 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
Turn-PPO: Turn-Level Advantage Estimation with PPO for Improved Multi-Turn RL in Agentic LLMs
Dec 18, 2025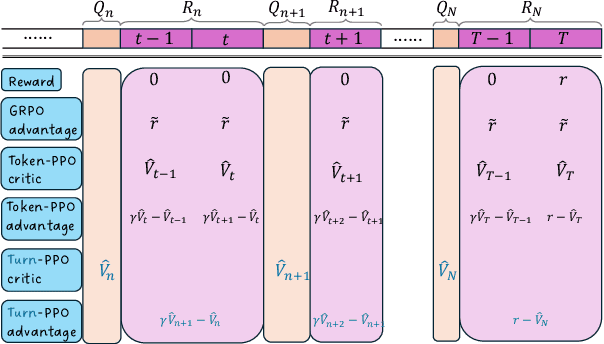

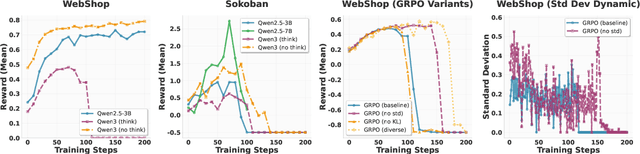
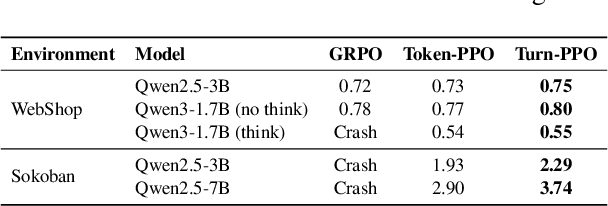
Reinforcement learning (RL) has re-emerged as a natural approach for training interactive LLM agents in real-world environments. However, directly applying the widely used Group Relative Policy Optimization (GRPO) algorithm to multi-turn tasks exposes notable limitations, particularly in scenarios requiring long-horizon reasoning. To address these challenges, we investigate more stable and effective advantage estimation strategies, especially for multi-turn settings. We first explore Proximal Policy Optimization (PPO) as an alternative and find it to be more robust than GRPO. To further enhance PPO in multi-turn scenarios, we introduce turn-PPO, a variant that operates on a turn-level MDP formulation, as opposed to the commonly used token-level MDP. Our results on the WebShop and Sokoban datasets demonstrate the effectiveness of turn-PPO, both with and without long reasoning components.
HALoS: Hierarchical Asynchronous Local SGD over Slow Networks for Geo-Distributed Large Language Model Training
Jun 05, 2025Training large language models (LLMs) increasingly relies on geographically distributed accelerators, causing prohibitive communication costs across regions and uneven utilization of heterogeneous hardware. We propose HALoS, a hierarchical asynchronous optimization framework that tackles these issues by introducing local parameter servers (LPSs) within each region and a global parameter server (GPS) that merges updates across regions. This hierarchical design minimizes expensive inter-region communication, reduces straggler effects, and leverages fast intra-region links. We provide a rigorous convergence analysis for HALoS under non-convex objectives, including theoretical guarantees on the role of hierarchical momentum in asynchronous training. Empirically, HALoS attains up to 7.5x faster convergence than synchronous baselines in geo-distributed LLM training and improves upon existing asynchronous methods by up to 2.1x. Crucially, HALoS preserves the model quality of fully synchronous SGD-matching or exceeding accuracy on standard language modeling and downstream benchmarks-while substantially lowering total training time. These results demonstrate that hierarchical, server-side update accumulation and global model merging are powerful tools for scalable, efficient training of new-era LLMs in heterogeneous, geo-distributed environments.
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Jun 04, 2025LLMs have shown impressive progress in natural language processing. However, they still face significant challenges in TableQA, where real-world complexities such as diverse table structures, multilingual data, and domain-specific reasoning are crucial. Existing TableQA benchmarks are often limited by their focus on simple flat tables and suffer from data leakage. Furthermore, most benchmarks are monolingual and fail to capture the cross-lingual and cross-domain variability in practical applications. To address these limitations, we introduce TableEval, a new benchmark designed to evaluate LLMs on realistic TableQA tasks. Specifically, TableEval includes tables with various structures (such as concise, hierarchical, and nested tables) collected from four domains (including government, finance, academia, and industry reports). Besides, TableEval features cross-lingual scenarios with tables in Simplified Chinese, Traditional Chinese, and English. To minimize the risk of data leakage, we collect all data from recent real-world documents. Considering that existing TableQA metrics fail to capture semantic accuracy, we further propose SEAT, a new evaluation framework that assesses the alignment between model responses and reference answers at the sub-question level. Experimental results have shown that SEAT achieves high agreement with human judgment. Extensive experiments on TableEval reveal critical gaps in the ability of state-of-the-art LLMs to handle these complex, real-world TableQA tasks, offering insights for future improvements. We make our dataset available here: https://github.com/wenge-research/TableEval.
