 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse
Mar 04, 2026Recent progress in vision-language-action (VLA) models has demonstrated strong potential for dual-arm manipulation, enabling complex behaviors and generalization to unseen environments. However, mainstream bimanual VLA formulations largely overlook the critical challenge of combinatorial diversity. Different pairings of single-arm behaviors can induce qualitatively distinct task behaviors, yet existing models do not explicitly account for this structure. We argue that effective bimanual VLAs should support skill reuse - the ability to recombine previously learned single-arm skills across novel left-right pairings - thereby avoiding the need to separately learn every possible combination. Current VLA designs entangle skills across arms, preventing such recomposition and limiting scalability. To address this limitation, we propose SkillVLA, a framework explicitly designed to enable skill reuse in dual-arm manipulation. Extensive experiments demonstrate that SkillVLA substantially improves skill composition, increasing overall success rate from 0% to 51%, and achieves strong performance on cooperative and long-horizon tasks.
Not All Layers Need Tuning: Selective Layer Restoration Recovers Diversity
Feb 06, 2026Post-training improves instruction-following and helpfulness of large language models (LLMs) but often reduces generation diversity, which leads to repetitive outputs in open-ended settings, a phenomenon known as mode collapse. Motivated by evidence that LLM layers play distinct functional roles, we hypothesize that mode collapse can be localized to specific layers and that restoring a carefully chosen range of layers to their pre-trained weights can recover diversity while maintaining high output quality. To validate this hypothesis and decide which layers to restore, we design a proxy task -- Constrained Random Character(CRC) -- with an explicit validity set and a natural diversity objective. Results on CRC reveal a clear diversity-validity trade-off across restoration ranges and identify configurations that increase diversity with minimal quality loss. Based on these findings, we propose Selective Layer Restoration (SLR), a training-free method that restores selected layers in a post-trained model to their pre-trained weights, yielding a hybrid model with the same architecture and parameter count, incurring no additional inference cost. Across three different tasks (creative writing, open-ended question answering, and multi-step reasoning) and three different model families (Llama, Qwen, and Gemma), we find SLR can consistently and substantially improve output diversity while maintaining high output quality.
Action Hallucination in Generative Visual-Language-Action Models
Feb 06, 2026Robot Foundation Models such as Vision-Language-Action models are rapidly reshaping how robot policies are trained and deployed, replacing hand-designed planners with end-to-end generative action models. While these systems demonstrate impressive generalization, it remains unclear whether they fundamentally resolve the long-standing challenges of robotics. We address this question by analyzing action hallucinations that violate physical constraints and their extension to plan-level failures. Focusing on latent-variable generative policies, we show that hallucinations often arise from structural mismatches between feasible robot behavior and common model architectures. We study three such barriers -- topological, precision, and horizon -- and show how they impose unavoidable tradeoffs. Our analysis provides mechanistic explanations for reported empirical failures of generative robot policies and suggests principled directions for improving reliability and trustworthiness, without abandoning their expressive power.
Abstracting Robot Manipulation Skills via Mixture-of-Experts Diffusion Policies
Jan 29, 2026Diffusion-based policies have recently shown strong results in robot manipulation, but their extension to multi-task scenarios is hindered by the high cost of scaling model size and demonstrations. We introduce Skill Mixture-of-Experts Policy (SMP), a diffusion-based mixture-of-experts policy that learns a compact orthogonal skill basis and uses sticky routing to compose actions from a small, task-relevant subset of experts at each step. A variational training objective supports this design, and adaptive expert activation at inference yields fast sampling without oversized backbones. We validate SMP in simulation and on a real dual-arm platform with multi-task learning and transfer learning tasks, where SMP achieves higher success rates and markedly lower inference cost than large diffusion baselines. These results indicate a practical path toward scalable, transferable multi-task manipulation: learn reusable skills once, activate only what is needed, and adapt quickly when tasks change.
