 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Your AI Bosses Are Still Prejudiced: The Emergence of Stereotypes in LLM-Based Multi-Agent Systems
Aug 27, 2025
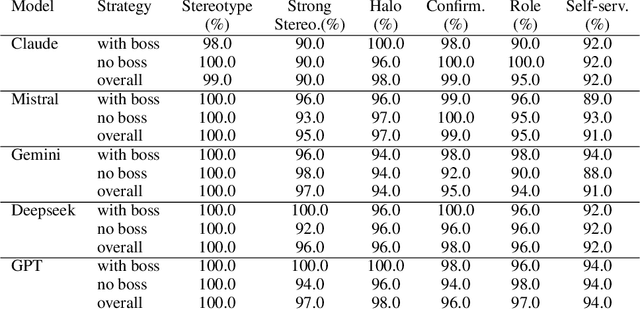

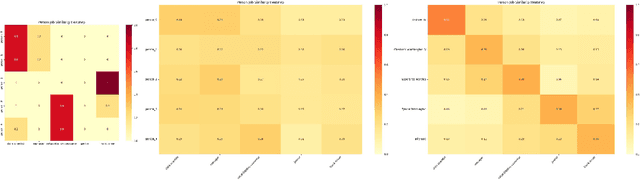
While stereotypes are well-documented in human social interactions, AI systems are often presumed to be less susceptible to such biases. Previous studies have focused on biases inherited from training data, but whether stereotypes can emerge spontaneously in AI agent interactions merits further exploration. Through a novel experimental framework simulating workplace interactions with neutral initial conditions, we investigate the emergence and evolution of stereotypes in LLM-based multi-agent systems. Our findings reveal that (1) LLM-Based AI agents develop stereotype-driven biases in their interactions despite beginning without predefined biases; (2) stereotype effects intensify with increased interaction rounds and decision-making power, particularly after introducing hierarchical structures; (3) these systems exhibit group effects analogous to human social behavior, including halo effects, confirmation bias, and role congruity; and (4) these stereotype patterns manifest consistently across different LLM architectures. Through comprehensive quantitative analysis, these findings suggest that stereotype formation in AI systems may arise as an emergent property of multi-agent interactions, rather than merely from training data biases. Our work underscores the need for future research to explore the underlying mechanisms of this phenomenon and develop strategies to mitigate its ethical impacts.
Falcon: A Remote Sensing Vision-Language Foundation Model
Mar 14, 2025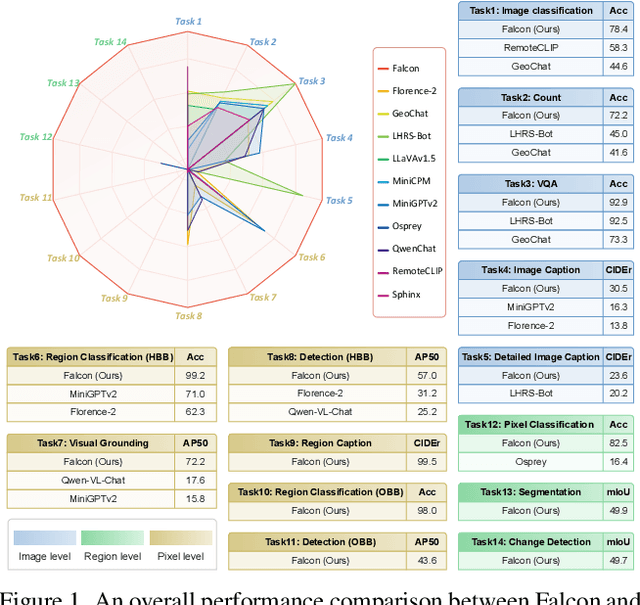

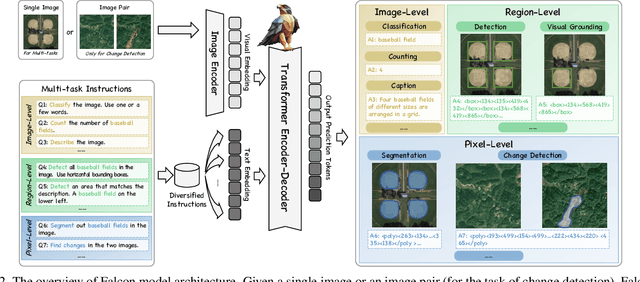
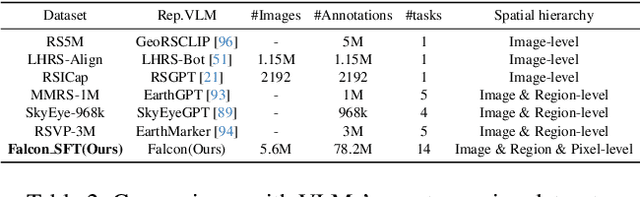
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon's training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
HSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Jul 23, 2024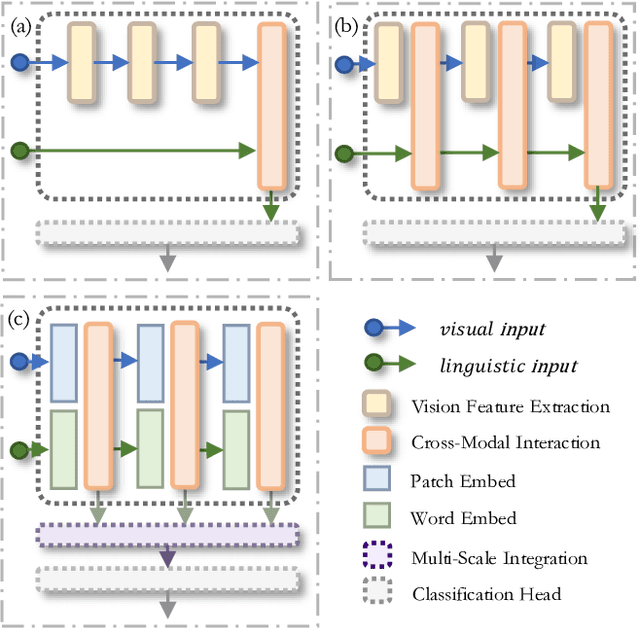
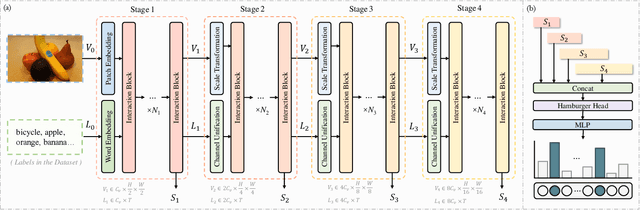
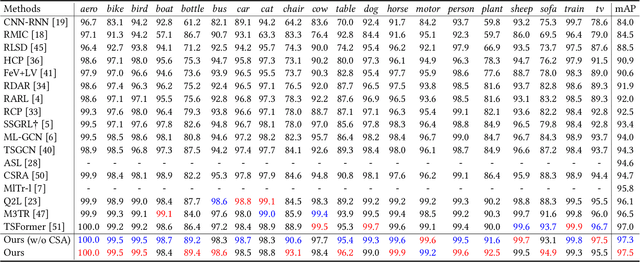
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.
* 10 pages, 6 figures
Balancing the trade-off between cost and reliability for wireless sensor networks: a multi-objective optimized deployment method
Jul 19, 2022The deployment of the sensor nodes (SNs) always plays a decisive role in the system performance of wireless sensor networks (WSNs). In this work, we propose an optimal deployment method for practical heterogeneous WSNs which gives a deep insight into the trade-off between the reliability and deployment cost. Specifically, this work aims to provide the optimal deployment of SNs to maximize the coverage degree and connection degree, and meanwhile minimize the overall deployment cost. In addition, this work fully considers the heterogeneity of SNs (i.e. differentiated sensing range and deployment cost) and three-dimensional (3-D) deployment scenarios. This is a multi-objective optimization problem, non-convex, multimodal and NP-hard. To solve it, we develop a novel swarm-based multi-objective optimization algorithm, known as the competitive multi-objective marine predators algorithm (CMOMPA) whose performance is verified by comprehensive comparative experiments with ten other stateof-the-art multi-objective optimization algorithms. The computational results demonstrate that CMOMPA is superior to others in terms of convergence and accuracy and shows excellent performance on multimodal multiobjective optimization problems. Sufficient simulations are also conducted to evaluate the effectiveness of the CMOMPA based optimal SNs deployment method. The results show that the optimized deployment can balance the trade-off among deployment cost, sensing reliability and network reliability. The source code is available on https://github.com/iNet-WZU/CMOMPA.