PIPA: Preference Alignment as Prior-Informed Statistical Estimation
Feb 09, 2025Offline preference alignment for language models such as Direct Preference Optimization (DPO) is favored for its effectiveness and simplicity, eliminating the need for costly reinforcement learning. Various offline algorithms have been developed for different data settings, yet they lack a unified understanding. In this study, we introduce Pior-Informed Preference Alignment (PIPA), a unified, RL-free probabilistic framework that formulates language model preference alignment as a Maximum Likelihood Estimation (MLE) problem with prior constraints. This method effectively accommodates both paired and unpaired data, as well as answer and step-level annotations. We illustrate that DPO and KTO are special cases with different prior constraints within our framework. By integrating different types of prior information, we developed two variations of PIPA: PIPA-M and PIPA-N. Both algorithms demonstrate a $3\sim10\%$ performance enhancement on the GSM8K and MATH benchmarks across all configurations, achieving these gains without additional training or computational costs compared to existing algorithms.
GS2Pose: Two-stage 6D Object Pose Estimation Guided by Gaussian Splatting
Nov 07, 2024

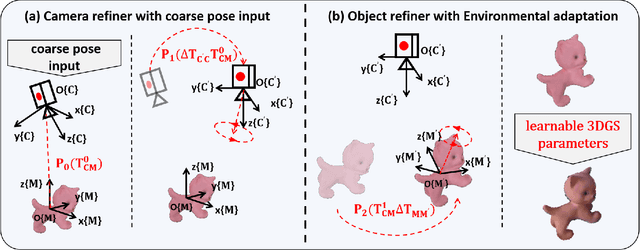

This paper proposes a new method for accurate and robust 6D pose estimation of novel objects, named GS2Pose. By introducing 3D Gaussian splatting, GS2Pose can utilize the reconstruction results without requiring a high-quality CAD model, which means it only requires segmented RGBD images as input. Specifically, GS2Pose employs a two-stage structure consisting of coarse estimation followed by refined estimation. In the coarse stage, a lightweight U-Net network with a polarization attention mechanism, called Pose-Net, is designed. By using the 3DGS model for supervised training, Pose-Net can generate NOCS images to compute a coarse pose. In the refinement stage, GS2Pose formulates a pose regression algorithm following the idea of reprojection or Bundle Adjustment (BA), referred to as GS-Refiner. By leveraging Lie algebra to extend 3DGS, GS-Refiner obtains a pose-differentiable rendering pipeline that refines the coarse pose by comparing the input images with the rendered images. GS-Refiner also selectively updates parameters in the 3DGS model to achieve environmental adaptation, thereby enhancing the algorithm's robustness and flexibility to illuminative variation, occlusion, and other challenging disruptive factors. GS2Pose was evaluated through experiments conducted on the LineMod dataset, where it was compared with similar algorithms, yielding highly competitive results. The code for GS2Pose will soon be released on GitHub.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024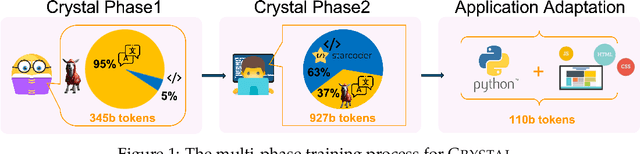
