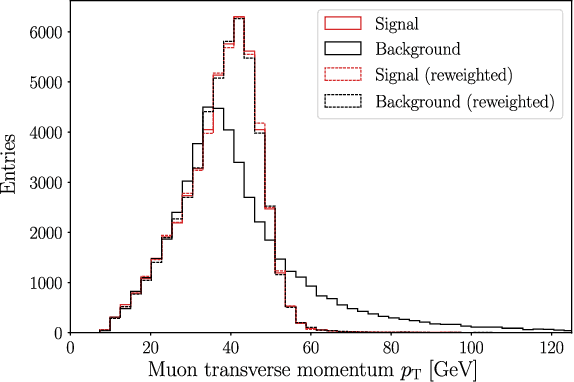



Recognizing symmetries in data allows for significant boosts in neural network training, which is especially important where training data are limited. In many cases, however, the exact underlying symmetry is present only in an idealized dataset, and is broken in actual data, due to asymmetries in the detector, or varying response resolution as a function of particle momentum. Standard approaches, such as data augmentation or equivariant networks fail to represent the nature of the full, broken symmetry, effectively overconstraining the response of the neural network. We propose a learning model which balances the generality and asymptotic performance of unconstrained networks with the rapid learning of constrained networks. This is achieved through a dual-subnet structure, where one network is constrained by the symmetry and the other is not, along with a learned symmetry factor. In a simplified toy example that demonstrates violation of Lorentz invariance, our model learns as rapidly as symmetry-constrained networks but escapes its performance limitations.
Aspen Open Jets: Unlocking LHC Data for Foundation Models in Particle Physics
Dec 13, 2024Foundation models are deep learning models pre-trained on large amounts of data which are capable of generalizing to multiple datasets and/or downstream tasks. This work demonstrates how data collected by the CMS experiment at the Large Hadron Collider can be useful in pre-training foundation models for HEP. Specifically, we introduce the AspenOpenJets dataset, consisting of approximately 180M high $p_T$ jets derived from CMS 2016 Open Data. We show how pre-training the OmniJet-$\alpha$ foundation model on AspenOpenJets improves performance on generative tasks with significant domain shift: generating boosted top and QCD jets from the simulated JetClass dataset. In addition to demonstrating the power of pre-training of a jet-based foundation model on actual proton-proton collision data, we provide the ML-ready derived AspenOpenJets dataset for further public use.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024
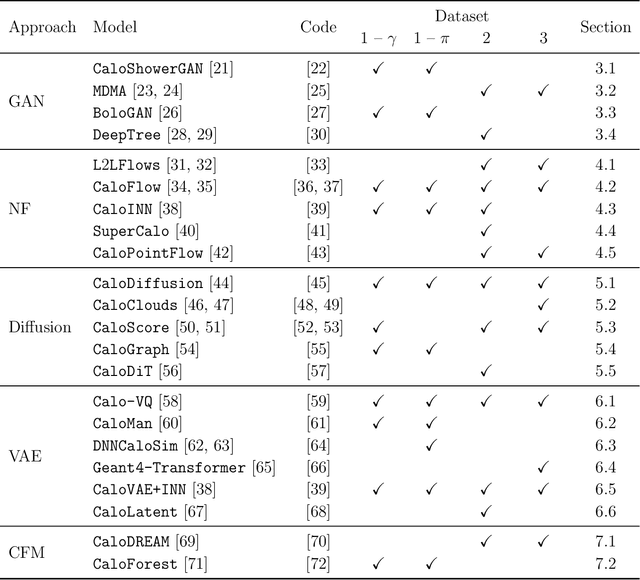
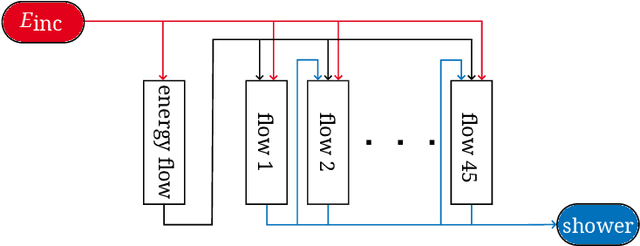
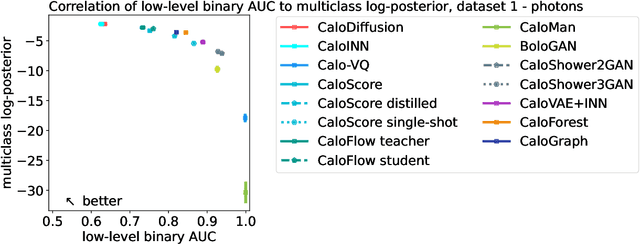
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.