 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Spectral Principal Paths: How Deep Networks Distill Linear Representations from Noisy Inputs
Jun 10, 2025High-level representations have become a central focus in enhancing AI transparency and control, shifting attention from individual neurons or circuits to structured semantic directions that align with human-interpretable concepts. Motivated by the Linear Representation Hypothesis (LRH), we propose the Input-Space Linearity Hypothesis (ISLH), which posits that concept-aligned directions originate in the input space and are selectively amplified with increasing depth. We then introduce the Spectral Principal Path (SPP) framework, which formalizes how deep networks progressively distill linear representations along a small set of dominant spectral directions. Building on this framework, we further demonstrate the multimodal robustness of these representations in Vision-Language Models (VLMs). By bridging theoretical insights with empirical validation, this work advances a structured theory of representation formation in deep networks, paving the way for improving AI robustness, fairness, and transparency.
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025


While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025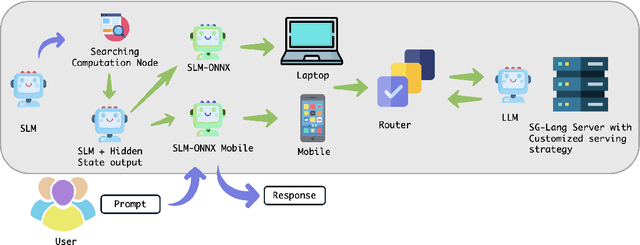
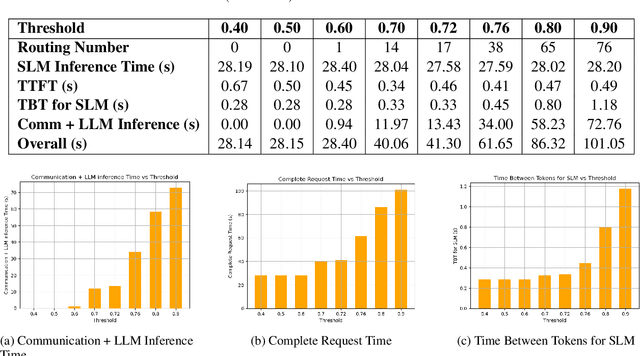
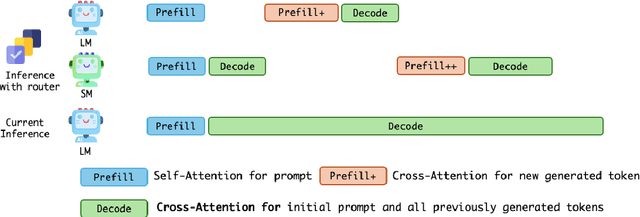
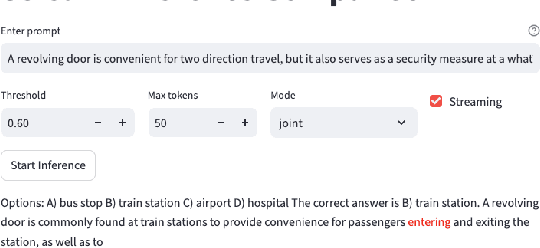
The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
Feb 04, 2025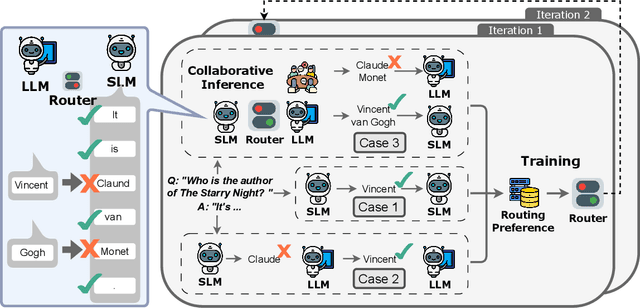
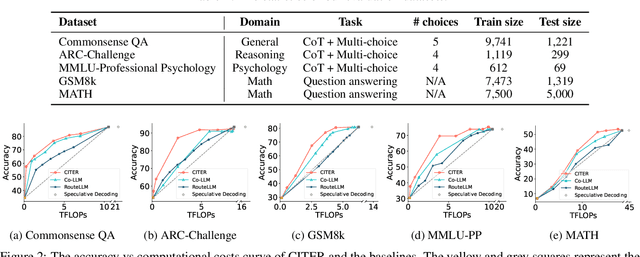
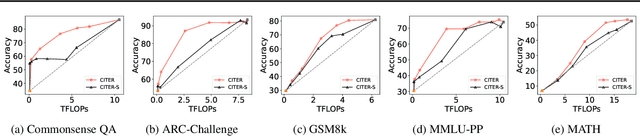
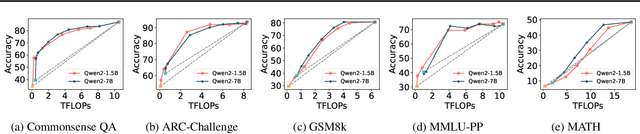
