 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-field magnetic resonance image enhancement via stochastic image quality transfer
Apr 26, 2023



Low-field (<1T) magnetic resonance imaging (MRI) scanners remain in widespread use in low- and middle-income countries (LMICs) and are commonly used for some applications in higher income countries e.g. for small child patients with obesity, claustrophobia, implants, or tattoos. However, low-field MR images commonly have lower resolution and poorer contrast than images from high field (1.5T, 3T, and above). Here, we present Image Quality Transfer (IQT) to enhance low-field structural MRI by estimating from a low-field image the image we would have obtained from the same subject at high field. Our approach uses (i) a stochastic low-field image simulator as the forward model to capture uncertainty and variation in the contrast of low-field images corresponding to a particular high-field image, and (ii) an anisotropic U-Net variant specifically designed for the IQT inverse problem. We evaluate the proposed algorithm both in simulation and using multi-contrast (T1-weighted, T2-weighted, and fluid attenuated inversion recovery (FLAIR)) clinical low-field MRI data from an LMIC hospital. We show the efficacy of IQT in improving contrast and resolution of low-field MR images. We demonstrate that IQT-enhanced images have potential for enhancing visualisation of anatomical structures and pathological lesions of clinical relevance from the perspective of radiologists. IQT is proved to have capability of boosting the diagnostic value of low-field MRI, especially in low-resource settings.
An Experiment Design Paradigm using Joint Feature Selection and Task Optimization
Oct 13, 2022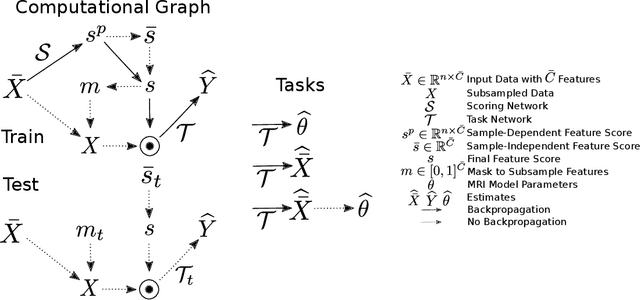
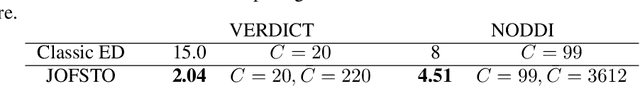

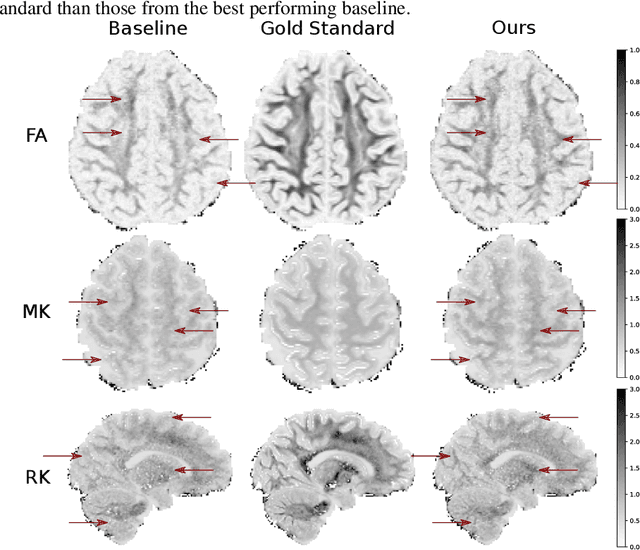
This paper presents a subsampling-task paradigm for data-driven task-specific experiment design (ED) and a novel method in populationwide supervised feature selection (FS). Optimal ED, the choice of sampling points under constraints of limited acquisition-time, arises in a wide variety of scientific and engineering contexts. However the continuous optimization used in classical approaches depend on a-priori parameter choices and challenging non-convex optimization landscapes. This paper proposes to replace this strategy with a subsampling-task paradigm, analogous to populationwide supervised FS. In particular, we introduce JOFSTO, which performs JOint Feature Selection and Task Optimization. JOFSTO jointly optimizes two coupled networks: one for feature scoring, which provides the ED, the other for execution of a downstream task or process. Unlike most FS problems, e.g. selecting protein expressions for classification, ED problems typically select from highly correlated globally informative candidates rather than seeking a small number of highly informative features among many uninformative features. JOFSTO's construction efficiently identifies potentially correlated, but effective subsets and returns a trained task network. We demonstrate the approach using parameter estimation and mapping problems in quantitative MRI, where economical ED is crucial for clinical application. Results from simulations and empirical data show the subsampling-task paradigm strongly outperforms classical ED, and within our paradigm, JOFSTO outperforms state-of-the-art supervised FS techniques. JOFSTO extends immediately to wider image-based ED problems and other scenarios where the design must be specified globally across large numbers of acquisitions. Code will be released.
