 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025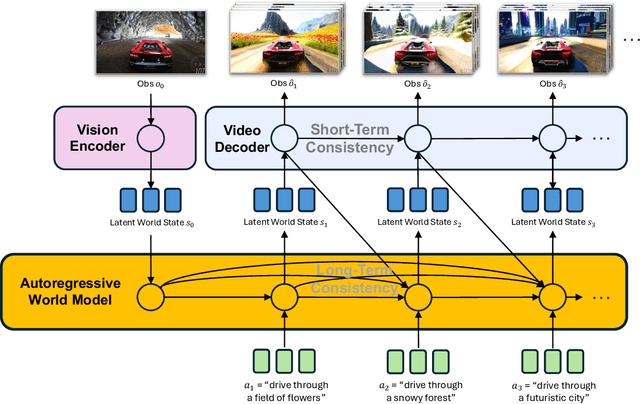
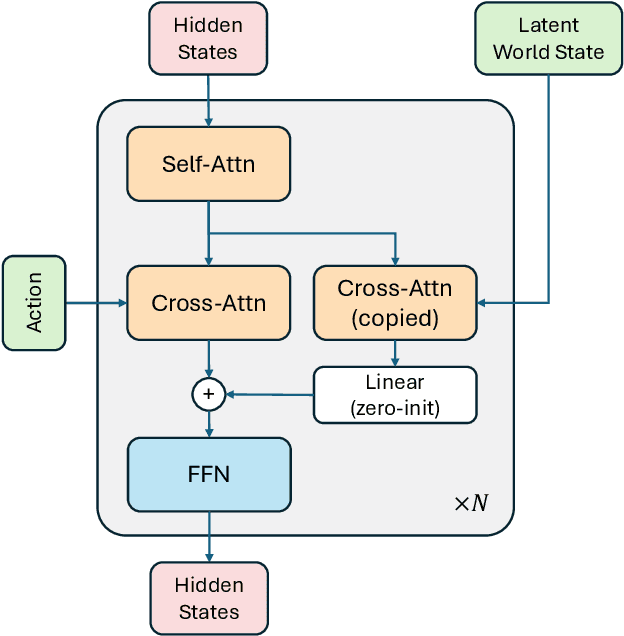
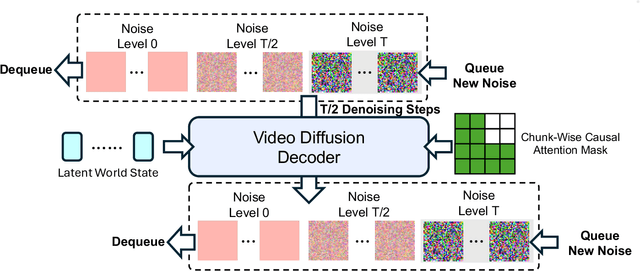
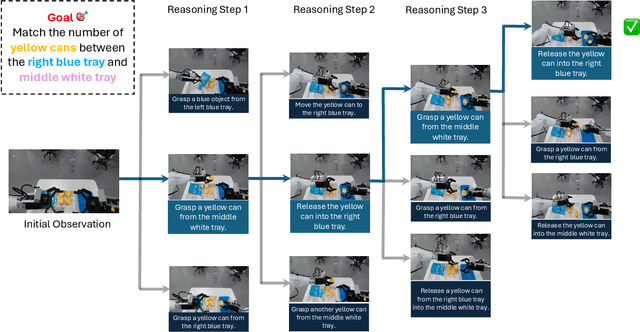
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025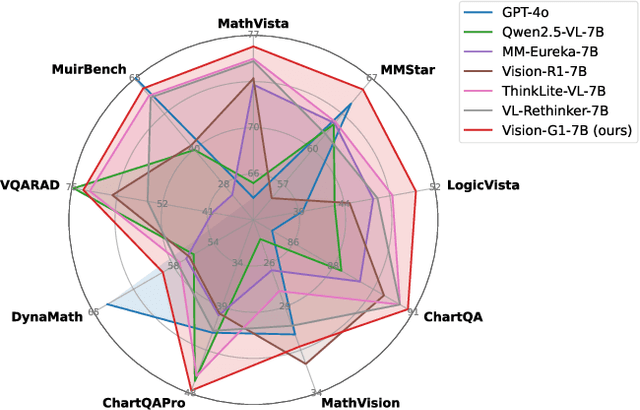
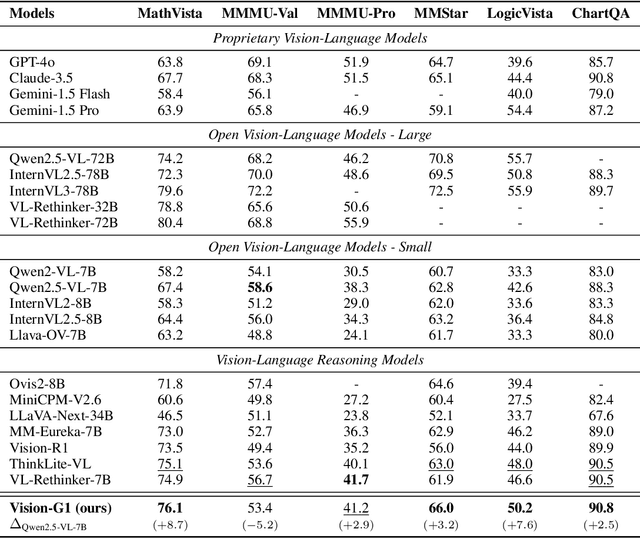
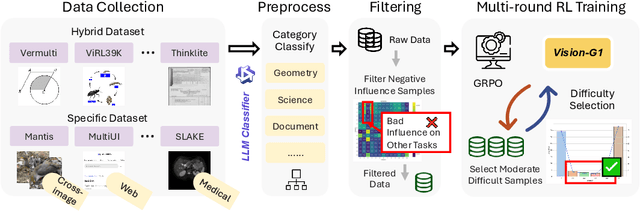
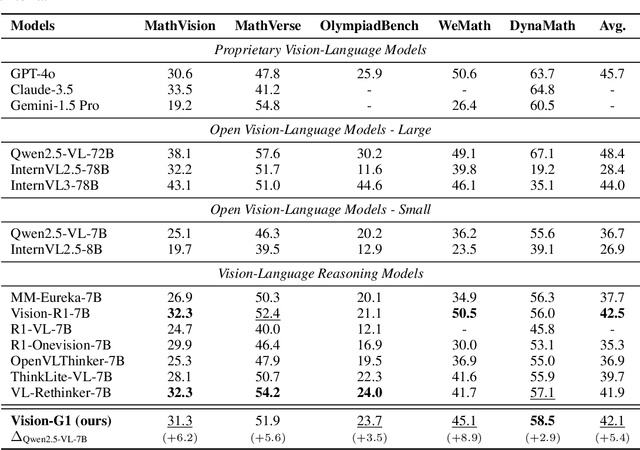
Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025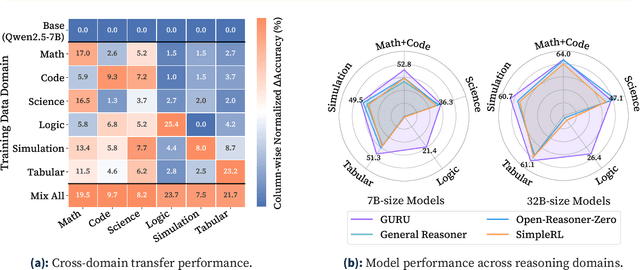
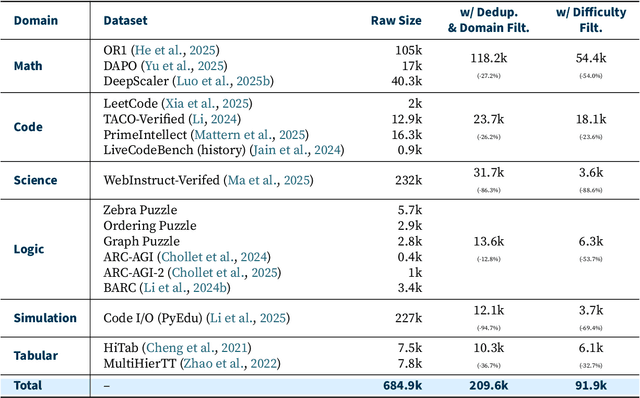
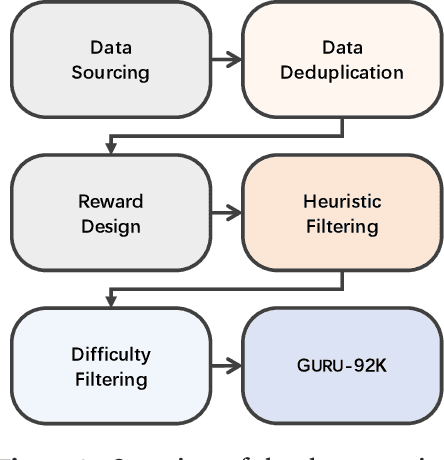

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
May 19, 2025



The recent explosion of large language models (LLMs), each with its own general or specialized strengths, makes scalable, reliable benchmarking more urgent than ever. Standard practices nowadays face fundamental trade-offs: closed-ended question-based benchmarks (eg MMLU) struggle with saturation as newer models emerge, while crowd-sourced leaderboards (eg Chatbot Arena) rely on costly and slow human judges. Recently, automated methods (eg LLM-as-a-judge) shed light on the scalability, but risk bias by relying on one or a few "authority" models. To tackle these issues, we propose Decentralized Arena (dearena), a fully automated framework leveraging collective intelligence from all LLMs to evaluate each other. It mitigates single-model judge bias by democratic, pairwise evaluation, and remains efficient at scale through two key components: (1) a coarse-to-fine ranking algorithm for fast incremental insertion of new models with sub-quadratic complexity, and (2) an automatic question selection strategy for the construction of new evaluation dimensions. Across extensive experiments across 66 LLMs, dearena attains up to 97% correlation with human judgements, while significantly reducing the cost. Our code and data will be publicly released on https://github.com/maitrix-org/de-arena.
Faster Video Diffusion with Trainable Sparse Attention
May 19, 2025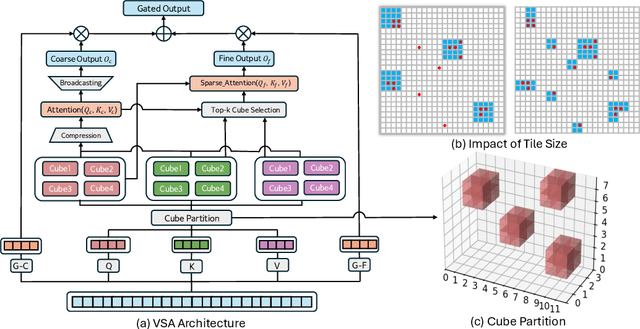
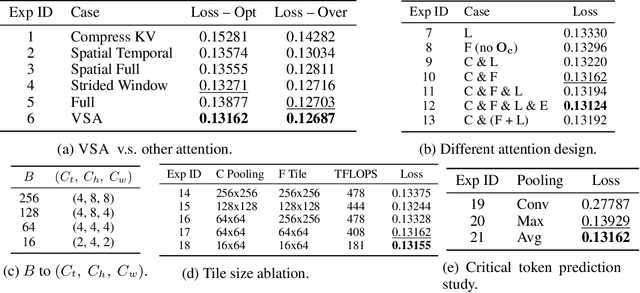
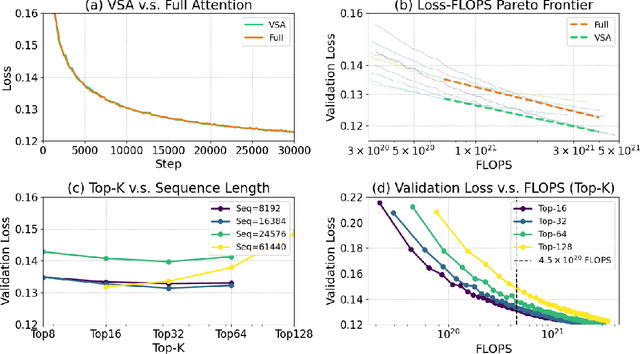
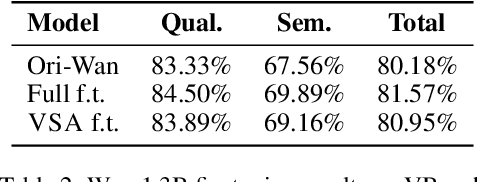
Scaling video diffusion transformers (DiTs) is limited by their quadratic 3D attention, even though most of the attention mass concentrates on a small subset of positions. We turn this observation into VSA, a trainable, hardware-efficient