 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

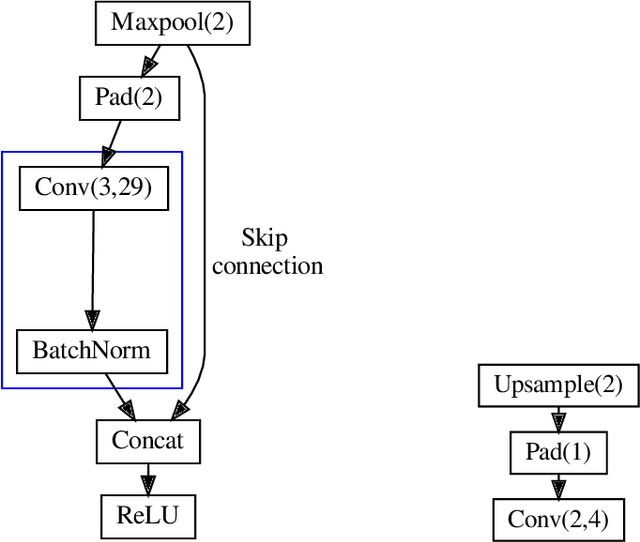
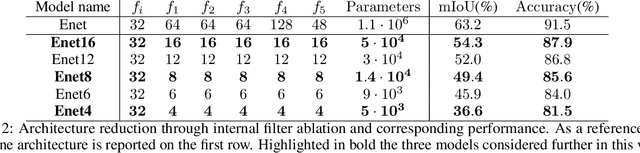
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Lightweight Jet Reconstruction and Identification as an Object Detection Task
Feb 09, 2022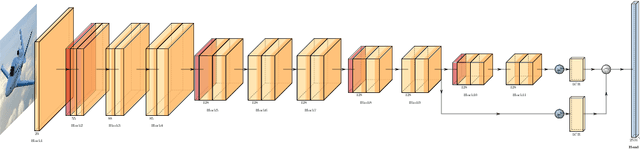
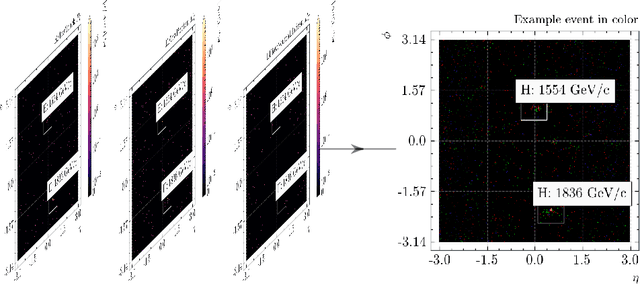
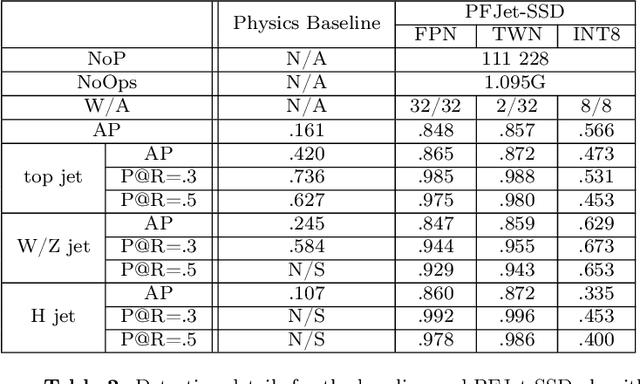
We apply object detection techniques based on deep convolutional blocks to end-to-end jet identification and reconstruction tasks encountered at the CERN Large Hadron Collider (LHC). Collision events produced at the LHC and represented as an image composed of calorimeter and tracker cells are given as an input to a Single Shot Detection network. The algorithm, named PFJet-SSD performs simultaneous localization, classification and regression tasks to cluster jets and reconstruct their features. This all-in-one single feed-forward pass gives advantages in terms of execution time and an improved accuracy w.r.t. traditional rule-based methods. A further gain is obtained from network slimming, homogeneous quantization, and optimized runtime for meeting memory and latency constraints of a typical real-time processing environment. We experiment with 8-bit and ternary quantization, benchmarking their accuracy and inference latency