Large language models have achieved remarkable success in various tasks but suffer from high computational costs during inference, limiting their deployment in resource-constrained applications. To address this issue, we propose a novel CITER (\textbf{C}ollaborative \textbf{I}nference with \textbf{T}oken-l\textbf{E}vel \textbf{R}outing) framework that enables efficient collaboration between small and large language models (SLMs & LLMs) through a token-level routing strategy. Specifically, CITER routes non-critical tokens to an SLM for efficiency and routes critical tokens to an LLM for generalization quality. We formulate router training as a policy optimization, where the router receives rewards based on both the quality of predictions and the inference costs of generation. This allows the router to learn to predict token-level routing scores and make routing decisions based on both the current token and the future impact of its decisions. To further accelerate the reward evaluation process, we introduce a shortcut which significantly reduces the costs of the reward estimation and improving the practicality of our approach. Extensive experiments on five benchmark datasets demonstrate that CITER reduces the inference costs while preserving high-quality generation, offering a promising solution for real-time and resource-constrained applications.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024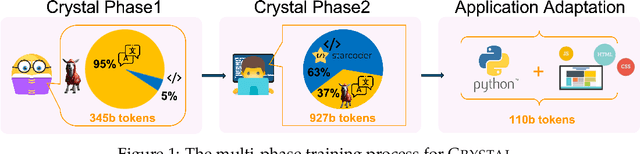
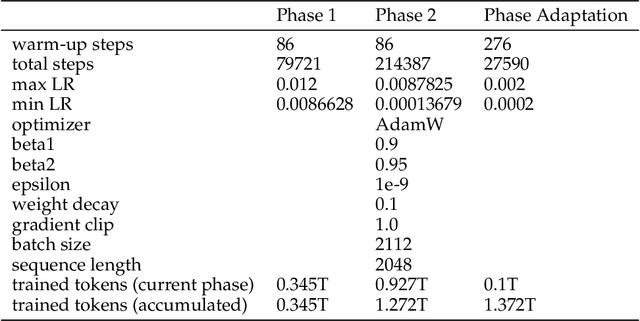
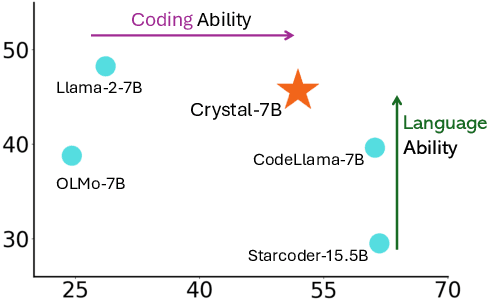
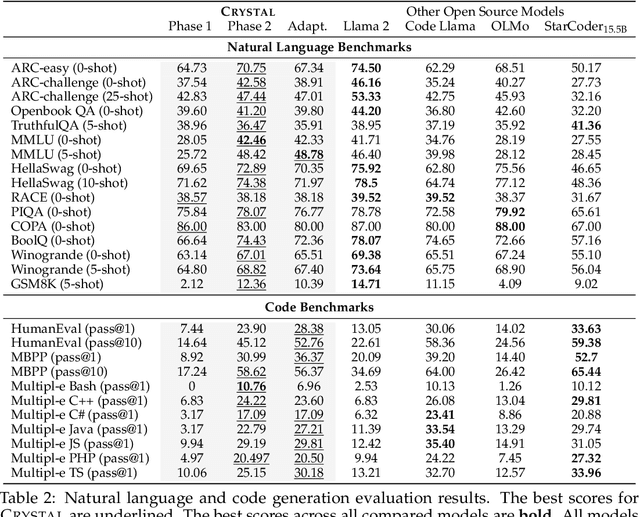
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
SemSim: Revisiting Weak-to-Strong Consistency from a Semantic Similarity Perspective for Semi-supervised Medical Image Segmentation
Oct 17, 2024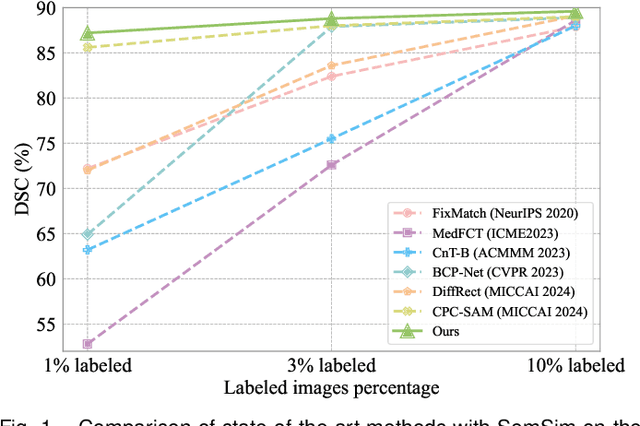
