 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024
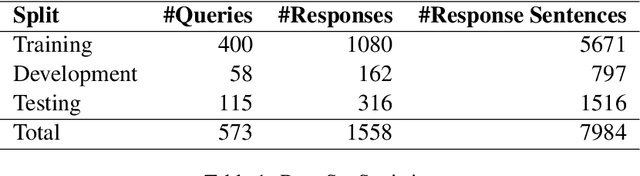
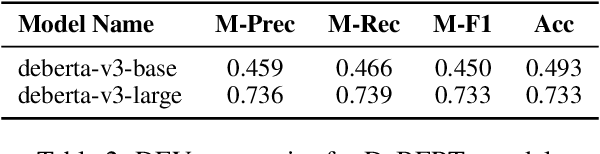
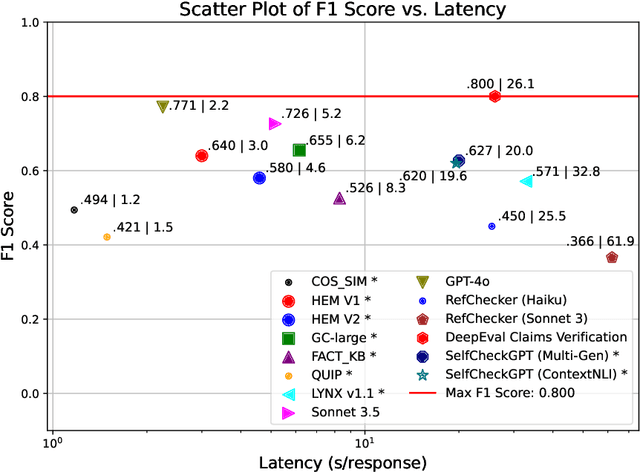
In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
Knowledge Distillation for Anomaly Detection
Oct 09, 2023


Unsupervised deep learning techniques are widely used to identify anomalous behaviour. The performance of such methods is a product of the amount of training data and the model size. However, the size is often a limiting factor for the deployment on resource-constrained devices. We present a novel procedure based on knowledge distillation for compressing an unsupervised anomaly detection model into a supervised deployable one and we suggest a set of techniques to improve the detection sensitivity. Compressed models perform comparably to their larger counterparts while significantly reducing the size and memory footprint.
Symbolic Regression on FPGAs for Fast Machine Learning Inference
May 06, 2023



The high-energy physics community is investigating the feasibility of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to improve physics sensitivity while meeting data processing latency limitations. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on a physics benchmark: multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider, and show that we approximate a 3-layer neural network with an inference model that has as low as 5 ns execution time (a reduction by a factor of 13) and over 90% approximation accuracy.
Towards Optimal Compression: Joint Pruning and Quantization
Feb 15, 2023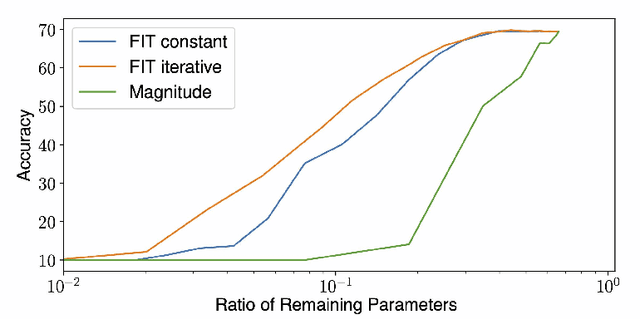
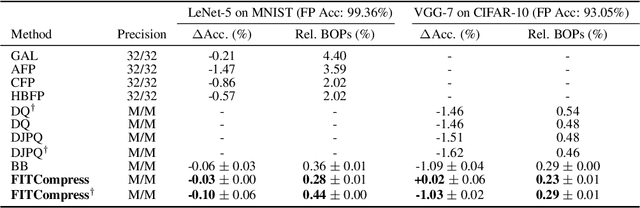
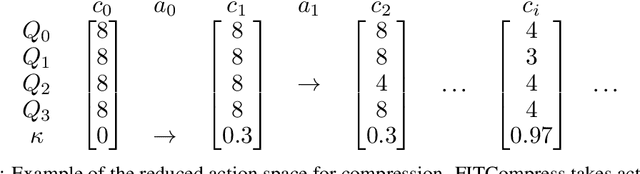
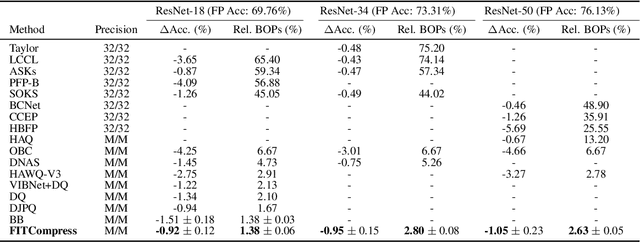
Compression of deep neural networks has become a necessary stage for optimizing model inference on resource-constrained hardware. This paper presents FITCompress, a method for unifying layer-wise mixed precision quantization and pruning under a single heuristic, as an alternative to neural architecture search and Bayesian-based techniques. FITCompress combines the Fisher Information Metric, and path planning through compression space, to pick optimal configurations given size and operation constraints with single-shot fine-tuning. Experiments on ImageNet validate the method and show that our approach yields a better trade-off between accuracy and efficiency when compared to the baselines. Besides computer vision benchmarks, we experiment with the BERT model on a language understanding task, paving the way towards its optimal compression.