Progressive Subsampling for Oversampled Data -- Application to Quantitative MRI
Apr 08, 2022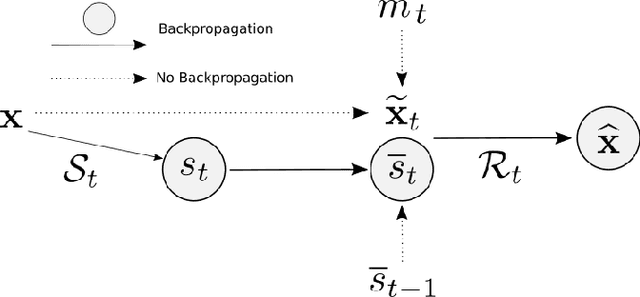
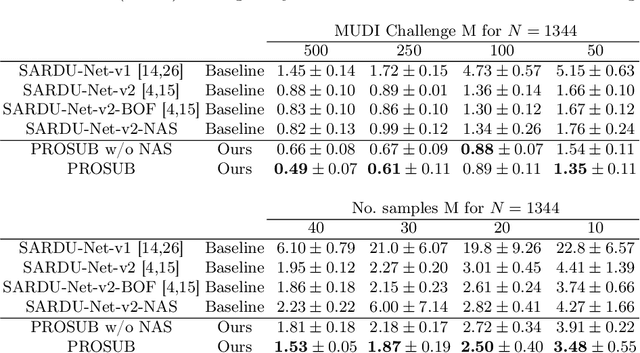
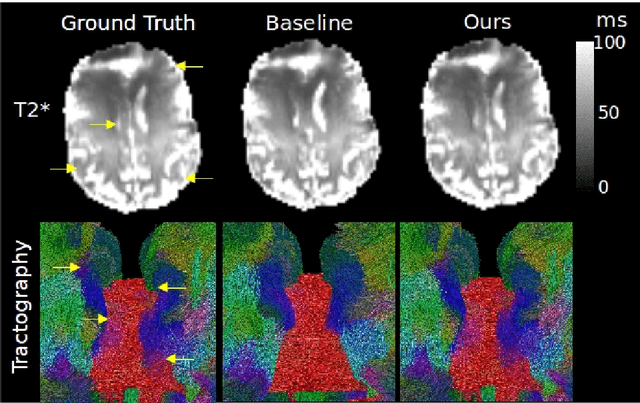
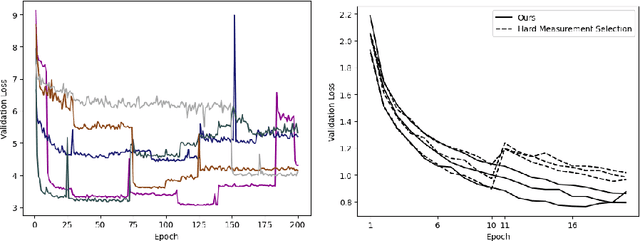
We present PROSUB: PROgressive SUBsampling, a deep learning based, automated methodology that subsamples an oversampled data set (e.g. multi-channeled 3D images) with minimal loss of information. We build upon a recent dual-network approach that won the MICCAI MUlti-DIffusion (MUDI) quantitative MRI measurement sampling-reconstruction challenge, but suffers from deep learning training instability, by subsampling with a hard decision boundary. PROSUB uses the paradigm of recursive feature elimination (RFE) and progressively subsamples measurements during deep learning training, improving optimization stability. PROSUB also integrates a neural architecture search (NAS) paradigm, allowing the network architecture hyperparameters to respond to the subsampling process. We show PROSUB outperforms the winner of the MUDI MICCAI challenge, producing large improvements >18% MSE on the MUDI challenge sub-tasks and qualitative improvements on downstream processes useful for clinical applications. We also show the benefits of incorporating NAS and analyze the effect of PROSUB's components. As our method generalizes to other problems beyond MRI measurement selection-reconstruction, our code is https://github.com/sbb-gh/PROSUB
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022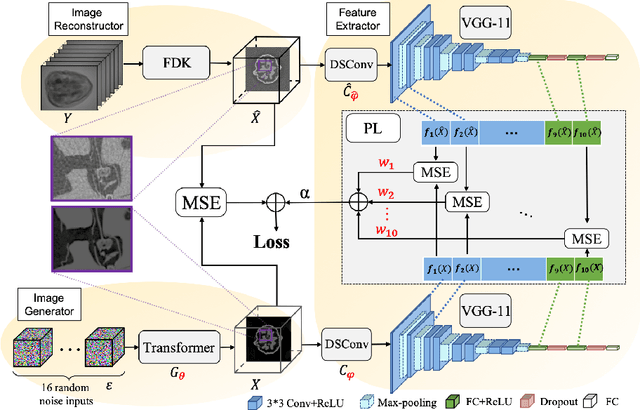
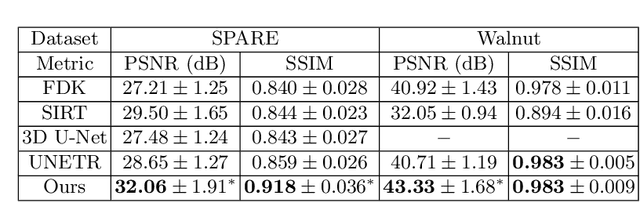
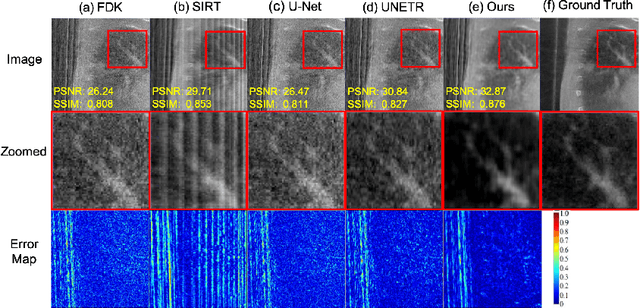
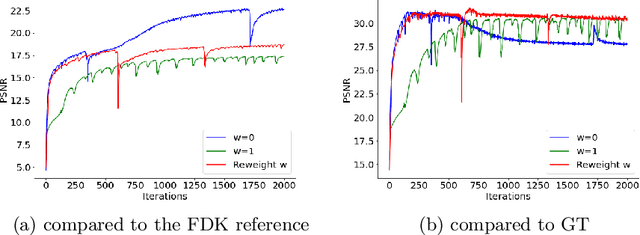
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.
Continual Contrastive Self-supervised Learning for Image Classification
Jul 06, 2021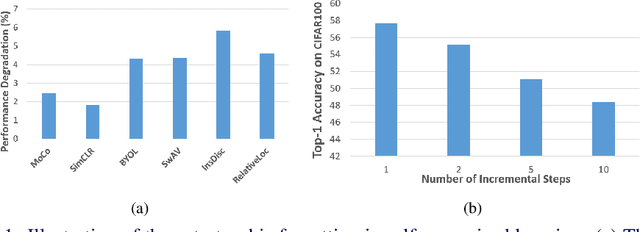