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022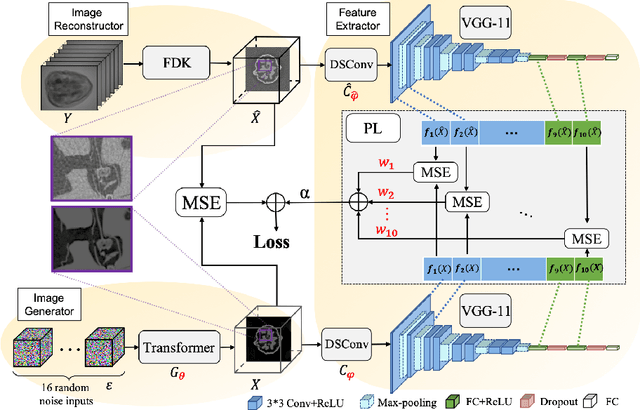
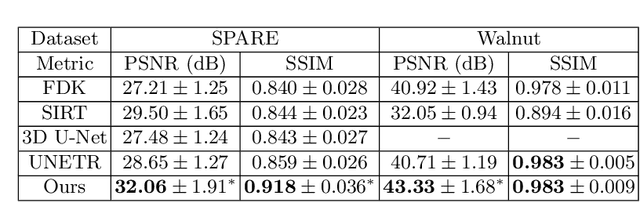
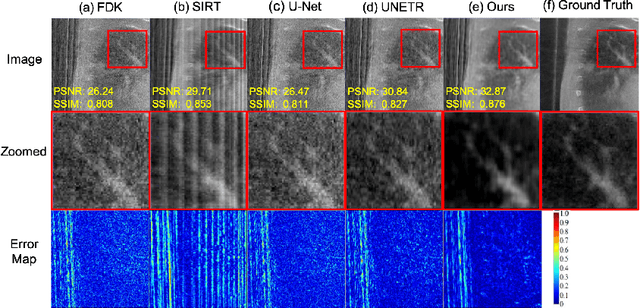
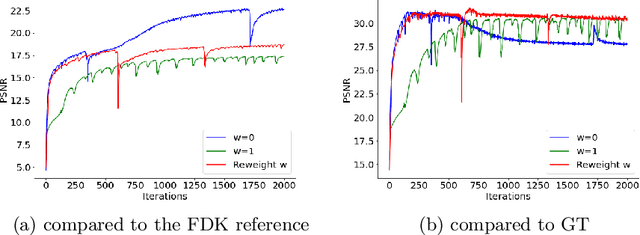
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.