sparse attention that replaces full attention at \emph{both} training and inference. In VSA, a lightweight coarse stage pools tokens into tiles and identifies high-weight \emph{critical tokens}; a fine stage computes token-level attention only inside those tiles subjecting to block computing layout to ensure hard efficiency. This leads to a single differentiable kernel that trains end-to-end, requires no post-hoc profiling, and sustains 85\% of FlashAttention3 MFU. We perform a large sweep of ablation studies and scaling-law experiments by pretraining DiTs from 60M to 1.4B parameters. VSA reaches a Pareto point that cuts training FLOPS by 2.53$\times$ with no drop in diffusion loss. Retrofitting the open-source Wan-2.1 model speeds up attention time by 6$\times$ and lowers end-to-end generation time from 31s to 18s with comparable quality. These results establish trainable sparse attention as a practical alternative to full attention and a key enabler for further scaling of video diffusion models.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025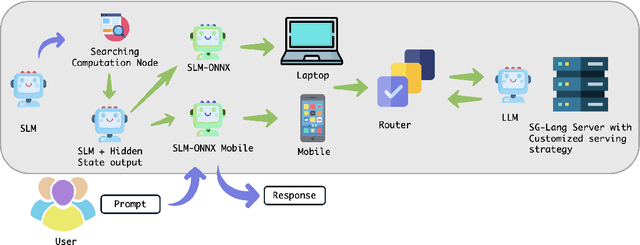
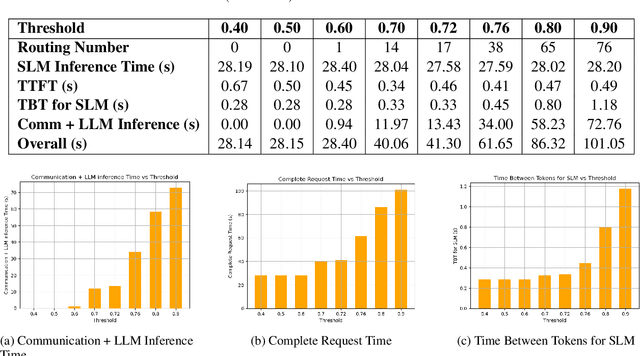
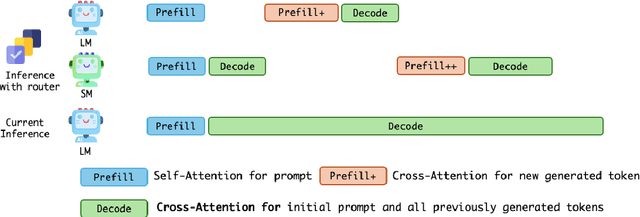
The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
MegaMath: Pushing the Limits of Open Math Corpora
Apr 03, 2025



Mathematical reasoning is a cornerstone of human intelligence and a key benchmark for advanced capabilities in large language models (LLMs). However, the research community still lacks an open, large-scale, high-quality corpus tailored to the demands of math-centric LLM pre-training. We present MegaMath, an open dataset curated from diverse, math-focused sources through following practices: (1) Revisiting web data: We re-extracted mathematical documents from Common Crawl with math-oriented HTML optimizations, fasttext-based filtering and deduplication, all for acquiring higher-quality data on the Internet. (2) Recalling Math-related code data: We identified high quality math-related code from large code training corpus, Stack-V2, further enhancing data diversity. (3) Exploring Synthetic data: We synthesized QA-style text, math-related code, and interleaved text-code blocks from web data or code data. By integrating these strategies and validating their effectiveness through extensive ablations, MegaMath delivers 371B tokens with the largest quantity and top quality among existing open math pre-training datasets.