OpenRoboCare: A Multimodal Multi-Task Expert Demonstration Dataset for Robot Caregiving
Nov 17, 2025We present OpenRoboCare, a multimodal dataset for robot caregiving, capturing expert occupational therapist demonstrations of Activities of Daily Living (ADLs). Caregiving tasks involve complex physical human-robot interactions, requiring precise perception under occlusions, safe physical contact, and long-horizon planning. While recent advances in robot learning from demonstrations have shown promise, there is a lack of a large-scale, diverse, and expert-driven dataset that captures real-world caregiving routines. To address this gap, we collect data from 21 occupational therapists performing 15 ADL tasks on two manikins. The dataset spans five modalities: RGB-D video, pose tracking, eye-gaze tracking, task and action annotations, and tactile sensing, providing rich multimodal insights into caregiver movement, attention, force application, and task execution strategies. We further analyze expert caregiving principles and strategies, offering insights to improve robot efficiency and task feasibility. Additionally, our evaluations demonstrate that OpenRoboCare presents challenges for state-of-the-art robot perception and human activity recognition methods, both critical for developing safe and adaptive assistive robots, highlighting the value of our contribution. See our website for additional visualizations: https://emprise.cs.cornell.edu/robo-care/.
VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback
Jul 23, 2025Tactile feedback is generally recognized to be crucial for effective interaction with the physical world. However, state-of-the-art Vision-Language-Action (VLA) models lack the ability to interpret and use tactile signals, limiting their effectiveness in contact-rich tasks. Incorporating tactile feedback into these systems is challenging due to the absence of large multi-modal datasets. We present VLA-Touch, an approach that enhances generalist robot policies with tactile sensing \emph{without fine-tuning} the base VLA. Our method introduces two key innovations: (1) a pipeline that leverages a pretrained tactile-language model that provides semantic tactile feedback for high-level task planning, and (2) a diffusion-based controller that refines VLA-generated actions with tactile signals for contact-rich manipulation. Through real-world experiments, we demonstrate that our dual-level integration of tactile feedback improves task planning efficiency while enhancing execution precision. Code is open-sourced at \href{https://github.com/jxbi1010/VLA-Touch}{this URL}.
FG 2025 TrustFAA: the First Workshop on Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)
Jun 05, 2025With the increasing prevalence and deployment of Emotion AI-powered facial affect analysis (FAA) tools, concerns about the trustworthiness of these systems have become more prominent. This first workshop on "Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)" aims to bring together researchers who are investigating different challenges in relation to trustworthiness-such as interpretability, uncertainty, biases, and privacy-across various facial affect analysis tasks, including macro/ micro-expression recognition, facial action unit detection, other corresponding applications such as pain and depression detection, as well as human-robot interaction and collaboration. In alignment with FG2025's emphasis on ethics, as demonstrated by the inclusion of an Ethical Impact Statement requirement for this year's submissions, this workshop supports FG2025's efforts by encouraging research, discussion and dialogue on trustworthy FAA.
Know When to Abstain: Optimal Selective Classification with Likelihood Ratios
May 21, 2025Selective classification enhances the reliability of predictive models by allowing them to abstain from making uncertain predictions. In this work, we revisit the design of optimal selection functions through the lens of the Neyman--Pearson lemma, a classical result in statistics that characterizes the optimal rejection rule as a likelihood ratio test. We show that this perspective not only unifies the behavior of several post-hoc selection baselines, but also motivates new approaches to selective classification which we propose here. A central focus of our work is the setting of covariate shift, where the input distribution at test time differs from that at training. This realistic and challenging scenario remains relatively underexplored in the context of selective classification. We evaluate our proposed methods across a range of vision and language tasks, including both supervised learning and vision-language models. Our experiments demonstrate that our Neyman--Pearson-informed methods consistently outperform existing baselines, indicating that likelihood ratio-based selection offers a robust mechanism for improving selective classification under covariate shifts. Our code is publicly available at https://github.com/clear-nus/sc-likelihood-ratios.