For artificial learning systems, continual learning over time from a stream of data is essential. The burgeoning studies on supervised continual learning have achieved great progress, while the study of catastrophic forgetting in unsupervised learning is still blank. Among unsupervised learning methods, self-supervise learning method shows tremendous potential on visual representation without any labeled data at scale. To improve the visual representation of self-supervised learning, larger and more varied data is needed. In the real world, unlabeled data is generated at all times. This circumstance provides a huge advantage for the learning of the self-supervised method. However, in the current paradigm, packing previous data and current data together and training it again is a waste of time and resources. Thus, a continual self-supervised learning method is badly needed. In this paper, we make the first attempt to implement the continual contrastive self-supervised learning by proposing a rehearsal method, which keeps a few exemplars from the previous data. Instead of directly combining saved exemplars with the current data set for training, we leverage self-supervised knowledge distillation to transfer contrastive information among previous data to the current network by mimicking similarity score distribution inferred by the old network over a set of saved exemplars. Moreover, we build an extra sample queue to assist the network to distinguish between previous and current data and prevent mutual interference while learning their own feature representation. Experimental results show that our method performs well on CIFAR100 and ImageNet-Sub. Compared with the baselines, which learning tasks without taking any technique, we improve the image classification top-1 accuracy by 1.60% on CIFAR100, 2.86% on ImageNet-Sub and 1.29% on ImageNet-Full under 10 incremental steps setting.
