 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025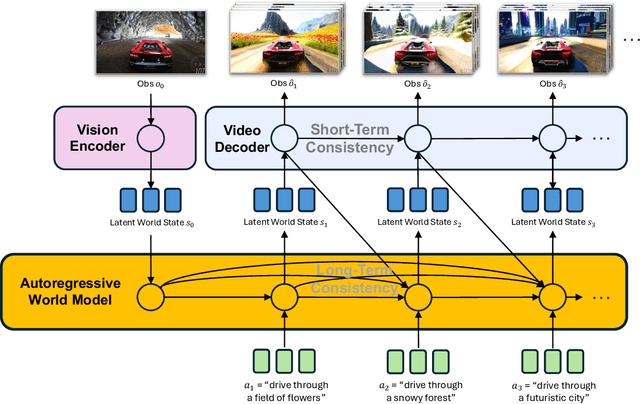
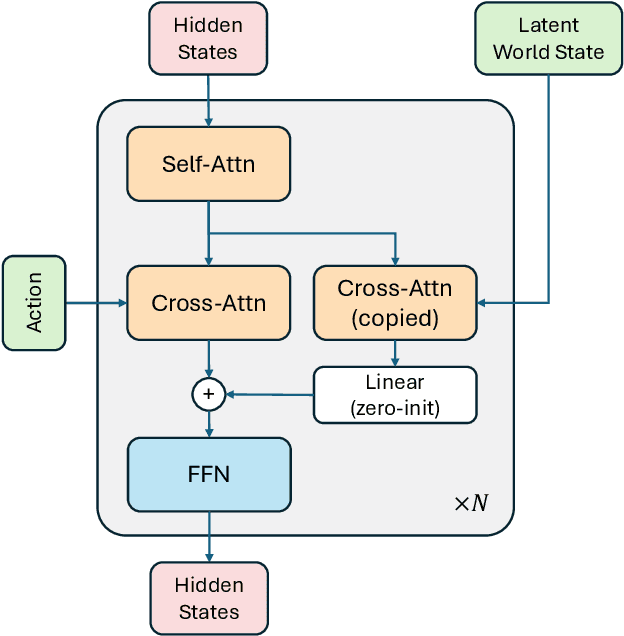
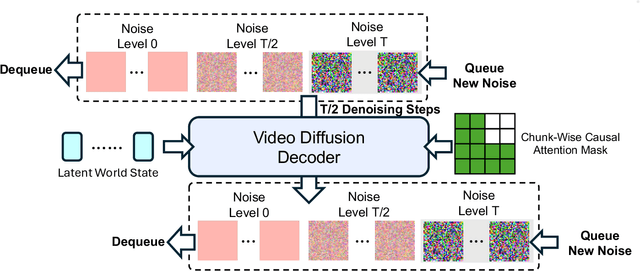
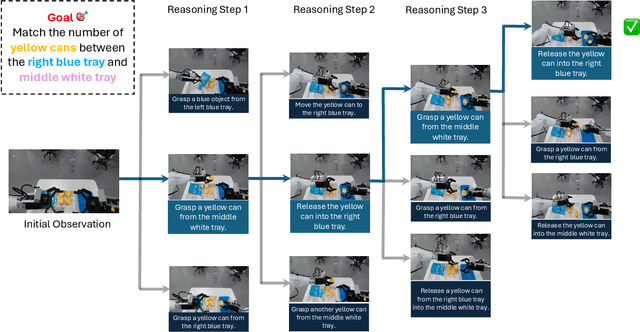
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Diffusion Meets Options: Hierarchical Generative Skill Composition for Temporally-Extended Tasks
Oct 03, 2024



Safe and successful deployment of robots requires not only the ability to generate complex plans but also the capacity to frequently replan and correct execution errors. This paper addresses the challenge of long-horizon trajectory planning under temporally extended objectives in a receding horizon manner. To this end, we propose DOPPLER, a data-driven hierarchical framework that generates and updates plans based on instruction specified by linear temporal logic (LTL). Our method decomposes temporal tasks into chain of options with hierarchical reinforcement learning from offline non-expert datasets. It leverages diffusion models to generate options with low-level actions. We devise a determinantal-guided posterior sampling technique during batch generation, which improves the speed and diversity of diffusion generated options, leading to more efficient querying. Experiments on robot navigation and manipulation tasks demonstrate that DOPPLER can generate sequences of trajectories that progressively satisfy the specified formulae for obstacle avoidance and sequential visitation. Demonstration videos are available online at: https://philiptheother.github.io/doppler/.
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
LTLDoG: Satisfying Temporally-Extended Symbolic Constraints for Safe Diffusion-based Planning
May 07, 2024