FIT: A Metric for Model Sensitivity
Oct 16, 2022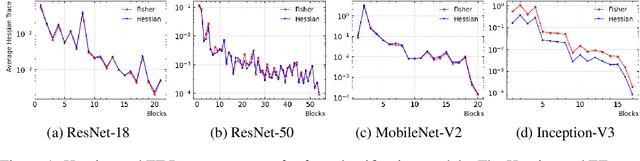


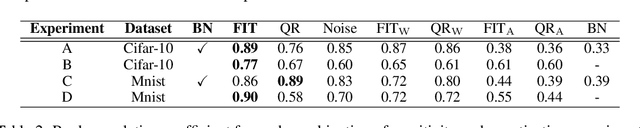
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.
Lightweight Jet Reconstruction and Identification as an Object Detection Task
Feb 09, 2022
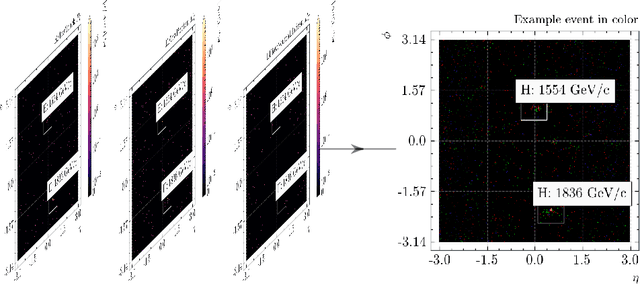
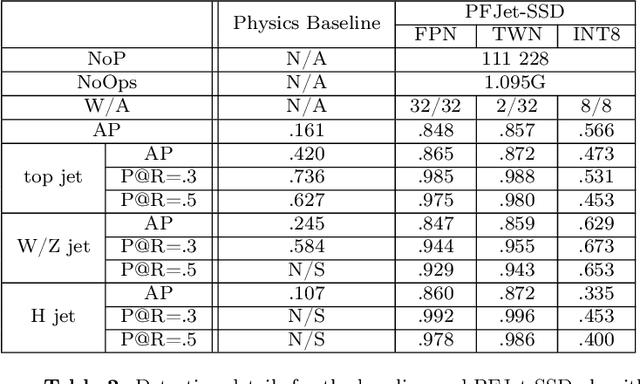
We apply object detection techniques based on deep convolutional blocks to end-to-end jet identification and reconstruction tasks encountered at the CERN Large Hadron Collider (LHC). Collision events produced at the LHC and represented as an image composed of calorimeter and tracker cells are given as an input to a Single Shot Detection network. The algorithm, named PFJet-SSD performs simultaneous localization, classification and regression tasks to cluster jets and reconstruct their features. This all-in-one single feed-forward pass gives advantages in terms of execution time and an improved accuracy w.r.t. traditional rule-based methods. A further gain is obtained from network slimming, homogeneous quantization, and optimized runtime for meeting memory and latency constraints of a typical real-time processing environment. We experiment with 8-bit and ternary quantization, benchmarking their accuracy and inference latency against a single-precision floating-point. We show that the ternary network closely matches the performance of its full-precision equivalent and outperforms the state-of-the-art rule-based algorithm. Finally, we report the inference latency on different hardware platforms and discuss future applications.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021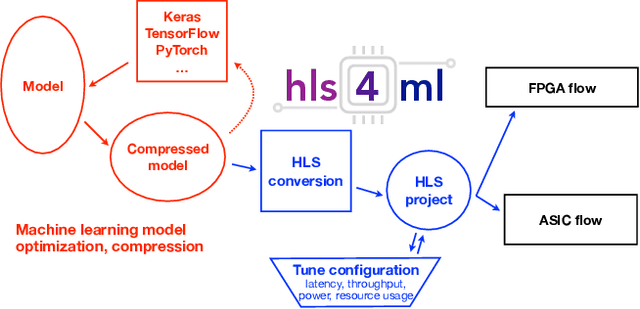