against a single-precision floating-point. We show that the ternary network closely matches the performance of its full-precision equivalent and outperforms the state-of-the-art rule-based algorithm. Finally, we report the inference latency on different hardware platforms and discuss future applications.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
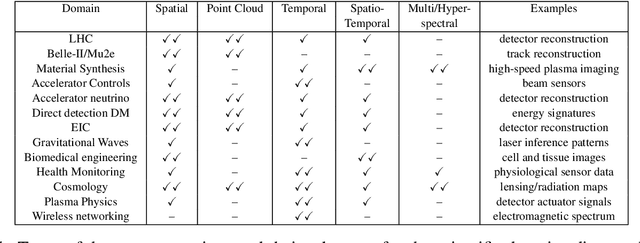
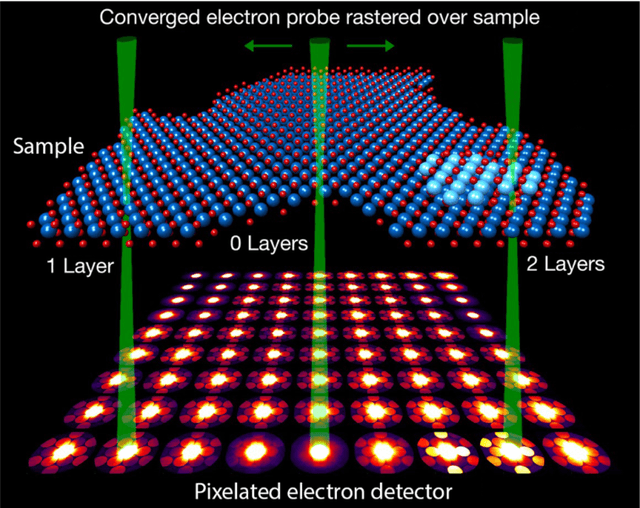
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Accelerating Recurrent Neural Networks for Gravitational Wave Experiments
Jun 26, 2021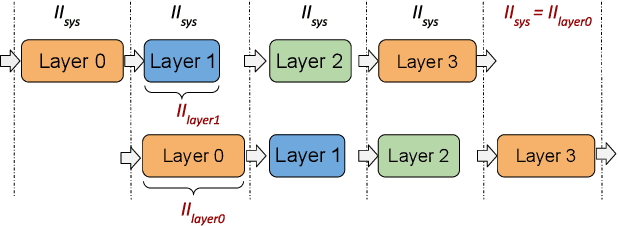
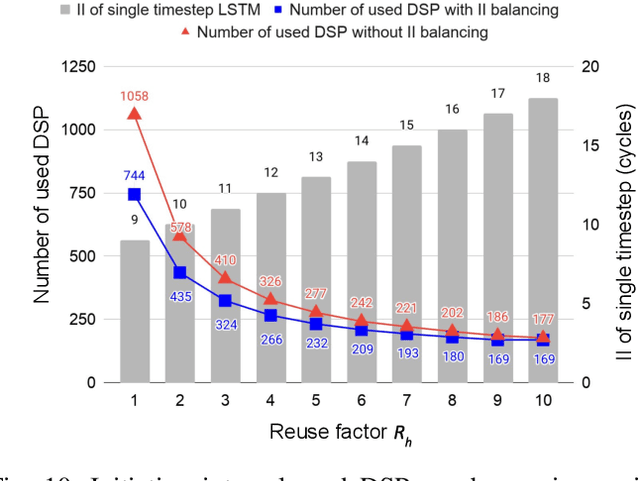
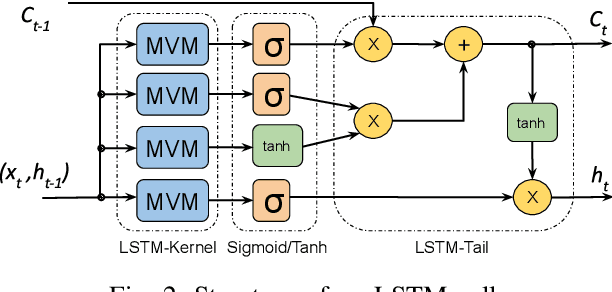
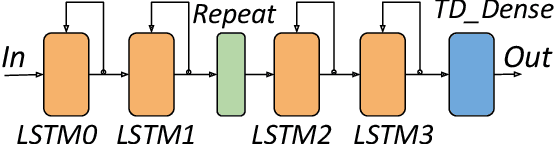
This paper presents novel reconfigurable architectures for reducing the latency of recurrent neural networks (RNNs) that are used for detecting gravitational waves. Gravitational interferometers such as the LIGO detectors capture cosmic events such as black hole mergers which happen at unknown times and of varying durations, producing time-series data. We have developed a new architecture capable of accelerating RNN inference for analyzing time-series data from LIGO detectors. This architecture is based on optimizing the initiation intervals (II) in a multi-layer LSTM (Long Short-Term