Operating effectively in complex environments while complying with specified constraints is crucial for the safe and successful deployment of robots that interact with and operate around people. In this work, we focus on generating long-horizon trajectories that adhere to novel static and temporally-extended constraints/instructions at test time. We propose a data-driven diffusion-based framework, LTLDoG, that modifies the inference steps of the reverse process given an instruction specified using finite linear temporal logic ($\text{LTL}_f$). LTLDoG leverages a satisfaction value function on $\text{LTL}_f$ and guides the sampling steps using its gradient field. This value function can also be trained to generalize to new instructions not observed during training, enabling flexible test-time adaptability. Experiments in robot navigation and manipulation illustrate that the method is able to generate trajectories that satisfy formulae that specify obstacle avoidance and visitation sequences.
Generating, Reconstructing, and Representing Discrete and Continuous Data: Generalized Diffusion with Learnable Encoding-Decoding
Feb 29, 2024The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), autoregressive models, and diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce generalized diffusion with learnable encoder-decoder (DiLED), that seamlessly integrates the core capabilities for broad applicability and enhanced performance. DiLED generalizes the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, DiLED is compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), DiLED naturally applies to different data types. Extensive experiments on text, proteins, and images demonstrate DiLED's flexibility to handle diverse data and tasks and its strong improvement over various existing models.
Synslator: An Interactive Machine Translation Tool with Online Learning
Oct 08, 2023



Interactive machine translation (IMT) has emerged as a progression of the computer-aided translation paradigm, where the machine translation system and the human translator collaborate to produce high-quality translations. This paper introduces Synslator, a user-friendly computer-aided translation (CAT) tool that not only supports IMT, but is adept at online learning with real-time translation memories. To accommodate various deployment environments for CAT services, Synslator integrates two different neural translation models to handle translation memories for online learning. Additionally, the system employs a language model to enhance the fluency of translations in an interactive mode. In evaluation, we have confirmed the effectiveness of online learning through the translation models, and have observed a 13% increase in post-editing efficiency with the interactive functionalities of Synslator. A tutorial video is available at:https://youtu.be/K0vRsb2lTt8.
Safety-Constrained Policy Transfer with Successor Features
Nov 10, 2022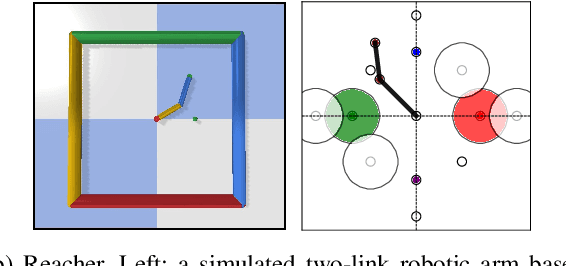
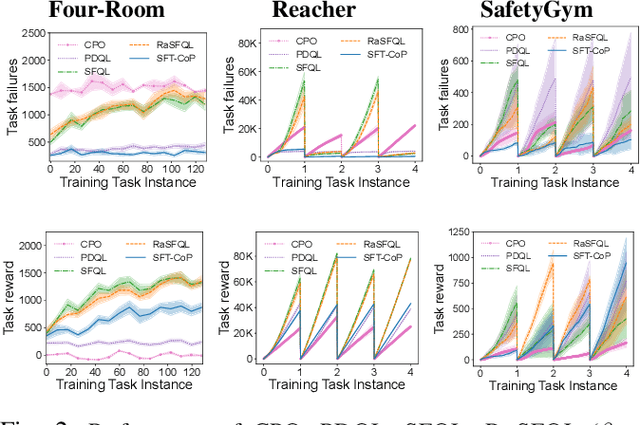


In this work, we focus on the problem of safe policy transfer in reinforcement learning: we seek to leverage existing policies when learning a new task with specified constraints. This problem is important for safety-critical applications where interactions are costly and unconstrained policies can lead to undesirable or dangerous outcomes, e.g., with physical robots that interact with humans. We propose a Constrained Markov Decision Process (CMDP) formulation that simultaneously enables the transfer of policies and adherence to safety constraints. Our formulation cleanly separates task goals from safety considerations and permits the specification of a wide variety of constraints. Our approach relies on a novel extension of generalized policy improvement to constrained settings via a Lagrangian formulation. We devise a dual optimization algorithm that estimates the optimal dual variable of a target task, thus enabling safe transfer of policies derived from successor features learned on source tasks. Our experiments in simulated domains show that our approach is effective; it visits unsafe states less frequently and outperforms alternative state-of-the-art methods when taking safety constraints into account.
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
Aug 01, 2022

