 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPIC: Efficient Prompt Interaction for Text-Image Classification
Jul 10, 2025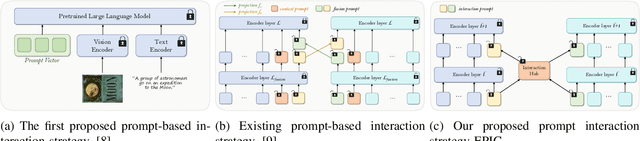
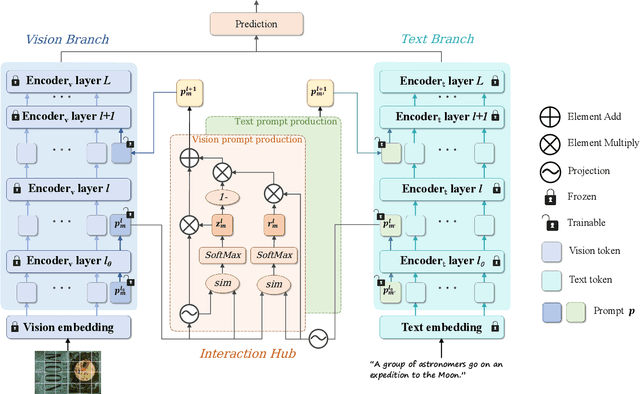
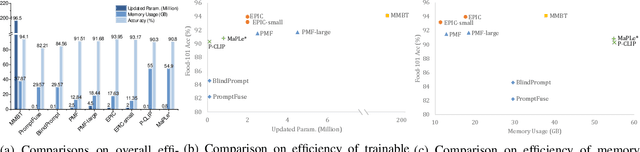

In recent years, large-scale pre-trained multimodal models (LMMs) generally emerge to integrate the vision and language modalities, achieving considerable success in multimodal tasks, such as text-image classification. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this context, we propose a novel efficient prompt-based multimodal interaction strategy, namely Efficient Prompt Interaction for text-image Classification (EPIC). Specifically, we utilize temporal prompts on intermediate layers, and integrate different modalities with similarity-based prompt interaction, to leverage sufficient information exchange between modalities. Utilizing this approach, our method achieves reduced computational resource consumption and fewer trainable parameters (about 1\% of the foundation model) compared to other fine-tuning strategies. Furthermore, it demonstrates superior performance on the UPMC-Food101 and SNLI-VE datasets, while achieving comparable performance on the MM-IMDB dataset.
HSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Jul 23, 2024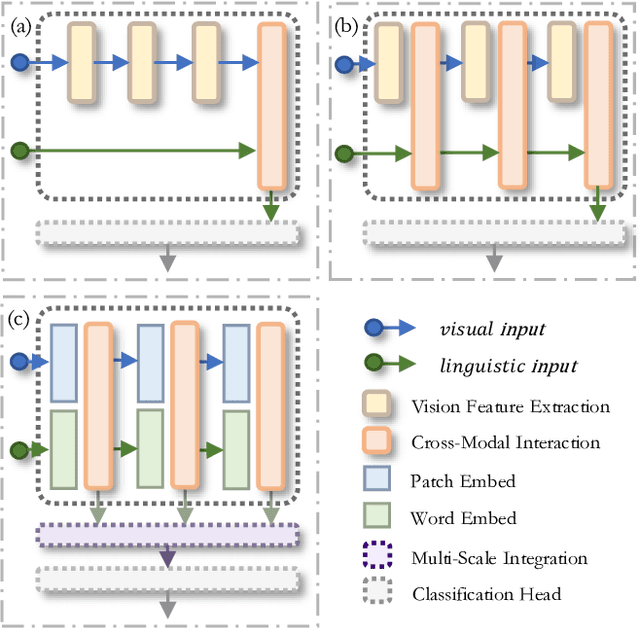
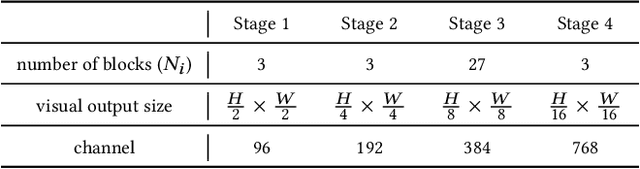
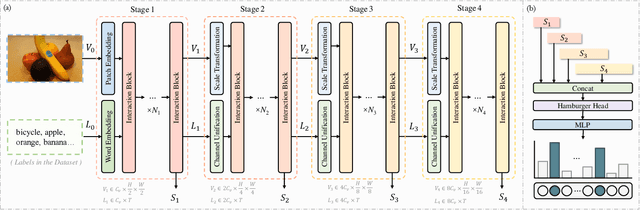
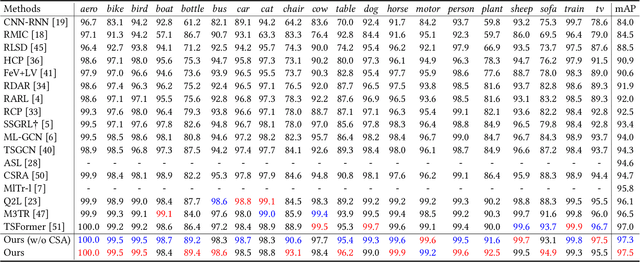
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.
* 10 pages, 6 figures
Memory-Inspired Temporal Prompt Interaction for Text-Image Classification
Jan 26, 2024In recent years, large-scale pre-trained multimodal models (LMM) generally emerge to integrate the vision and language modalities, achieving considerable success in various natural language processing and computer vision tasks. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this contex, we propose a novel prompt-based multimodal interaction strategy inspired by human memory strategy, namely Memory-Inspired Temporal Prompt Interaction (MITP). Our proposed method involves in two stages as in human memory strategy: the acquiring stage, and the consolidation and activation stage. We utilize temporal prompts on intermediate layers to imitate the acquiring stage, leverage similarity-based prompt interaction to imitate memory consolidation, and employ prompt generation strategy to imitate memory activation. The main strength of our paper is that we interact the prompt vectors on intermediate layers to leverage sufficient information exchange between modalities, with compressed trainable parameters and memory usage. We achieve competitive results on several datasets with relatively small memory usage and 2.0M of trainable parameters (about 1% of the pre-trained foundation model).