Memory) network, by identifying appropriate reuse factors for each layer. A customizable template for this architecture has been designed, which enables the generation of low-latency FPGA designs with efficient resource utilization using high-level synthesis tools. The proposed approach has been evaluated based on two LSTM models, targeting a ZYNQ 7045 FPGA and a U250 FPGA. Experimental results show that with balanced II, the number of DSPs can be reduced up to 42% while achieving the same IIs. When compared to other FPGA-based LSTM designs, our design can achieve about 4.92 to 12.4 times lower latency.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021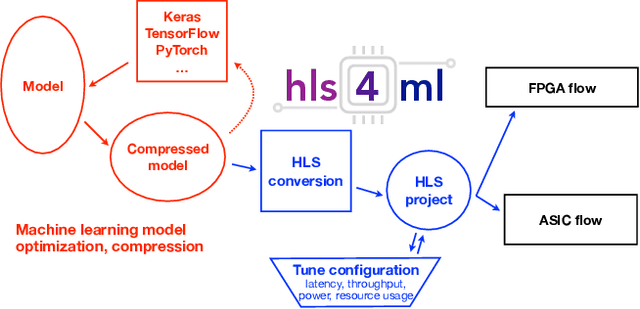
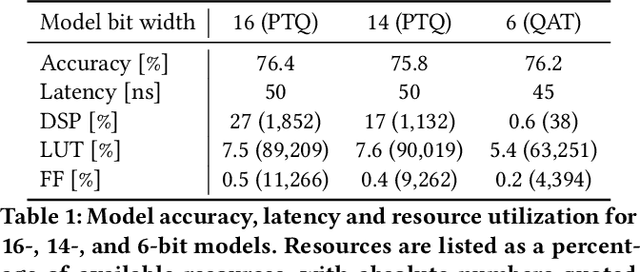
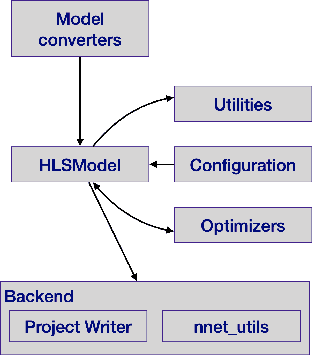
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
Fast convolutional neural networks on FPGAs with hls4ml
Jan 13, 2021
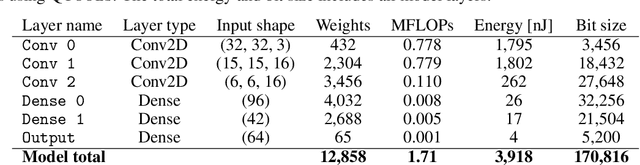

We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with large convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate how to achieve inference latency of $5\,\mu$s using convolutional architectures, while preserving state-of-the-art model performance. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be reduced by over 90% while maintaining the original model accuracy.