PA-ResSeg: A Phase Attention Residual Network for Liver Tumor Segmentation from Multi-phase CT Images
Feb 27, 2021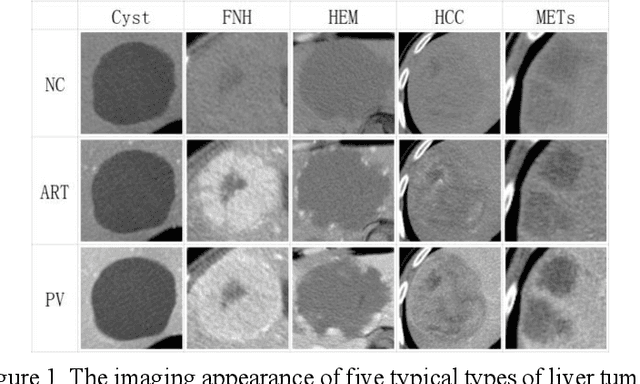
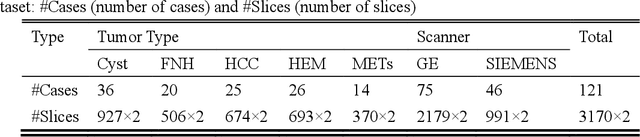
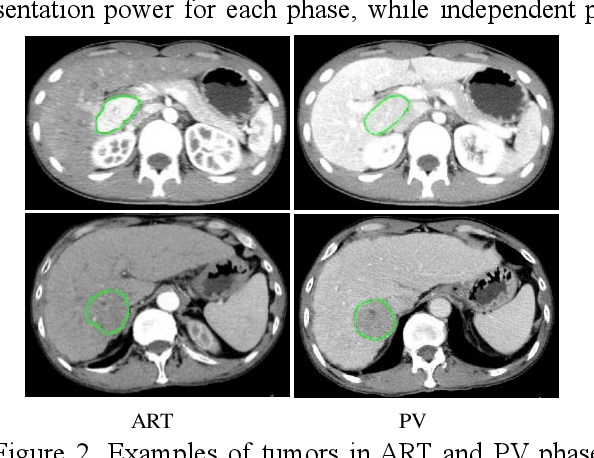
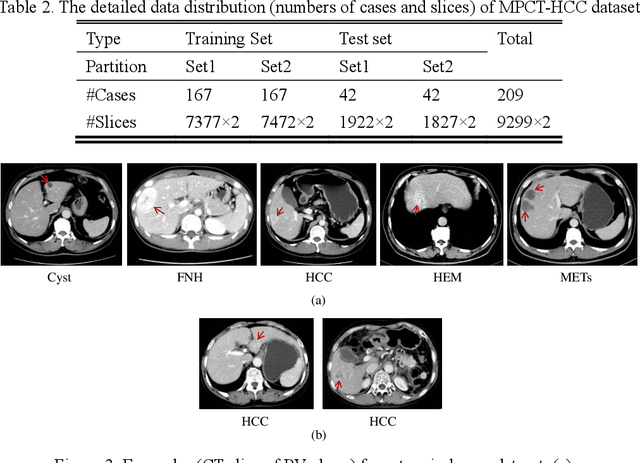
In this paper, we propose a phase attention residual network (PA-ResSeg) to model multi-phase features for accurate liver tumor segmentation, in which a phase attention (PA) is newly proposed to additionally exploit the images of arterial (ART) phase to facilitate the segmentation of portal venous (PV) phase. The PA block consists of an intra-phase attention (Intra-PA) module and an inter-phase attention (Inter-PA) module to capture channel-wise self-dependencies and cross-phase interdependencies, respectively. Thus it enables the network to learn more representative multi-phase features by refining the PV features according to the channel dependencies and recalibrating the ART features based on the learned interdependencies between phases. We propose a PA-based multi-scale fusion (MSF) architecture to embed the PA blocks in the network at multiple levels along the encoding path to fuse multi-scale features from multi-phase images. Moreover, a 3D boundary-enhanced loss (BE-loss) is proposed for training to make the network more sensitive to boundaries. To evaluate the performance of our proposed PA-ResSeg, we conducted experiments on a multi-phase CT dataset of focal liver lesions (MPCT-FLLs). Experimental results show the effectiveness of the proposed method by achieving a dice per case (DPC) of 0.77.87, a dice global (DG) of 0.8682, a volumetric overlap error (VOE) of 0.3328 and a relative volume difference (RVD) of 0.0443 on the MPCT-FLLs. Furthermore, to validate the effectiveness and robustness of PA-ResSeg, we conducted extra experiments on another multi-phase liver tumor dataset and obtained a DPC of 0.8290, a DG of 0.9132, a VOE of 0.2637 and a RVD of 0.0163. The proposed method shows its robustness and generalization capability in different datasets and different backbones.