Learning to Address Intra-segment Misclassification in Retinal Imaging
Apr 25, 2021
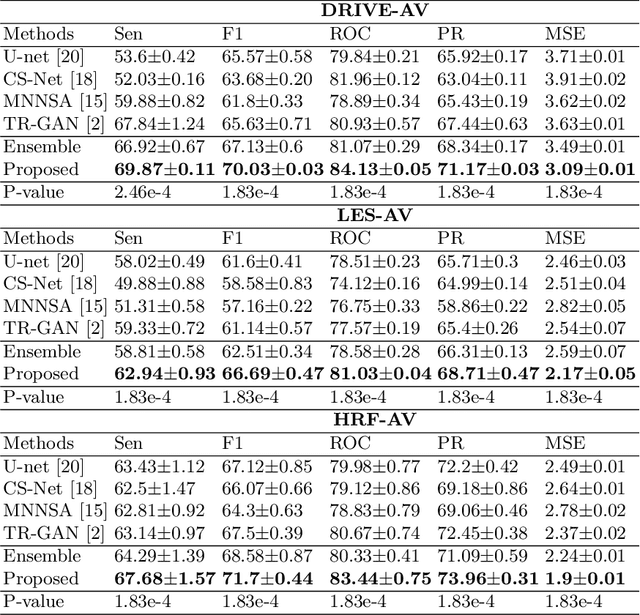


Accurate multi-class segmentation is a long-standing challenge in medical imaging, especially in scenarios where classes share strong similarity. Segmenting retinal blood vessels in retinal photographs is one such scenario, in which arteries and veins need to be identified and differentiated from each other and from the background. Intra-segment misclassification, i.e. veins classified as arteries or vice versa, frequently occurs when arteries and veins intersect, whereas in binary retinal vessel segmentation, error rates are much lower. We thus propose a new approach that decomposes multi-class segmentation into multiple binary, followed by a binary-to-multi-class fusion network. The network merges representations of artery, vein, and multi-class feature maps, each of which are supervised by expert vessel annotation in adversarial training. A skip-connection based merging process explicitly maintains class-specific gradients to avoid gradient vanishing in deep layers, to favor the discriminative features. The results show that, our model respectively improves F1-score by 4.4\%, 5.1\%, and 4.2\% compared with three state-of-the-art deep learning based methods on DRIVE-AV, LES-AV, and HRF-AV data sets.
Image Quality Transfer Enhances Contrast and Resolution of Low-Field Brain MRI in African Paediatric Epilepsy Patients
Mar 18, 2020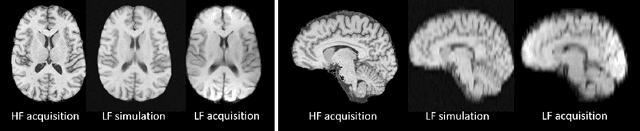
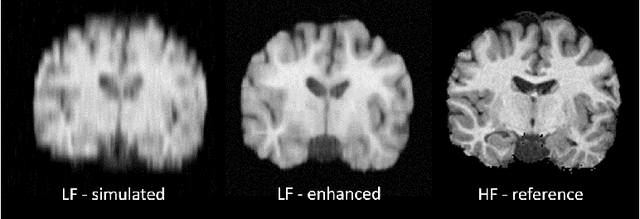
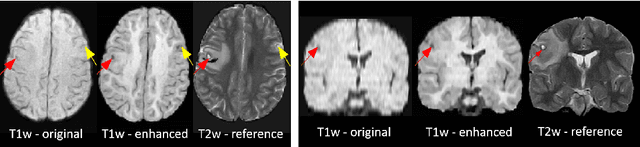
1.5T or 3T scanners are the current standard for clinical MRI, but low-field (<1T) scanners are still common in many lower- and middle-income countries for reasons of cost and robustness to power failures. Compared to modern high-field scanners, low-field scanners provide images with lower signal-to-noise ratio at equivalent resolution, leaving practitioners to compensate by using large slice thickness and incomplete spatial coverage. Furthermore, the contrast between different types of brain tissue may be substantially reduced even at equal signal-to-noise ratio, which limits diagnostic value. Recently the paradigm of Image Quality Transfer has been applied to enhance 0.36T structural images aiming to approximate the resolution, spatial coverage, and contrast of typical 1.5T or 3T images. A variant of the neural network U-Net was trained using low-field images simulated from the publicly available 3T Human Connectome Project dataset. Here we present qualitative results from real and simulated clinical low-field brain images showing the potential value of IQT to enhance the clinical utility of readily accessible low-field MRIs in the management of epilepsy.