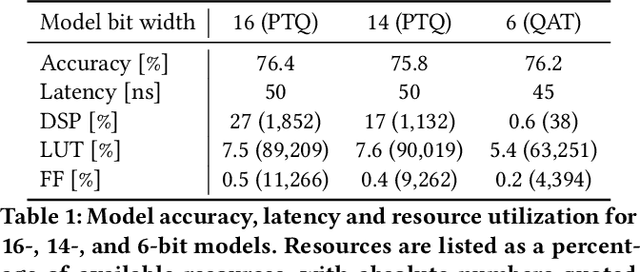
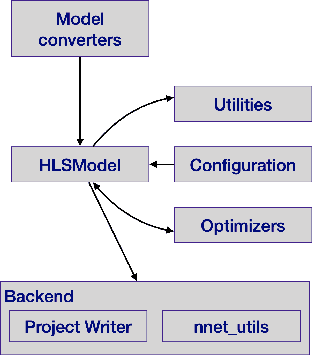
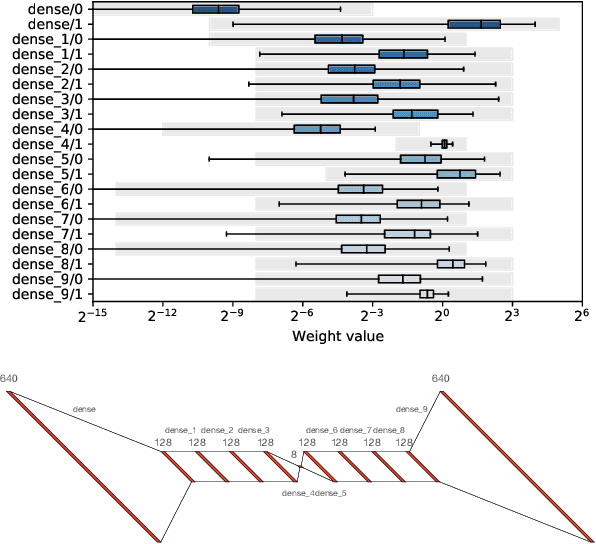
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
Anomaly Detection With Conditional Variational Autoencoders
Oct 12, 2020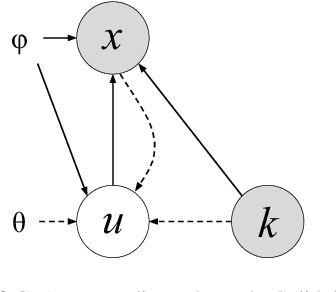
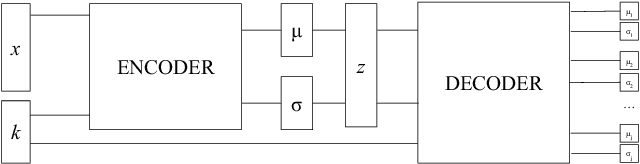

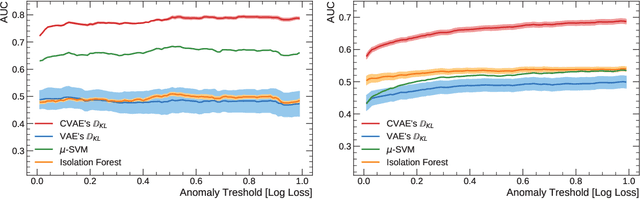
Exploiting the rapid advances in probabilistic inference, in particular variational Bayes and variational autoencoders (VAEs), for anomaly detection (AD) tasks remains an open research question. Previous works argued that training VAE models only with inliers is insufficient and the framework should be significantly modified in order to discriminate the anomalous instances. In this work, we exploit the deep conditional variational autoencoder (CVAE) and we define an original loss function together with a metric that targets hierarchically structured data AD. Our motivating application is a real world problem: monitoring the trigger system which is a basic component of many particle physics experiments at the CERN Large Hadron Collider (LHC). In the experiments we show the superior performance of this method for classical machine learning (ML) benchmarks and for our application.
