 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
Jun 05, 2026We present SigmaScale, a method for learning auxiliary scaling matrices $S$ to aid truncated Singular Value Decomposition (SVD) based Large Language Model (LLM) compression. Instead of deriving scaling matrices analytically, SigmaScale optimizes two sets of vectors that define diagonal row and column scaling transformations under an activation-aware compression loss. We show that learned scaling lowers the effective intrinsic rank of weight matrices, as reflected by reductions in effective-rank entropy, and that this reduction is strongly correlated with compression loss. Experiments on Llama 3.1 8B Instruct and Qwen3-8B show that SigmaScale is competitive with closely related state-of-the-art SVD-based compression methods across perplexity and zero-shot benchmarks. By using learned activation-aware transformations, SigmaScale explores a more flexible route to low-rank LLM compression by adapting to the structure of individual model weights. The advantage observed in specific tasks makes our approach a valid option for applications requiring a reduced LLM-inference computing cost.
Taming the Exponential: A Fast Softmax Surrogate for Integer-Native Edge Inference
Apr 02, 2026Softmax can become a computational bottleneck in the Transformer model's Multi-Head Attention (MHA) block, particularly in small models under low-precision inference, where exponentiation and normalization incur significant overhead. As such, we suggest using Head-Calibrated Clipped-Linear Softmax (HCCS), a bounded, monotone surrogate to the exponential softmax function, which uses a clipped linear mapping of the max centered attention logits. This approximation produces a stable probability distribution, maintains the ordering of the original logits and has non-negative values. HCCS differs from previous softmax surrogates as it includes a set of lightweight calibration parameters that are optimized offline based on a representative dataset and calibrated for each individual attention head to preserve the statistical properties of the individual heads. We describe a hardware-motivated implementation of HCCS for high-throughput scenarios targeting the AMD Versal AI Engines. The current reference implementations from AMD for this platform rely upon either bfloat16 arithmetic or LUTs to perform the exponential operation, which might limit the throughput of the platform and fail to utilize the high-throughput integer vector processing units of the AI Engine. In contrast, HCCS provides a natural mapping to the AI Engines' int8 multiply accumulate (MAC) units. To the best of our knowledge, this is the first int8 optimized softmax surrogate for AMD AI engines that significantly exceeds the speed performance of other reference implementations while maintaining competitive task accuracy on small or heavily quantized MHA workloads after quantization-aware retraining.
PQuantML: A Tool for End-to-End Hardware-aware Model Compression
Mar 27, 2026PQuantML is a new open-source, hardware-aware neural network model compression library tailored to end-to-end workflows. Motivated by the need to deploy performant models to environments with strict latency constraints, PQuantML simplifies training of compressed models by providing a unified interface to apply pruning and quantization, either jointly or individually. The library implements multiple pruning methods with different granularities, as well as fixed-point quantization with support for High-Granularity Quantization. We evaluate PQuantML on representative tasks such as the jet substructure classification, so-called jet tagging, an on-edge problem related to real-time LHC data processing. Using various pruning methods with fixed-point quantization, PQuantML achieves substantial parameter and bit-width reductions while maintaining accuracy. The resulting compression is further compared against existing tools, such as QKeras and HGQ.
CHLU: The Causal Hamiltonian Learning Unit as a Symplectic Primitive for Deep Learning
Mar 02, 2026Current deep learning primitives dealing with temporal dynamics suffer from a fundamental dichotomy: they are either discrete and unstable (LSTMs) \citep{pascanu_difficulty_2013}, leading to exploding or vanishing gradients; or they are continuous and dissipative (Neural ODEs) \citep{dupont_augmented_2019}, which destroy information over time to ensure stability. We propose the \textbf{Causal Hamiltonian Learning Unit} (pronounced: \textit{clue}), a novel Physics-grounded computational learning primitive. By enforcing a Relativistic Hamiltonian structure and utilizing symplectic integration, a CHLU strictly conserves phase-space volume, as an attempt to solve the memory-stability trade-off. We show that the CHLU is designed for infinite-horizon stability, as well as controllable noise filtering. We then demonstrate a CHLU's generative ability using the MNIST dataset as a proof-of-principle.