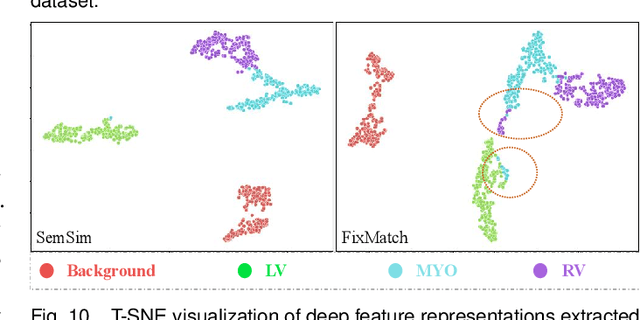

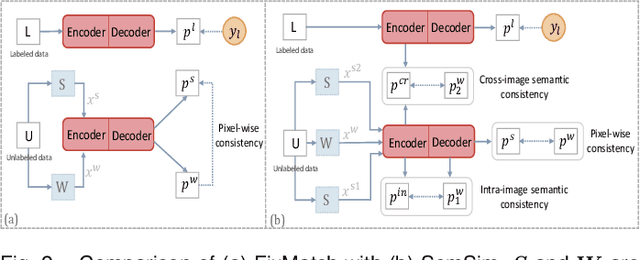
Semi-supervised learning (SSL) for medical image segmentation is a challenging yet highly practical task, which reduces reliance on large-scale labeled dataset by leveraging unlabeled samples. Among SSL techniques, the weak-to-strong consistency framework, popularized by FixMatch, has emerged as a state-of-the-art method in classification tasks. Notably, such a simple pipeline has also shown competitive performance in medical image segmentation. However, two key limitations still persist, impeding its efficient adaptation: (1) the neglect of contextual dependencies results in inconsistent predictions for similar semantic features, leading to incomplete object segmentation; (2) the lack of exploitation of semantic similarity between labeled and unlabeled data induces considerable class-distribution discrepancy. To address these limitations, we propose a novel semi-supervised framework based on FixMatch, named SemSim, powered by two appealing designs from semantic similarity perspective: (1) rectifying pixel-wise prediction by reasoning about the intra-image pair-wise affinity map, thus integrating contextual dependencies explicitly into the final prediction; (2) bridging labeled and unlabeled data via a feature querying mechanism for compact class representation learning, which fully considers cross-image anatomical similarities. As the reliable semantic similarity extraction depends on robust features, we further introduce an effective spatial-aware fusion module (SFM) to explore distinctive information from multiple scales. Extensive experiments show that SemSim yields consistent improvements over the state-of-the-art methods across three public segmentation benchmarks.
