 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Streaming Stochastic Interpolant Policy
May 11, 2026Inference-time guidance is essential for steering generative robot policies toward dynamic objectives without retraining, yet existing methods are largely confined to chunk-based architectures that exhibit high latency and lack the reactivity needed for test-time preference alignment or obstacle avoidance. In this work, we formally derive the optimal guidance term for Stochastic Interpolants (SI) by analyzing the value function's time evolution via the Backward Kolmogorov Equation, establishing a modified drift that theoretically guarantees sampling from a target distribution. We apply this framework to real-time control through the Streaming Stochastic Interpolant Policy (SSIP), which generalizes the deterministic Streaming Flow Policy (SFP). Unifying this guidance law with the streaming architecture enables fast and reactive control. To support diverse deployment needs, we propose two complementary mechanisms: training-free Stochastic Trajectory Ensemble Guidance (STEG) that computes gradients on-the-fly for zero-shot adaptation, and training-based Conditional Critic Guidance (CCG) for amortized inference. Empirical evaluations demonstrate that our guided streaming approach significantly outperforms conventional chunk-based policies in reactivity and provides superior, physically valid guidance for dynamic, unstructured environments.
OpenRoboCare: A Multimodal Multi-Task Expert Demonstration Dataset for Robot Caregiving
Nov 17, 2025We present OpenRoboCare, a multimodal dataset for robot caregiving, capturing expert occupational therapist demonstrations of Activities of Daily Living (ADLs). Caregiving tasks involve complex physical human-robot interactions, requiring precise perception under occlusions, safe physical contact, and long-horizon planning. While recent advances in robot learning from demonstrations have shown promise, there is a lack of a large-scale, diverse, and expert-driven dataset that captures real-world caregiving routines. To address this gap, we collect data from 21 occupational therapists performing 15 ADL tasks on two manikins. The dataset spans five modalities: RGB-D video, pose tracking, eye-gaze tracking, task and action annotations, and tactile sensing, providing rich multimodal insights into caregiver movement, attention, force application, and task execution strategies. We further analyze expert caregiving principles and strategies, offering insights to improve robot efficiency and task feasibility. Additionally, our evaluations demonstrate that OpenRoboCare presents challenges for state-of-the-art robot perception and human activity recognition methods, both critical for developing safe and adaptive assistive robots, highlighting the value of our contribution. See our website for additional visualizations: https://emprise.cs.cornell.edu/robo-care/.
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Jun 14, 2024



Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to out-of-distribution (OOD) action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
Octopi: Object Property Reasoning with Large Tactile-Language Models
May 05, 2024



Physical reasoning is important for effective robot manipulation. Recent work has investigated both vision and language modalities for physical reasoning; vision can reveal information about objects in the environment and language serves as an abstraction and communication medium for additional context. Although these works have demonstrated success on a variety of physical reasoning tasks, they are limited to physical properties that can be inferred from visual or language inputs. In this work, we investigate combining tactile perception with language, which enables embodied systems to obtain physical properties through interaction and apply common-sense reasoning. We contribute a new dataset PhysiCleAR, which comprises both physical/property reasoning tasks and annotated tactile videos obtained using a GelSight tactile sensor. We then introduce Octopi, a system that leverages both tactile representation learning and large vision-language models to predict and reason about tactile inputs with minimal language fine-tuning. Our evaluations on PhysiCleAR show that Octopi is able to effectively use intermediate physical property predictions to improve physical reasoning in both trained tasks and for zero-shot reasoning. PhysiCleAR and Octopi are available on https://github.com/clear-nus/octopi.
Behavioral Refinement via Interpolant-based Policy Diffusion
Feb 25, 2024



Imitation learning empowers artificial agents to mimic behavior by learning from demonstrations. Recently, diffusion models, which have the ability to model high-dimensional and multimodal distributions, have shown impressive performance on imitation learning tasks. These models learn to shape a policy by diffusing actions (or states) from standard Gaussian noise. However, the target policy to be learned is often significantly different from Gaussian and this mismatch can result in poor performance when using a small number of diffusion steps (to improve inference speed) and under limited data. The key idea in this work is that initiating from a more informative source than Gaussian enables diffusion methods to overcome the above limitations. We contribute both theoretical results, a new method, and empirical findings that show the benefits of using an informative source policy. Our method, which we call BRIDGER, leverages the stochastic interpolants framework to bridge arbitrary policies, thus enabling a flexible approach towards imitation learning. It generalizes prior work in that standard Gaussians can still be applied, but other source policies can be used if available. In experiments on challenging benchmarks, BRIDGER outperforms state-of-the-art diffusion policies and we provide further analysis on design considerations when applying BRIDGER.
GRaCE: Optimizing Grasps to Satisfy Ranked Criteria in Complex Scenarios
Oct 02, 2023This paper addresses the multi-faceted problem of robot grasping, where multiple criteria may conflict and differ in importance. We introduce Grasp Ranking and Criteria Evaluation (GRaCE), a novel approach that employs hierarchical rule-based logic and a rank-preserving utility function to optimize grasps based on various criteria such as stability, kinematic constraints, and goal-oriented functionalities. Additionally, we propose GRaCE-OPT, a hybrid optimization strategy that combines gradient-based and gradient-free methods to effectively navigate the complex, non-convex utility function. Experimental results in both simulated and real-world scenarios show that GRaCE requires fewer samples to achieve comparable or superior performance relative to existing methods. The modular architecture of GRaCE allows for easy customization and adaptation to specific application needs.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

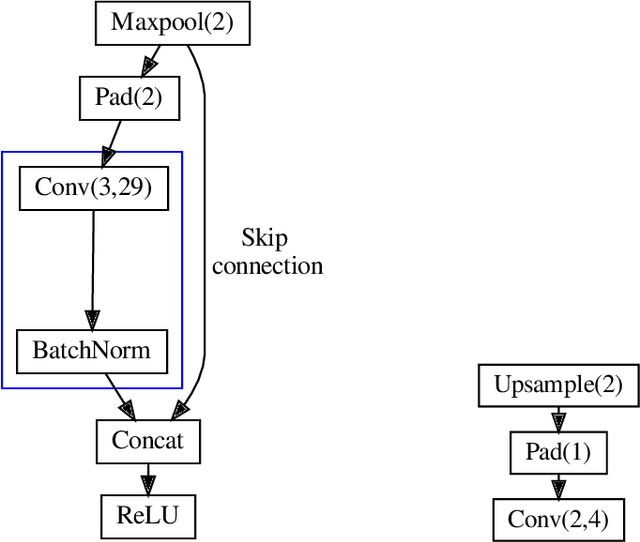
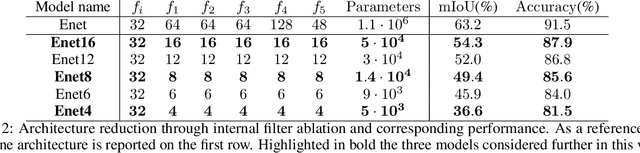
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.