 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Empowered Cooperative Content Caching in Vehicular Fog Caching-Assisted Platoon Networks
Feb 04, 2026This letter proposes a novel three-tier content caching architecture for Vehicular Fog Caching (VFC)-assisted platoon, where the VFC is formed by the vehicles driving near the platoon. The system strategically coordinates storage across local platoon vehicles, dynamic VFC clusters, and cloud server (CS) to minimize content retrieval latency. To efficiently manage distributed storage, we integrate large language models (LLMs) for real-time and intelligent caching decisions. The proposed approach leverages LLMs' ability to process heterogeneous information, including user profiles, historical data, content characteristics, and dynamic system states. Through a designed prompting framework encoding task objectives and caching constraints, the LLMs formulate caching as a decision-making task, and our hierarchical deterministic caching mapping strategy enables adaptive requests prediction and precise content placement across three tiers without frequent retraining. Simulation results demonstrate the advantages of our proposed caching scheme.
M3PO: Multimodal-Model-Guided Preference Optimization for Visual Instruction Following
Aug 17, 2025Large Vision-Language Models (LVLMs) hold immense potential for complex multimodal instruction following, yet their development is often hindered by the high cost and inconsistency of human annotation required for effective fine-tuning and preference alignment. Traditional supervised fine-tuning (SFT) and existing preference optimization methods like RLHF and DPO frequently struggle to efficiently leverage the model's own generation space to identify highly informative "hard negative" samples. To address these challenges, we propose Multimodal-Model-Guided Preference Optimization (M3PO), a novel and data-efficient method designed to enhance LVLMs' capabilities in visual instruction following. M3PO intelligently selects the most "learning-valuable" preference sample pairs from a diverse pool of LVLM-generated candidates. This selection is driven by a sophisticated mechanism that integrates two crucial signals: a Multimodal Alignment Score (MAS) to assess external quality and the model's Self-Consistency / Confidence (log-probability) to gauge internal belief. These are combined into a novel M3P-Score, which specifically identifies preferred responses and challenging dispreferred responses that the model might confidently generate despite being incorrect. These high-quality preference pairs are then used for efficient Direct Preference Optimization (DPO) fine-tuning on base LVLMs like LLaVA-1.5 (7B/13B) using LoRA. Our extensive experiments demonstrate that M3PO consistently outperforms strong baselines, including SFT, simulated RLHF, vanilla DPO, and RM-DPO, across a comprehensive suite of multimodal instruction following benchmarks (MME-Bench, POPE, IFT, Human Pref. Score).
Fast MLE and MAPE-Based Device Activity Detection for Grant-Free Access via PSCA and PSCA-Net
Mar 19, 2025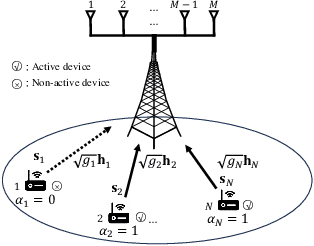
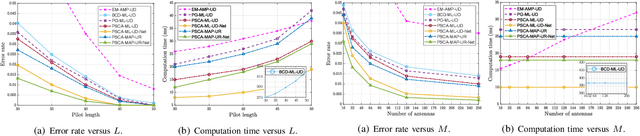
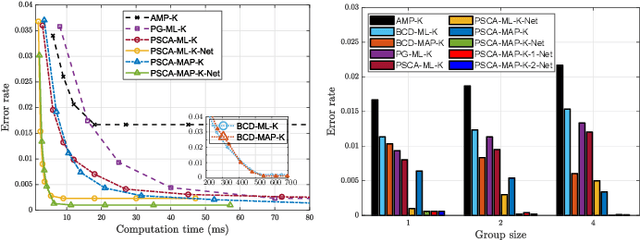
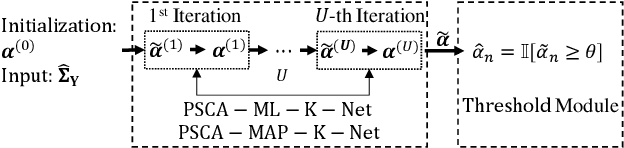
Fast and accurate device activity detection is the critical challenge in grant-free access for supporting massive machine-type communications (mMTC) and ultra-reliable low-latency communications (URLLC) in 5G and beyond. The state-of-the-art methods have unsatisfactory error rates or computation times. To address these outstanding issues, we propose new maximum likelihood estimation (MLE) and maximum a posterior estimation (MAPE) based device activity detection methods for known and unknown pathloss that achieve superior error rate and computation time tradeoffs using optimization and deep learning techniques. Specifically, we investigate four non-convex optimization problems for MLE and MAPE in the two pathloss cases, with one MAPE problem being formulated for the first time. For each non-convex problem, we develop an innovative parallel iterative algorithm using the parallel successive convex approximation (PSCA) method. Each PSCA-based algorithm allows parallel computations, uses up to the objective function's second-order information, converges to the problem's stationary points, and has a low per-iteration computational complexity compared to the state-of-the-art algorithms. Then, for each PSCA-based iterative algorithm, we present a deep unrolling neural network implementation, called PSCA-Net, to further reduce the computation time. Each PSCA-Net elegantly marries the underlying PSCA-based algorithm's parallel computation mechanism with the parallelizable neural network architecture and effectively optimizes its step sizes based on vast data samples to speed up the convergence. Numerical results demonstrate that the proposed methods can significantly reduce the error rate and computation time compared to the state-of-the-art methods, revealing their significant values for grant-free access.