CHD: Coupled Hierarchical Diffusion for Long-Horizon Tasks
May 13, 2025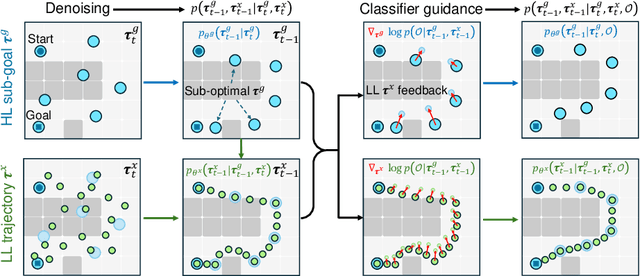
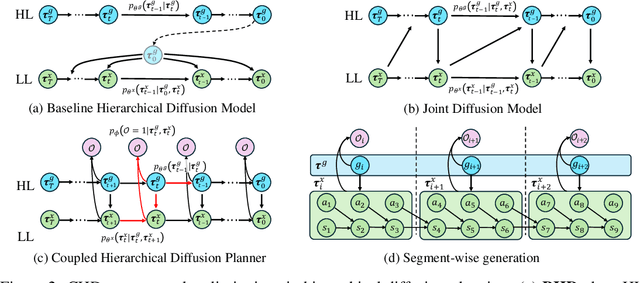
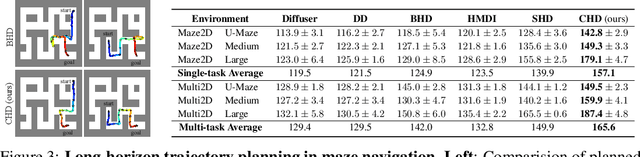
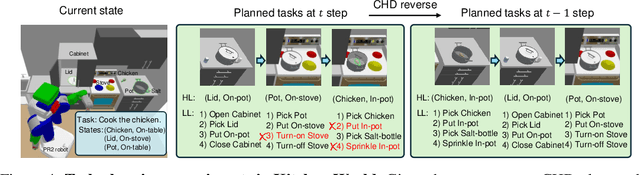
Diffusion-based planners have shown strong performance in short-horizon tasks but often fail in complex, long-horizon settings. We trace the failure to loose coupling between high-level (HL) sub-goal selection and low-level (LL) trajectory generation, which leads to incoherent plans and degraded performance. We propose Coupled Hierarchical Diffusion (CHD), a framework that models HL sub-goals and LL trajectories jointly within a unified diffusion process. A shared classifier passes LL feedback upstream so that sub-goals self-correct while sampling proceeds. This tight HL-LL coupling improves trajectory coherence and enables scalable long-horizon diffusion planning. Experiments across maze navigation, tabletop manipulation, and household environments show that CHD consistently outperforms both flat and hierarchical diffusion baselines. Our website is: https://sites.google.com/view/chd2025/home
SocRATES: Towards Automated Scenario-based Testing of Social Navigation Algorithms
Dec 27, 2024Current social navigation methods and benchmarks primarily focus on proxemics and task efficiency. While these factors are important, qualitative aspects such as perceptions of a robot's social competence are equally crucial for successful adoption and integration into human environments. We propose a more comprehensive evaluation of social navigation through scenario-based testing, where specific human-robot interaction scenarios can reveal key robot behaviors. However, creating such scenarios is often labor-intensive and complex. In this work, we address this challenge by introducing a pipeline that automates the generation of context-, and location-appropriate social navigation scenarios, ready for simulation. Our pipeline transforms simple scenario metadata into detailed textual scenarios, infers pedestrian and robot trajectories, and simulates pedestrian behaviors, which enables more controlled evaluation. We leverage the social reasoning and code-generation capabilities of Large Language Models (LLMs) to streamline scenario generation and translation. Our experiments show that our pipeline produces realistic scenarios and significantly improves scenario translation over naive LLM prompting. Additionally, we present initial feedback from a usability study with social navigation experts and a case-study demonstrating a scenario-based evaluation of three navigation algorithms.