Deep Learning for Low-Field to High-Field MR: Image Quality Transfer with Probabilistic Decimation Simulator
Sep 15, 2019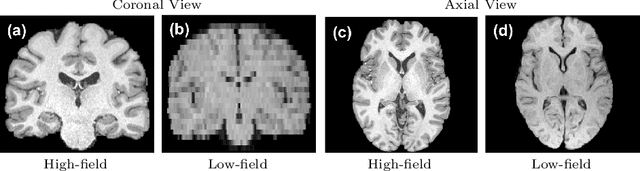
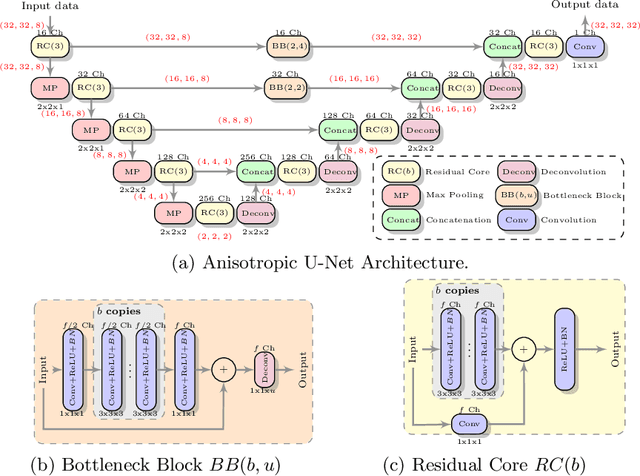
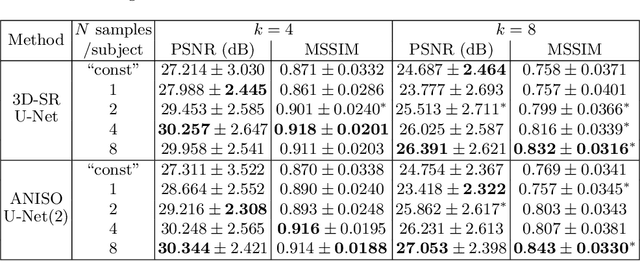
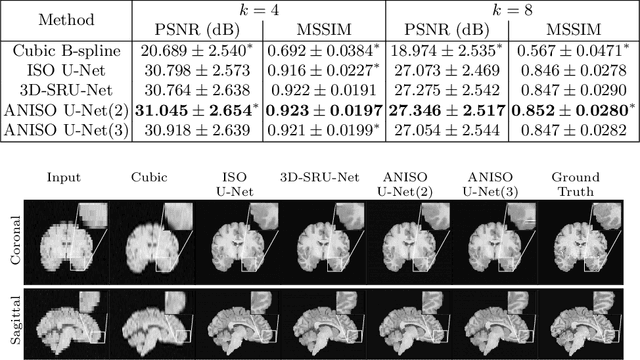
MR images scanned at low magnetic field ($<1$T) have lower resolution in the slice direction and lower contrast, due to a relatively small signal-to-noise ratio (SNR) than those from high field (typically 1.5T and 3T). We adapt the recent idea of Image Quality Transfer (IQT) to enhance very low-field structural images aiming to estimate the resolution, spatial coverage, and contrast of high-field images. Analogous to many learning-based image enhancement techniques, IQT generates training data from high-field scans alone by simulating low-field images through a pre-defined decimation model. However, the ground truth decimation model is not well-known in practice, and lack of its specification can bias the trained model, aggravating performance on the real low-field scans. In this paper we propose a probabilistic decimation simulator to improve robustness of model training. It is used to generate and augment various low-field images whose parameters are random variables and sampled from an empirical distribution related to tissue-specific SNR on a 0.36T scanner. The probabilistic decimation simulator is model-agnostic, that is, it can be used with any super-resolution networks. Furthermore we propose a variant of U-Net architecture to improve its learning performance. We show promising qualitative results from clinical low-field images confirming the strong efficacy of IQT in an important new application area: epilepsy diagnosis in sub-Saharan Africa where only low-field scanners are normally available.