Towards Tensor Network Models for Low-Latency Jet Tagging on FPGAs
Jan 15, 2026We present a systematic study of Tensor Network (TN) models $\unicode{x2013}$ Matrix Product States (MPS) and Tree Tensor Networks (TTN) $\unicode{x2013}$ for real-time jet tagging in high-energy physics, with a focus on low-latency deployment on Field Programmable Gate Arrays (FPGAs). Motivated by the strict requirements of the HL-LHC Level-1 trigger system, we explore TNs as compact and interpretable alternatives to deep neural networks. Using low-level jet constituent features, our models achieve competitive performance compared to state-of-the-art deep learning classifiers. We investigate post-training quantization to enable hardware-efficient implementations without degrading classification performance or latency. The best-performing models are synthesized to estimate FPGA resource usage, latency, and memory occupancy, demonstrating sub-microsecond latency and supporting the feasibility of online deployment in real-time trigger systems. Overall, this study highlights the potential of TN-based models for fast and resource-efficient inference in low-latency environments.
AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines
Dec 17, 2025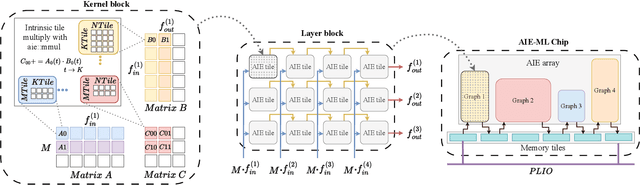
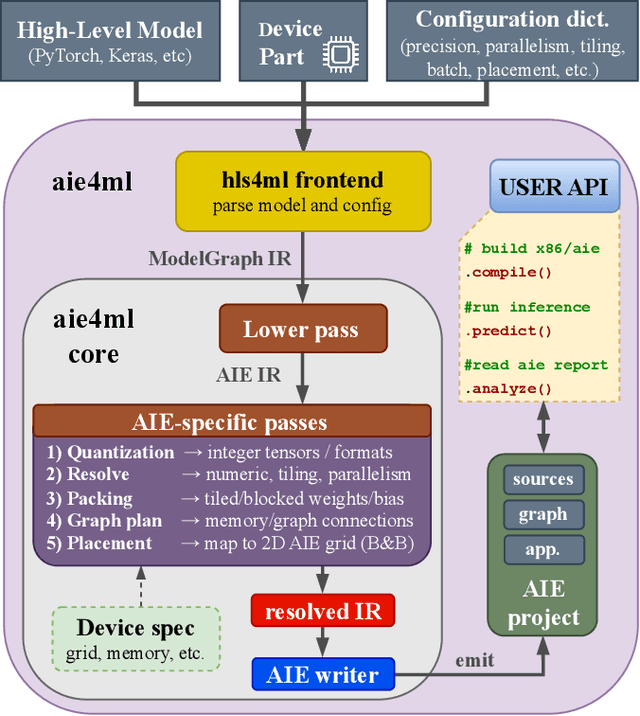
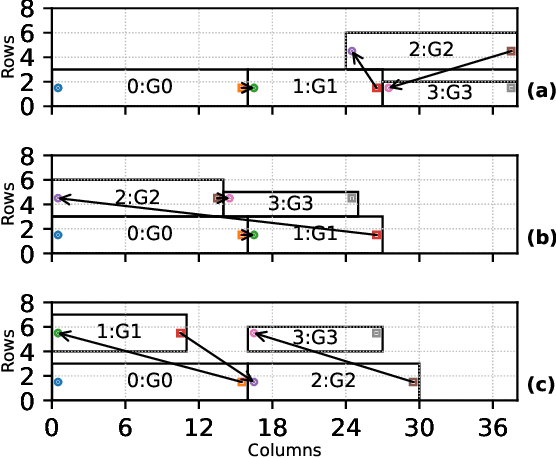
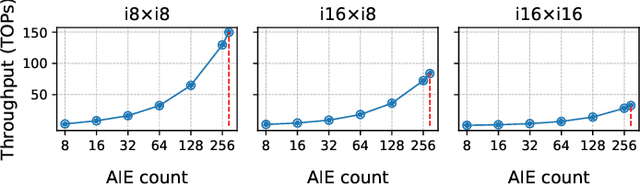
Efficient AI inference on AMD's Versal AI Engine (AIE) is challenging due to tightly coupled VLIW execution, explicit datapaths, and local memory management. Prior work focused on first-generation AIE kernel optimizations, without tackling full neural network execution across the 2D array. In this work, we present AIE4ML, the first comprehensive framework for converting AI models automatically into optimized firmware targeting the AIE-ML generation devices, also with forward compatibility for the newer AIE-MLv2 architecture. At the single-kernel level, we attain performance close to the architectural peak. At the graph and system levels, we provide a structured parallelization method that can scale across the 2D AIE-ML fabric and exploit its dedicated memory tiles to stay entirely on-chip throughout the model execution. As a demonstration, we designed a generalized and highly efficient linear-layer implementation with intrinsic support for fused bias addition and ReLU activation. Also, as our framework necessitates the generation of multi-layer implementations, our approach systematically derives deterministic, compact, and topology-optimized placements tailored to the physical 2D grid of the device through a novel graph placement and search algorithm. Finally, the framework seamlessly accepts quantized models imported from high-level tools such as hls4ml or PyTorch while preserving bit-exactness. In layer scaling benchmarks, we achieve up to 98.6% efficiency relative to the single-kernel baseline, utilizing 296 of 304 AIE tiles (97.4%) of the device with entirely on-chip data movement. With evaluations across real-world model topologies, we demonstrate that AIE4ML delivers GPU-class throughput under microsecond latency constraints, making it a practical companion for ultra-low-latency environments such as trigger systems in particle physics experiments.