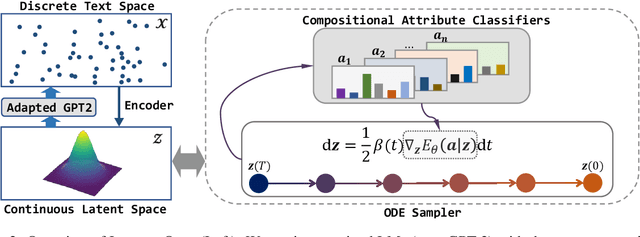
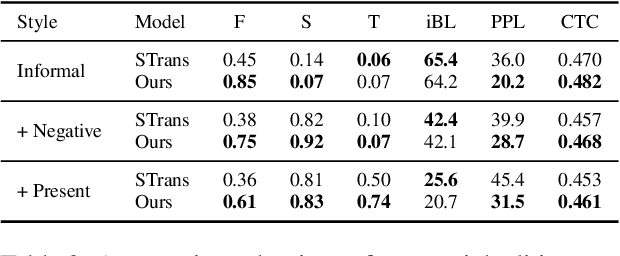
Real-world text applications often involve composing a wide range of text control operations, such as editing the text w.r.t. an attribute, manipulating keywords and structure, and generating new text of desired properties. Prior work typically learns/finetunes a language model (LM) to perform individual or specific subsets of operations. Recent research has studied combining operations in a plug-and-play manner, often with costly search or optimization in the complex sequence space. This paper proposes a new efficient approach for composable text operations in the compact latent space of text. The low-dimensionality and differentiability of the text latent vector allow us to develop an efficient sampler based on ordinary differential equations (ODEs) given arbitrary plug-in operators (e.g., attribute classifiers). By connecting pretrained LMs (e.g., GPT2) to the latent space through efficient adaption, we then decode the sampled vectors into desired text sequences. The flexible approach permits diverse control operators (sentiment, tense, formality, keywords, etc.) acquired using any relevant data from different domains. Experiments show that composing those operators within our approach manages to generate or edit high-quality text, substantially improving over previous methods in terms of generation quality and efficiency.
Open-Set Hypothesis Transfer with Semantic Consistency
Oct 01, 2020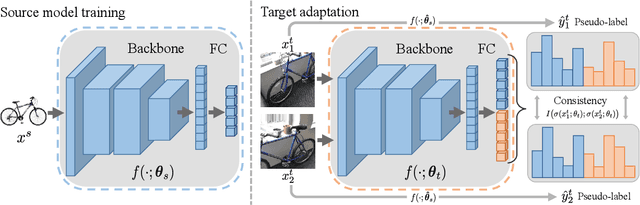
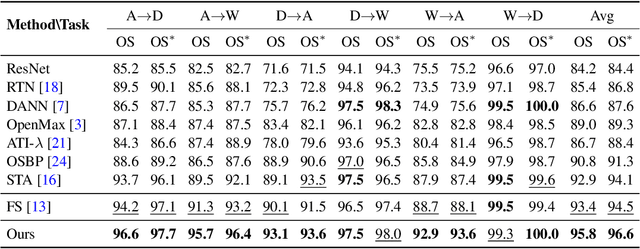
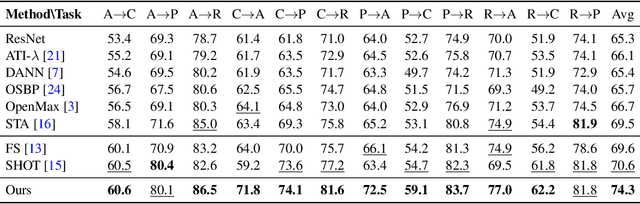
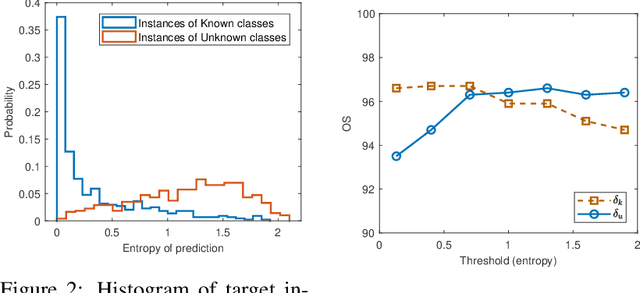
Unsupervised open-set domain adaptation (UODA) is a realistic problem where unlabeled target data contain unknown classes. Prior methods rely on the coexistence of both source and target domain data to perform domain alignment, which greatly limits their applications when source domain data are restricted due to privacy concerns. This paper addresses the challenging hypothesis transfer setting for UODA, where data from source domain are no longer available during adaptation on target domain. We introduce a method that focuses on the semantic consistency under transformation of target data, which is rarely appreciated by previous domain adaptation methods. Specifically, our model first discovers confident predictions and performs classification with pseudo-labels. Then we enforce the model to output consistent and definite predictions on semantically similar inputs. As a result, unlabeled data can be classified into discriminative classes coincided with either source classes or unknown classes. Experimental results show that our model outperforms state-of-the-art methods on UODA benchmarks.