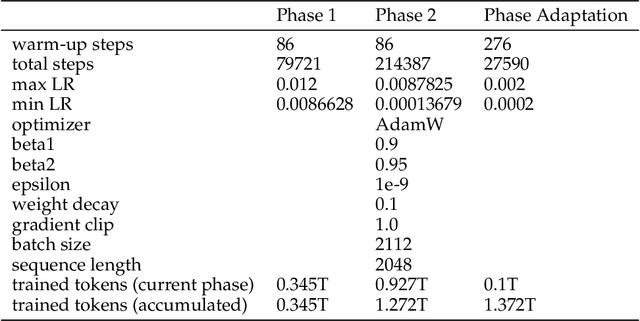
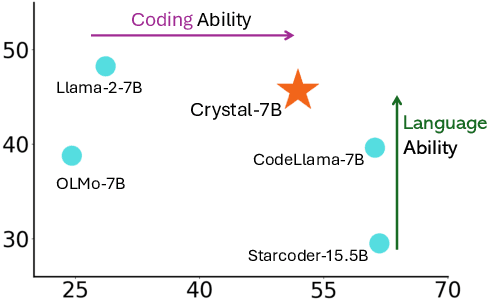
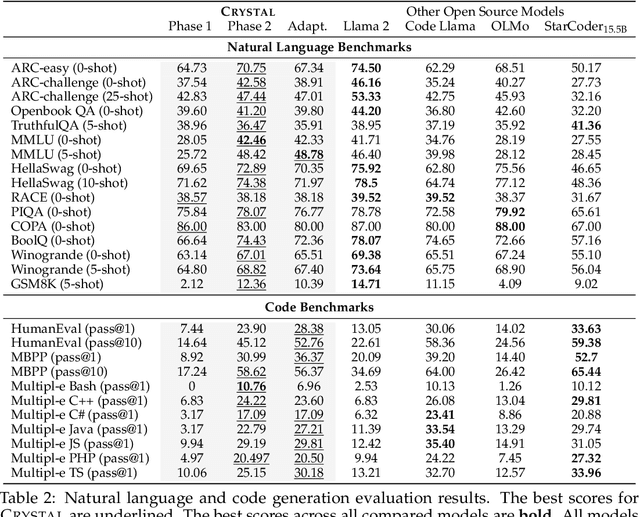
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Sep 30, 2024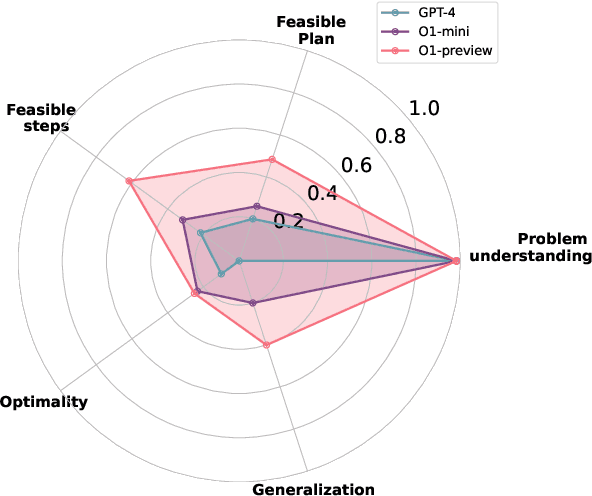
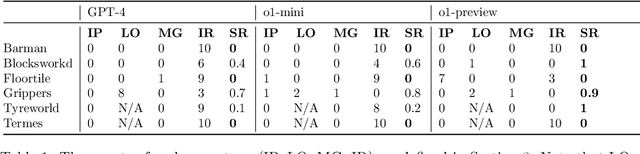
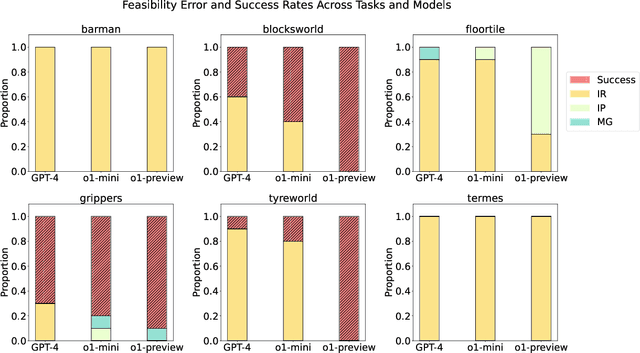
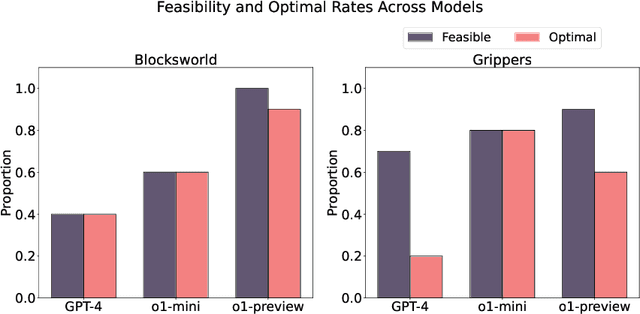
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $\textit{Barman}$, $\textit{Tyreworld}$) and spatially complex environments (e.g., $\textit{Termes}$, $\textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
MarsSeg: Mars Surface Semantic Segmentation with Multi-level Extractor and Connector
Apr 05, 2024



The segmentation and interpretation of the Martian surface play a pivotal role in Mars exploration, providing essential data for the trajectory planning and obstacle avoidance of rovers. However, the complex topography, similar surface features, and the lack of extensive annotated data pose significant challenges to the high-precision semantic segmentation of the Martian surface. To address these challenges, we propose a novel encoder-decoder based Mars segmentation network, termed MarsSeg. Specifically, we employ an encoder-decoder structure with a minimized number of down-sampling layers to preserve local details. To facilitate a high-level semantic understanding across the shadow multi-level feature maps, we introduce a feature enhancement connection layer situated between the encoder and decoder. This layer incorporates Mini Atrous Spatial Pyramid Pooling (Mini-ASPP), Polarized Self-Attention (PSA), and Strip Pyramid Pooling Module (SPPM). The Mini-ASPP and PSA are specifically designed for shadow feature enhancement, thereby enabling the expression of local details and small objects. Conversely, the SPPM is employed for deep feature enhancement, facilitating the extraction of high-level semantic category-related information. Experimental results derived from the Mars-Seg and AI4Mars datasets substantiate that the proposed MarsSeg outperforms other state-of-the-art methods in segmentation performance, validating the efficacy of each proposed component.