Knowledge is Overrated: A zero-knowledge machine learning and cryptographic hashing-based framework for verifiable, low latency inference at the LHC
Nov 16, 2025Low latency event-selection (trigger) algorithms are essential components of Large Hadron Collider (LHC) operation. Modern machine learning (ML) models have shown great offline performance as classifiers and could improve trigger performance, thereby improving downstream physics analyses. However, inference on such large models does not satisfy the $40\text{MHz}$ online latency constraint at the LHC. In this work, we propose \texttt{PHAZE}, a novel framework built on cryptographic techniques like hashing and zero-knowledge machine learning (zkML) to achieve low latency inference, via a certifiable, early-exit mechanism from an arbitrarily large baseline model. We lay the foundations for such a framework to achieve nanosecond-order latency and discuss its inherent advantages, such as built-in anomaly detection, within the scope of LHC triggers, as well as its potential to enable a dynamic low-level trigger in the future.
Fast Jet Tagging with MLP-Mixers on FPGAs
Mar 05, 2025
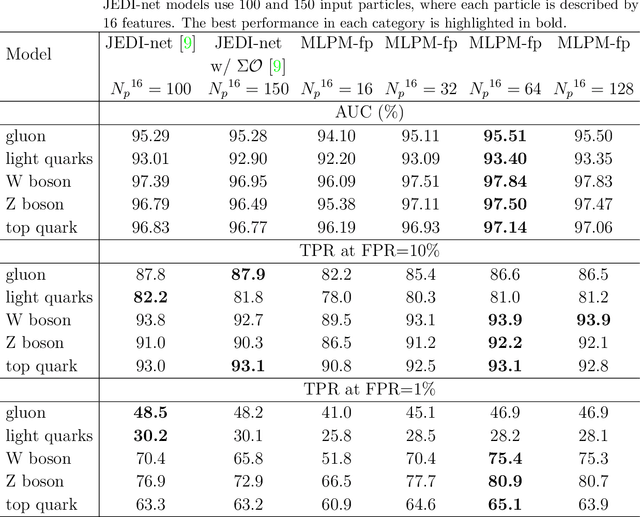

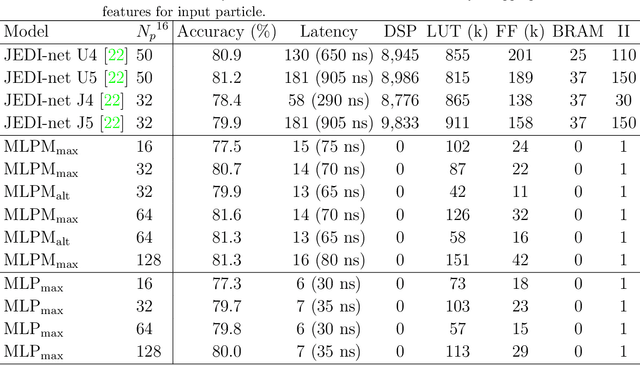
We explore the innovative use of MLP-Mixer models for real-time jet tagging and establish their feasibility on resource-constrained hardware like FPGAs. MLP-Mixers excel in processing sequences of jet constituents, achieving state-of-the-art performance on datasets mimicking Large Hadron Collider conditions. By using advanced optimization techniques such as High-Granularity Quantization and Distributed Arithmetic, we achieve unprecedented efficiency. These models match or surpass the accuracy of previous architectures, reduce hardware resource usage by up to 97%, double the throughput, and half the latency. Additionally, non-permutation-invariant architectures enable smart feature prioritization and efficient FPGA deployment, setting a new benchmark for machine learning in real-time data processing at particle colliders.
