 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Self-supervised Learning to Network Intrusion Detection for Network Flows with Graph Neural Network
Mar 03, 2024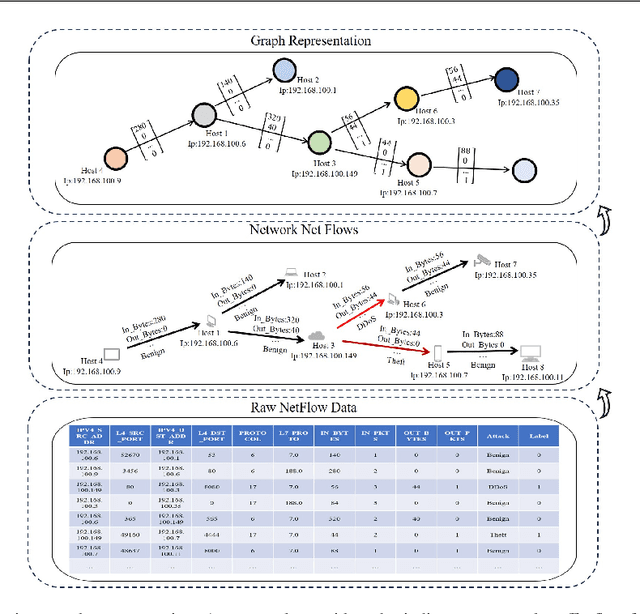
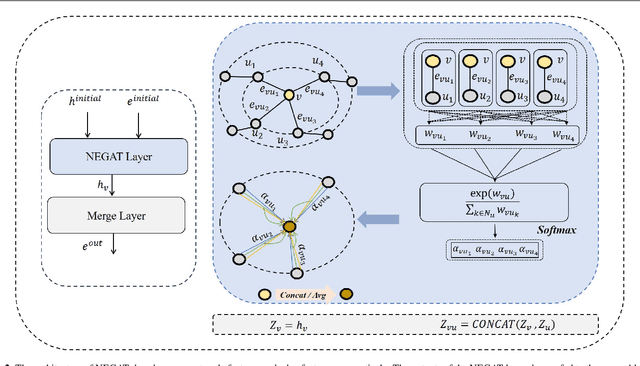
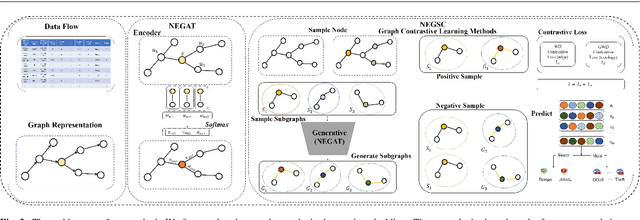
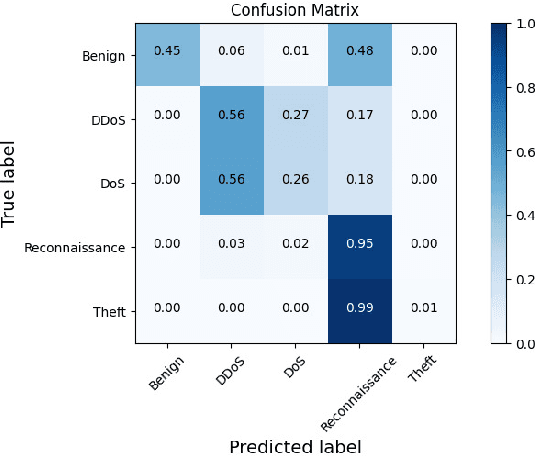
Graph Neural Networks (GNNs) have garnered intensive attention for Network Intrusion Detection System (NIDS) due to their suitability for representing the network traffic flows. However, most present GNN-based methods for NIDS are supervised or semi-supervised. Network flows need to be manually annotated as supervisory labels, a process that is time-consuming or even impossible, making NIDS difficult to adapt to potentially complex attacks, especially in large-scale real-world scenarios. The existing GNN-based self-supervised methods focus on the binary classification of network flow as benign or not, and thus fail to reveal the types of attack in practice. This paper studies the application of GNNs to identify the specific types of network flows in an unsupervised manner. We first design an encoder to obtain graph embedding, that introduces the graph attention mechanism and considers the edge information as the only essential factor. Then, a self-supervised method based on graph contrastive learning is proposed. The method samples center nodes, and for each center node, generates subgraph by it and its direct neighbor nodes, and corresponding contrastive subgraph from the interpolated graph, and finally constructs positive and negative samples from subgraphs. Furthermore, a structured contrastive loss function based on edge features and graph local topology is introduced. To the best of our knowledge, it is the first GNN-based self-supervised method for the multiclass classification of network flows in NIDS. Detailed experiments conducted on four real-world databases (NF-Bot-IoT, NF-Bot-IoT-v2, NF-CSE-CIC-IDS2018, and NF-CSE-CIC-IDS2018-v2) systematically compare our model with the state-of-the-art supervised and self-supervised models, illustrating the considerable potential of our method. Our code is accessible through https://github.com/renj-xu/NEGSC.
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022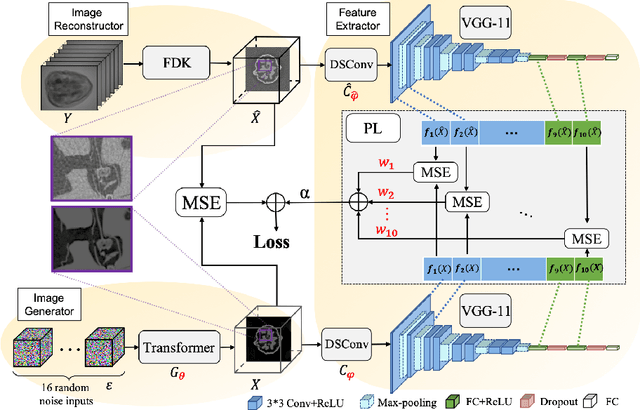
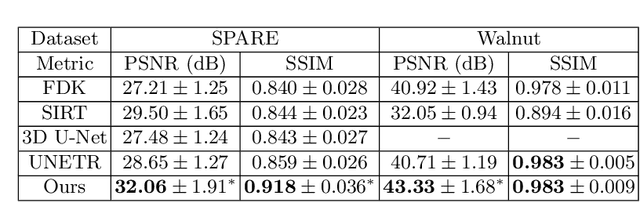
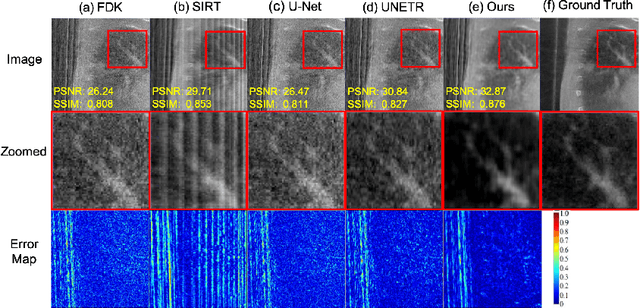
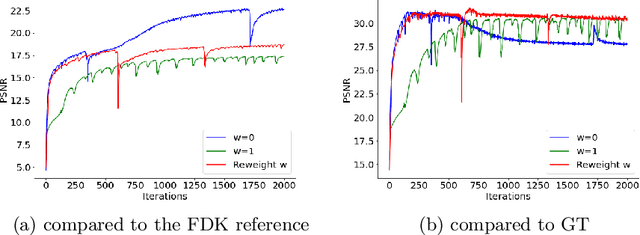
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.