Detector monitoring with artificial neural networks at the CMS experiment at the CERN Large Hadron Collider
Jul 27, 2018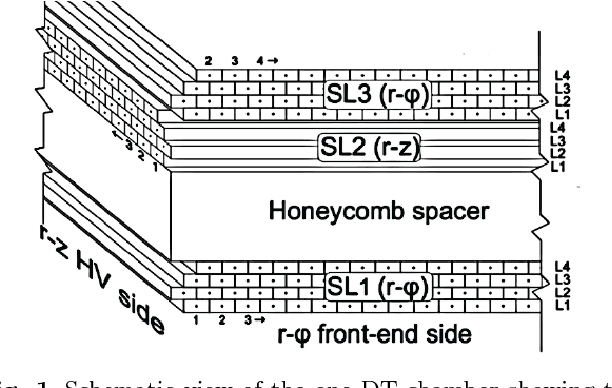
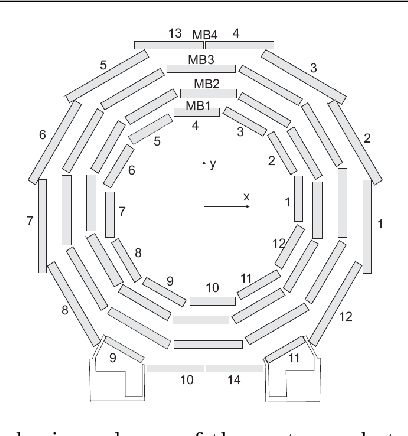
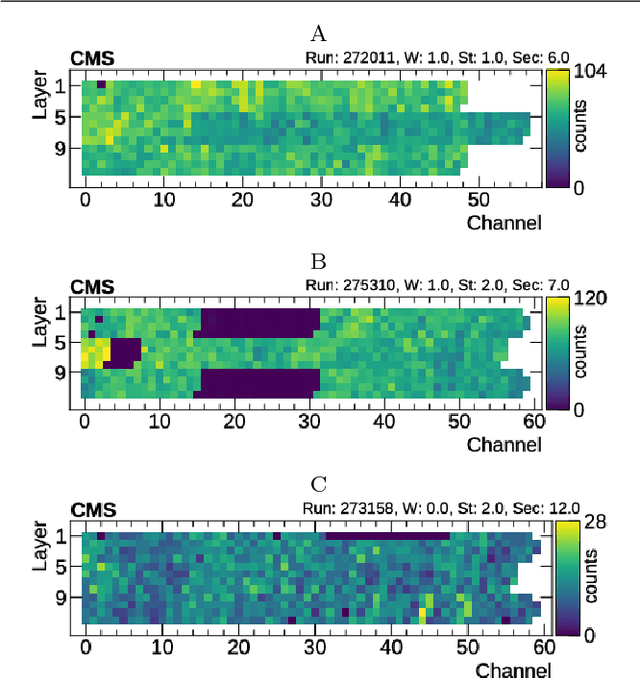
Reliable data quality monitoring is a key asset in delivering collision data suitable for physics analysis in any modern large-scale High Energy Physics experiment. This paper focuses on the use of artificial neural networks for supervised and semi-supervised problems related to the identification of anomalies in the data collected by the CMS muon detectors. We use deep neural networks to analyze LHC collision data, represented as images organized geographically. We train a classifier capable of detecting the known anomalous behaviors with unprecedented efficiency and explore the usage of convolutional autoencoders to extend anomaly detection capabilities to unforeseen failure modes. A generalization of this strategy could pave the way to the automation of the data quality assessment process for present and future high-energy physics experiments.