Model-GLUE: Democratized LLM Scaling for A Large Model Zoo in the Wild
Oct 07, 2024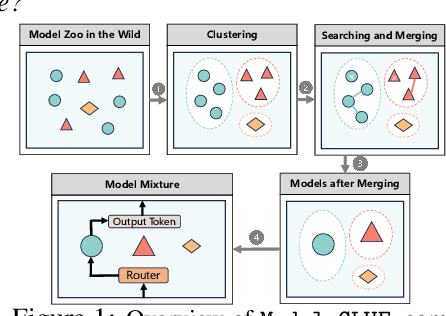

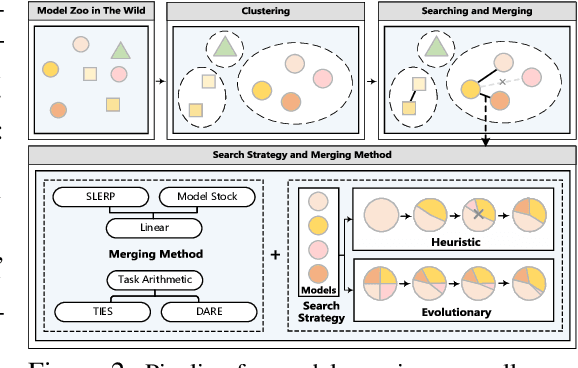
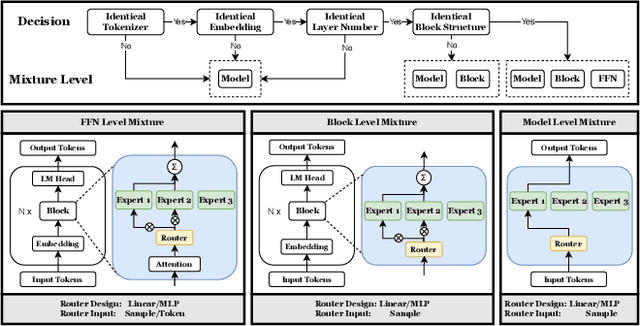
As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has garnered significant attention, which faces the challenge of decreasing performance when combining disparate models. Various techniques have been proposed for the aggregation of pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed. In light of this research gap, this paper introduces Model-GLUE, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate an strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization. Our methodology involves the clustering of mergeable models and optimal merging strategy selection, and the integration of clusters through a model mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, Model-GLUE shows an average performance enhancement of 5.61%, achieved without additional training. Codes are available at: https://github.com/Model-GLUE/Model-GLUE.
FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations
Sep 09, 2024



The rapid development of Large Language Models (LLMs) has been pivotal in advancing AI, with pre-trained LLMs being adaptable to diverse downstream tasks through fine-tuning. Federated learning (FL) further enhances fine-tuning in a privacy-aware manner by utilizing clients' local data through in-situ computation, eliminating the need for data movement. However, fine-tuning LLMs, given their massive scale of parameters, poses challenges for clients with constrained and heterogeneous resources in FL. Previous methods employed low-rank adaptation (LoRA) for efficient federated fine-tuning but utilized traditional FL aggregation strategies on LoRA adapters. These approaches led to mathematically inaccurate aggregation noise, reducing fine-tuning effectiveness and failing to address heterogeneous LoRAs. In this work, we first highlight the mathematical incorrectness of LoRA aggregation in existing federated fine-tuning methods. We introduce a new approach called FLORA that enables federated fine-tuning on heterogeneous LoRA adapters across clients through a novel stacking-based aggregation method. Our approach is noise-free and seamlessly supports heterogeneous LoRA adapters. Extensive experiments demonstrate FLORA' s superior performance in both homogeneous and heterogeneous settings, surpassing state-of-the-art methods. We envision this work as a milestone for efficient, privacy-preserving, and accurate federated fine-tuning of LLMs. Our code is available at https://github.com/ATP-1010/FederatedLLM.