Accelerated Charged Particle Tracking with Graph Neural Networks on FPGAs
Nov 30, 2020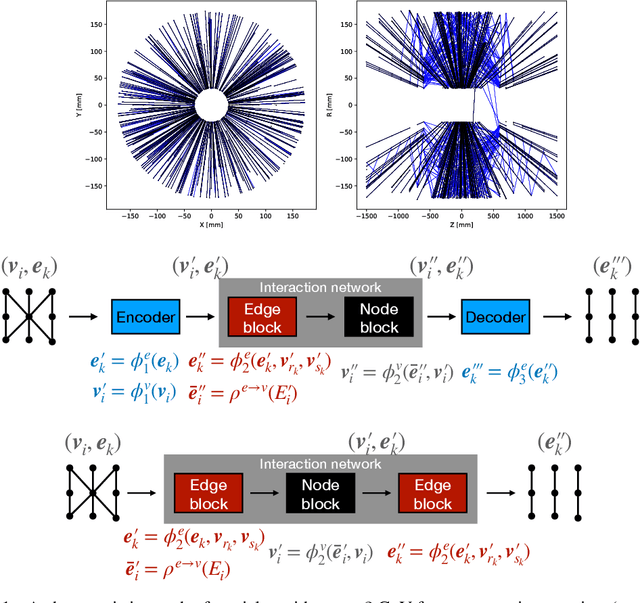
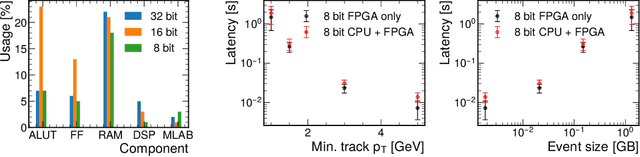


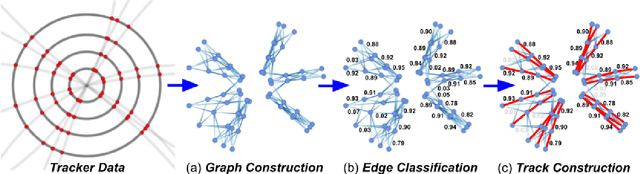
We develop and study FPGA implementations of algorithms for charged particle tracking based on graph neural networks. The two complementary FPGA designs are based on OpenCL, a framework for writing programs that execute across heterogeneous platforms, and hls4ml, a high-level-synthesis-based compiler for neural network to firmware conversion. We evaluate and compare the resource usage, latency, and tracking performance of our implementations based on a benchmark dataset. We find a considerable speedup over CPU-based execution is possible, potentially enabling such algorithms to be used effectively in future computing workflows and the FPGA-based Level-1 trigger at the CERN Large Hadron Collider.
Ultra Low-latency, Low-area Inference Accelerators using Heterogeneous Deep Quantization with QKeras and hls4ml
Jun 15, 2020


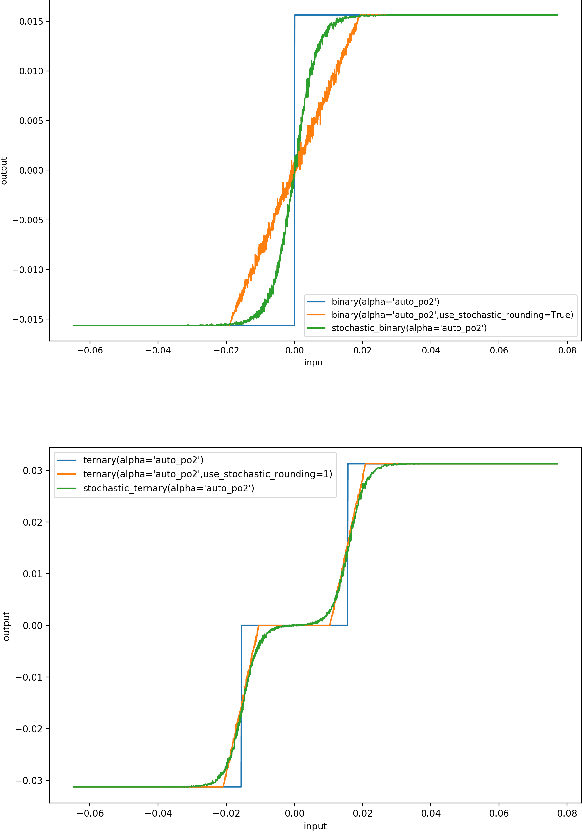
In this paper, we introduce the QKeras library, an extension of the Keras library allowing for the creation of heterogeneously quantized versions of deep neural network models, through drop-in replacement of Keras layers. These models are trained quantization-aware, where the user can trade off model area or energy consumption by accuracy. We demonstrate how the reduction of numerical precision, through quantization-aware training, significantly reduces resource consumption while retaining high accuracy when implemented on FPGA hardware. Together with the hls4ml library, this allows for a fully automated deployment of quantized Keras models on chip, crucial for ultra low-latency inference. As a benchmark problem, we consider a classification task for the triggering of events in proton-proton collisions at the CERN Large Hadron Collider, where a latency of ${\mathcal O}(1)~\mu$s is required.