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
Feb 04, 2025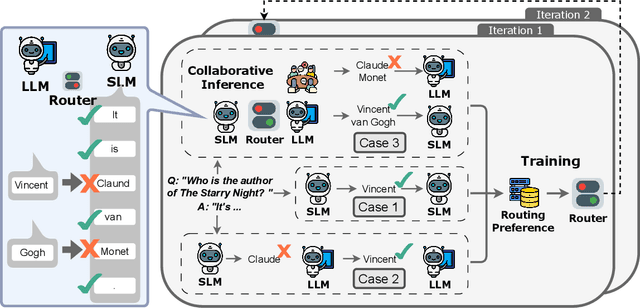
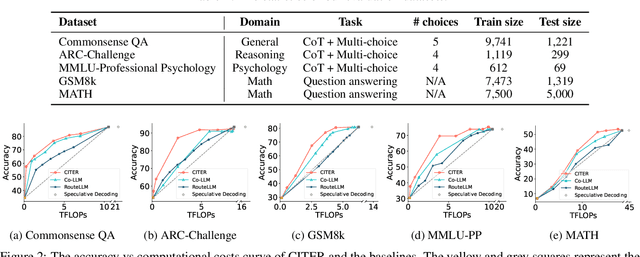
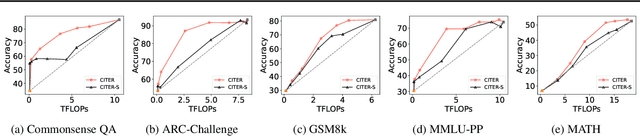
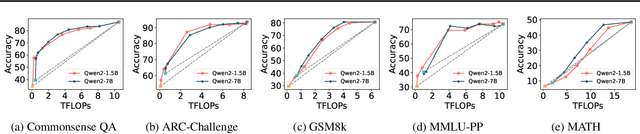
Large language models have achieved remarkable success in various tasks but suffer from high computational costs during inference, limiting their deployment in resource-constrained applications. To address this issue, we propose a novel CITER (\textbf{C}ollaborative \textbf{I}nference with \textbf{T}oken-l\textbf{E}vel \textbf{R}outing) framework that enables efficient collaboration between small and large language models (SLMs & LLMs) through a token-level routing strategy. Specifically, CITER routes non-critical tokens to an SLM for efficiency and routes critical tokens to an LLM for generalization quality. We formulate router training as a policy optimization, where the router receives rewards based on both the quality of predictions and the inference costs of generation. This allows the router to learn to predict token-level routing scores and make routing decisions based on both the current token and the future impact of its decisions. To further accelerate the reward evaluation process, we introduce a shortcut which significantly reduces the costs of the reward estimation and improving the practicality of our approach. Extensive experiments on five benchmark datasets demonstrate that CITER reduces the inference costs while preserving high-quality generation, offering a promising solution for real-time and resource-constrained applications.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.