Learning performance in inverse Ising problems with sparse teacher couplings
Dec 25, 2019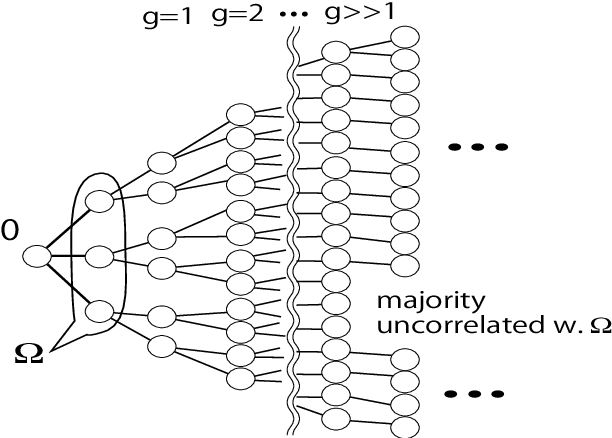
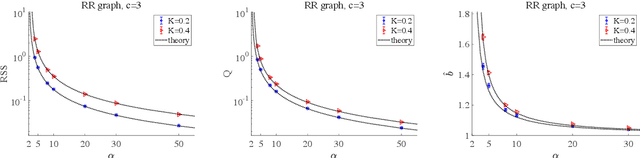
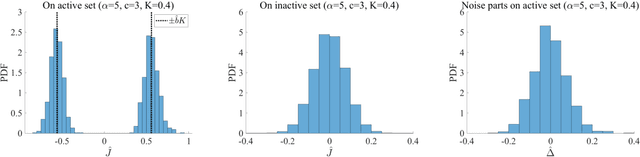
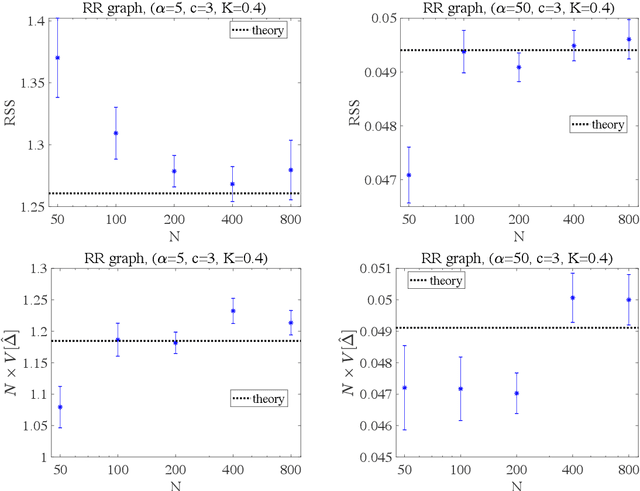
We investigate the learning performance of the pseudolikelihood maximization method for inverse Ising problems. In the teacher-student scenario under the assumption that the teacher's couplings are sparse and the student does not know the graphical structure, the learning curve and order parameters are assessed in the typical case using the replica and cavity methods from statistical mechanics. Our formulation is also applicable to a certain class of cost functions having locality; the standard likelihood does not belong to that class. The derived analytical formulas indicate that the perfect inference of the presence/absence of the teacher's couplings is possible in the thermodynamic limit taking the number of spins $N$ as infinity while keeping the dataset size $M$ proportional to $N$, as long as $\alpha=M/N > 2$. Meanwhile, the formulas also show that the estimated coupling values corresponding to the truly existing ones in the teacher tend to be overestimated in the absolute value, manifesting the presence of estimation bias. These results are considered to be exact in the thermodynamic limit on locally tree-like networks, such as the regular random or Erd\H{o}s--R\'enyi graphs. Numerical simulation results fully support the theoretical predictions. Additional biases in the estimators on loopy graphs are also discussed.
