 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaMath: Pushing the Limits of Open Math Corpora
Apr 03, 2025



Mathematical reasoning is a cornerstone of human intelligence and a key benchmark for advanced capabilities in large language models (LLMs). However, the research community still lacks an open, large-scale, high-quality corpus tailored to the demands of math-centric LLM pre-training. We present MegaMath, an open dataset curated from diverse, math-focused sources through following practices: (1) Revisiting web data: We re-extracted mathematical documents from Common Crawl with math-oriented HTML optimizations, fasttext-based filtering and deduplication, all for acquiring higher-quality data on the Internet. (2) Recalling Math-related code data: We identified high quality math-related code from large code training corpus, Stack-V2, further enhancing data diversity. (3) Exploring Synthetic data: We synthesized QA-style text, math-related code, and interleaved text-code blocks from web data or code data. By integrating these strategies and validating their effectiveness through extensive ablations, MegaMath delivers 371B tokens with the largest quantity and top quality among existing open math pre-training datasets.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Generating, Reconstructing, and Representing Discrete and Continuous Data: Generalized Diffusion with Learnable Encoding-Decoding
Feb 29, 2024The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), autoregressive models, and diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce generalized diffusion with learnable encoder-decoder (DiLED), that seamlessly integrates the core capabilities for broad applicability and enhanced performance. DiLED generalizes the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, DiLED is compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), DiLED naturally applies to different data types. Extensive experiments on text, proteins, and images demonstrate DiLED's flexibility to handle diverse data and tasks and its strong improvement over various existing models.
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
Learning to optimize by multi-gradient for multi-objective optimization
Nov 01, 2023



The development of artificial intelligence (AI) for science has led to the emergence of learning-based research paradigms, necessitating a compelling reevaluation of the design of multi-objective optimization (MOO) methods. The new generation MOO methods should be rooted in automated learning rather than manual design. In this paper, we introduce a new automatic learning paradigm for optimizing MOO problems, and propose a multi-gradient learning to optimize (ML2O) method, which automatically learns a generator (or mappings) from multiple gradients to update directions. As a learning-based method, ML2O acquires knowledge of local landscapes by leveraging information from the current step and incorporates global experience extracted from historical iteration trajectory data. By introducing a new guarding mechanism, we propose a guarded multi-gradient learning to optimize (GML2O) method, and prove that the iterative sequence generated by GML2O converges to a Pareto critical point. The experimental results demonstrate that our learned optimizer outperforms hand-designed competitors on training multi-task learning (MTL) neural network.
Robust Unsupervised Cross-Lingual Word Embedding using Domain Flow Interpolation
Oct 07, 2022
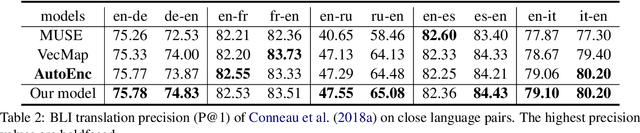

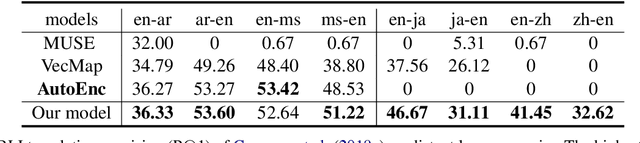
This paper investigates an unsupervised approach towards deriving a universal, cross-lingual word embedding space, where words with similar semantics from different languages are close to one another. Previous adversarial approaches have shown promising results in inducing cross-lingual word embedding without parallel data. However, the training stage shows instability for distant language pairs. Instead of mapping the source language space directly to the target language space, we propose to make use of a sequence of intermediate spaces for smooth bridging. Each intermediate space may be conceived as a pseudo-language space and is introduced via simple linear interpolation. This approach is modeled after domain flow in computer vision, but with a modified objective function. Experiments on intrinsic Bilingual Dictionary Induction tasks show that the proposed approach can improve the robustness of adversarial models with comparable and even better precision. Further experiments on the downstream task of Cross-Lingual Natural Language Inference show that the proposed model achieves significant performance improvement for distant language pairs in downstream tasks compared to state-of-the-art adversarial and non-adversarial models.