tn4ml: Tensor Network Training and Customization for Machine Learning
Feb 18, 2025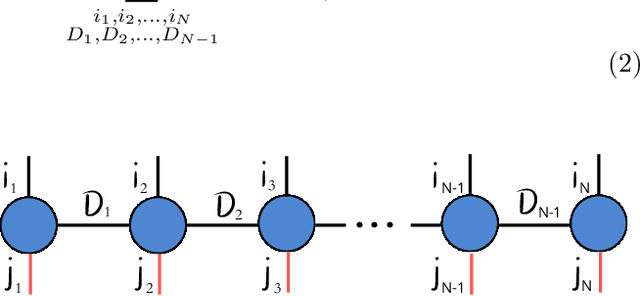
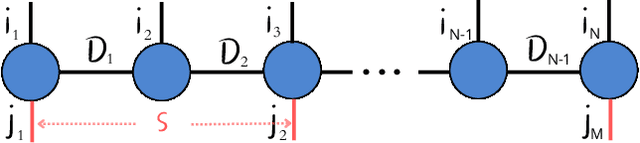
Tensor Networks have emerged as a prominent alternative to neural networks for addressing Machine Learning challenges in foundational sciences, paving the way for their applications to real-life problems. This paper introduces tn4ml, a novel library designed to seamlessly integrate Tensor Networks into optimization pipelines for Machine Learning tasks. Inspired by existing Machine Learning frameworks, the library offers a user-friendly structure with modules for data embedding, objective function definition, and model training using diverse optimization strategies. We demonstrate its versatility through two examples: supervised learning on tabular data and unsupervised learning on an image dataset. Additionally, we analyze how customizing the parts of the Machine Learning pipeline for Tensor Networks influences performance metrics.
Sets are all you need: Ultrafast jet classification on FPGAs for HL-LHC
Feb 02, 2024
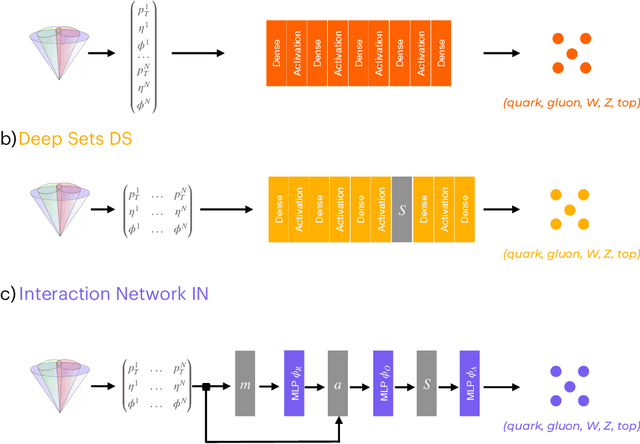
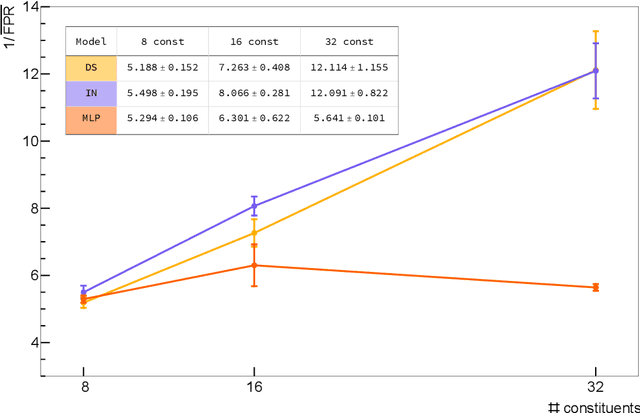

We study various machine learning based algorithms for performing accurate jet flavor classification on field-programmable gate arrays and demonstrate how latency and resource consumption scale with the input size and choice of algorithm. These architectures provide an initial design for models that could be used for tagging at the CERN LHC during its high-luminosity phase. The high-luminosity upgrade will lead to a five-fold increase in its instantaneous luminosity for proton-proton collisions and, in turn, higher data volume and complexity, such as the availability of jet constituents. Through quantization-aware training and efficient hardware implementations, we show that O(100) ns inference of complex architectures such as deep sets and interaction networks is feasible at a low computational resource cost.