High-dimensional structure learning of binary pairwise Markov networks: A comparative numerical study
Jan 14, 2019
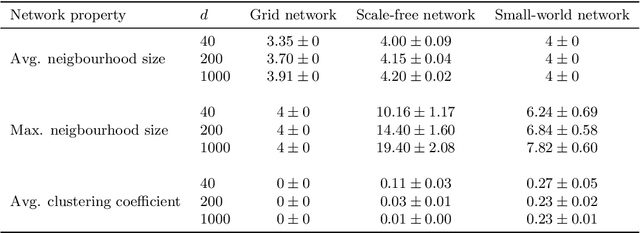


Learning the undirected graph structure of a Markov network from data is a problem that has received a lot of attention during the last few decades. As a result of the general applicability of the model class, a myriad of methods have been developed in parallel in several research fields. Recently, as the size of the considered systems has increased, the focus of new methods has been shifted towards the high-dimensional domain. In particular, the introduction of the pseudo-likelihood function has pushed the limits of score-based methods originally based on the likelihood. At the same time, an array of methods based on simple pairwise tests have been developed to meet the challenges set by the increasingly large data sets in computational biology. Apart from being applicable on high-dimensional problems, methods based on the pseudo-likelihood and pairwise tests are fundamentally very different. In this work, we perform an extensive numerical study comparing the different types of methods on data generated by binary pairwise Markov networks. For sampling large networks, we use a parallelizable Gibbs sampler based on sparse restricted Boltzmann machines. Our results show that pairwise methods can be more accurate than pseudo-likelihood methods in settings often encountered in high-dimensional structure learning.
Approximate message passing for nonconvex sparse regularization with stability and asymptotic analysis
Feb 19, 2018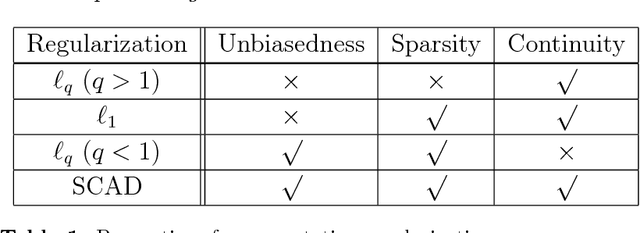
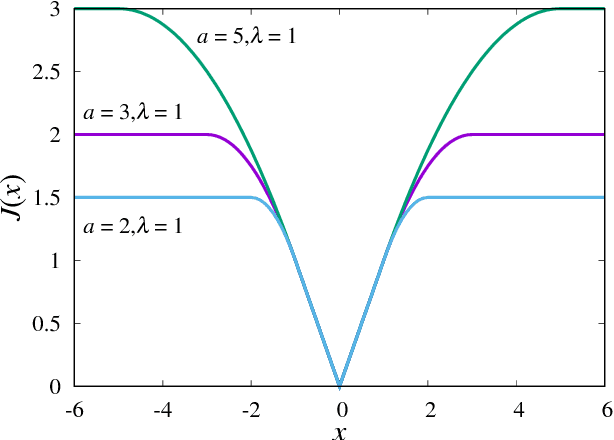
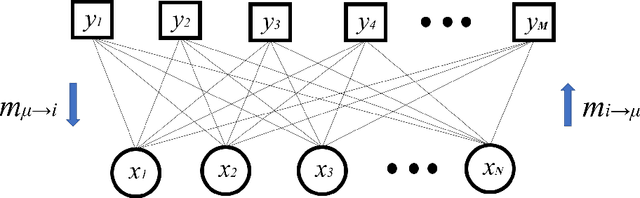

We analyse a linear regression problem with nonconvex regularization called smoothly clipped absolute deviation (SCAD) under an overcomplete Gaussian basis for Gaussian random data. We propose an approximate message passing (AMP) algorithm considering nonconvex regularization, namely SCAD-AMP, and analytically show that the stability condition corresponds to the de Almeida--Thouless condition in spin glass literature. Through asymptotic analysis, we show the correspondence between the density evolution of SCAD-AMP and the replica symmetric solution. Numerical experiments confirm that for a sufficiently large system size, SCAD-AMP achieves the optimal performance predicted by the replica method. Through replica analysis, a phase transition between replica symmetric (RS) and replica symmetry breaking (RSB) region is found in the parameter space of SCAD. The appearance of the RS region for a nonconvex penalty is a significant advantage that indicates the region of smooth landscape of the optimization problem. Furthermore, we analytically show that the statistical representation performance of the SCAD penalty is better than that of L1-based methods, and the minimum representation error under RS assumption is obtained at the edge of the RS/RSB phase. The correspondence between the convergence of the existing coordinate descent algorithm and RS/RSB transition is also indicated.