Synthesizing Privacy-Preserving Text Data via Finetuning without Finetuning Billion-Scale LLMs
Mar 16, 2025Synthetic data offers a promising path to train models while preserving data privacy. Differentially private (DP) finetuning of large language models (LLMs) as data generator is effective, but is impractical when computation resources are limited. Meanwhile, prompt-based methods such as private evolution, depend heavily on the manual prompts, and ineffectively use private information in their iterative data selection process. To overcome these limitations, we propose CTCL (Data Synthesis with ConTrollability and CLustering), a novel framework for generating privacy-preserving synthetic data without extensive prompt engineering or billion-scale LLM finetuning. CTCL pretrains a lightweight 140M conditional generator and a clustering-based topic model on large-scale public data. To further adapt to the private domain, the generator is DP finetuned on private data for fine-grained textual information, while the topic model extracts a DP histogram representing distributional information. The DP generator then samples according to the DP histogram to synthesize a desired number of data examples. Evaluation across five diverse domains demonstrates the effectiveness of our framework, particularly in the strong privacy regime. Systematic ablation validates the design of each framework component and highlights the scalability of our approach.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024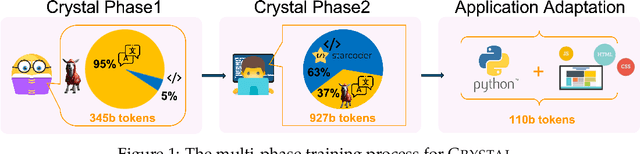
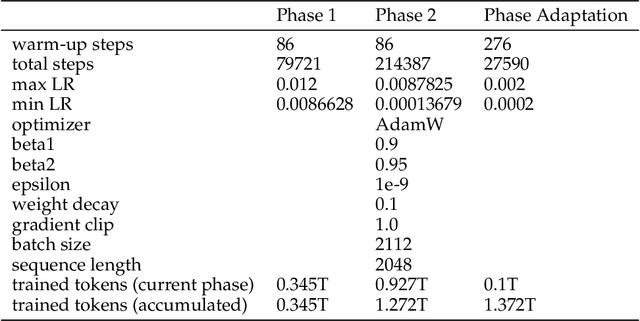
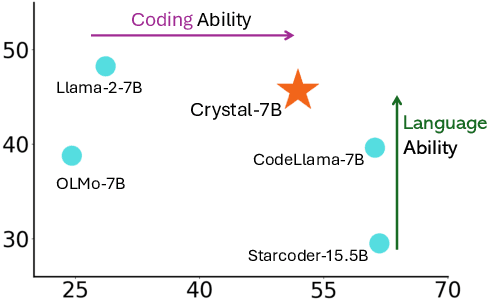
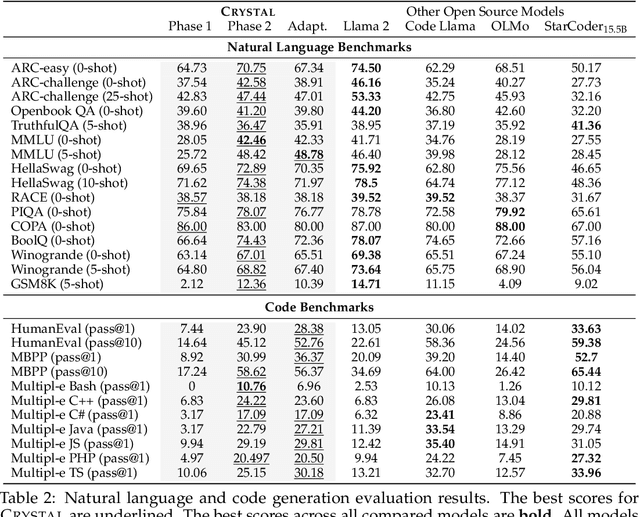
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Model-GLUE: Democratized LLM Scaling for A Large Model Zoo in the Wild
Oct 07, 2024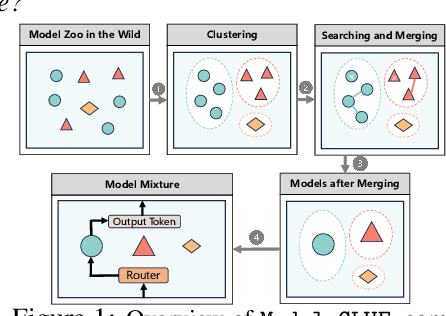

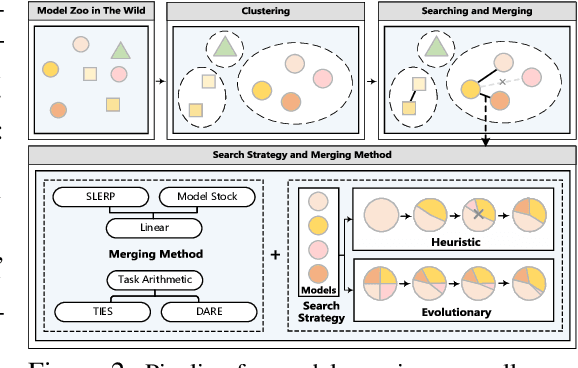
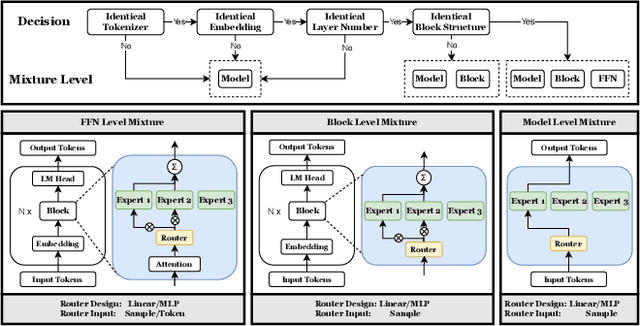
As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has garnered significant attention, which faces the challenge of decreasing performance when combining disparate models. Various techniques have been proposed for the aggregation of pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed. In light of this research gap, this paper introduces Model-GLUE, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate an strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization. Our methodology involves the clustering of mergeable models and optimal merging strategy selection, and the integration of clusters through a model mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, Model-GLUE shows an average performance enhancement of 5.61%, achieved without additional training. Codes are available at: https://github.com/Model-GLUE/Model-GLUE.
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer
Nov 12, 2023Large language models (LLMs) such as T0, FLAN, and OPT-IML, excel in multi-tasking under a unified instruction-following paradigm, where they also exhibit remarkable generalization abilities to unseen tasks. Despite their impressive performance, these LLMs, with sizes ranging from several billion to hundreds of billions of parameters, demand substantial computational resources, making their training and inference expensive and inefficient. Furthermore, adapting these models to downstream applications, particularly complex tasks, is often unfeasible due to the extensive hardware requirements for finetuning, even when utilizing parameter-efficient approaches such as prompt tuning. Additionally, the most powerful multi-task LLMs, such as OPT-IML-175B and FLAN-PaLM-540B, are not publicly accessible, severely limiting their customization potential. To address these challenges, we introduce a pretrained small scorer, Cappy, designed to enhance the performance and efficiency of multi-task LLMs. With merely 360 million parameters, Cappy functions either independently on classification tasks or serve as an auxiliary component for LLMs, boosting their performance. Moreover, Cappy enables efficiently integrating downstream supervision without requiring LLM finetuning nor the access to their parameters. Our experiments demonstrate that, when working independently on 11 language understanding tasks from PromptSource, Cappy outperforms LLMs that are several orders of magnitude larger. Besides, on 45 complex tasks from BIG-Bench, Cappy boosts the performance of the advanced multi-task LLM, FLAN-T5, by a large margin. Furthermore, Cappy is flexible to cooperate with other LLM adaptations, including finetuning and in-context learning, offering additional performance enhancement.