 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBFLA: Block-Filtered Long-Context Attention Mechanism
May 12, 2026This paper proposes Block-Filtered Long-Context Attention (BFLA), a training-free sparse prefill attention mechanism for long-context inference. BFLA adopts a two-stage design. In Stage 1, query and key sequences are compressed into coarse blocks, and lightweight block-level softmax mass estimation is performed to construct an input-dependent block importance mask. In Stage 2, the coarse mask is expanded to the Triton attention-tile grid. Several tile-level rescue strategies are applied to reduce information loss, where a fused sparse prefill kernel skips unimportant KV tiles while preserving exact token-level attention inside every retained tile. BFLA requires no retraining, calibration, preprocessing, or model modification and can be plugged into existing vLLM-style paged-attention workloads. Experiments on Gemma 4, Llama 3.1, Qwen 3.5, and Qwen 3.6 series models show that BFLA substantially accelerates long-context prefilling with minimal accuracy degradation compared to dense Triton FlashAttention. Project website: https://github.com/Alicewithrabbit/BFLA.
An Interpretable Two-Stage Feature Decomposition Method for Deep Learning-based SAR ATR
Jun 11, 2025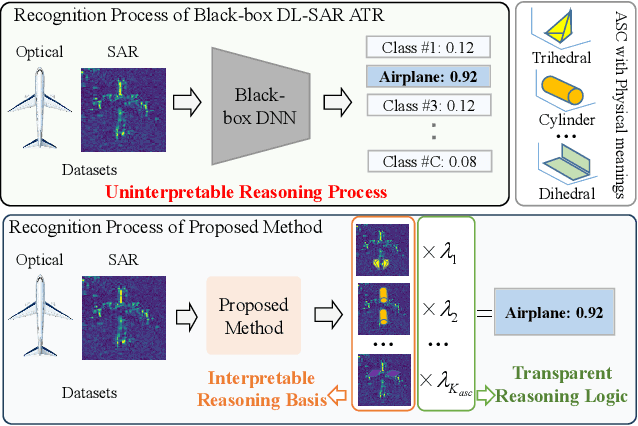
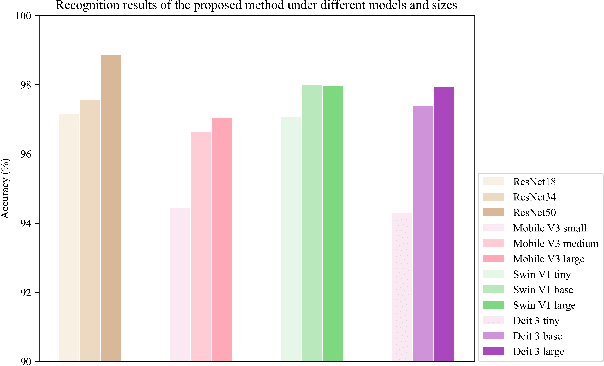
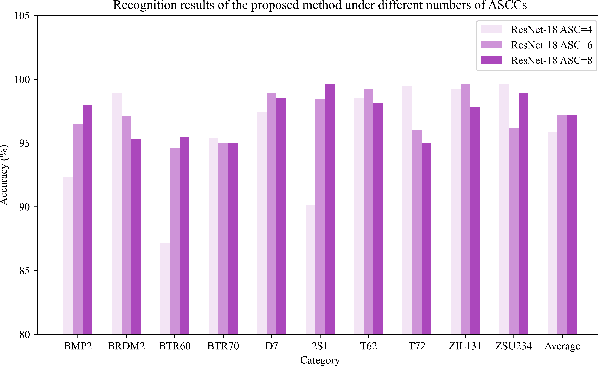
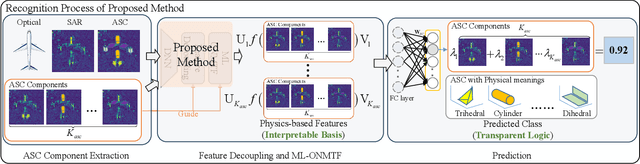
Synthetic aperture radar automatic target recognition (SAR ATR) has seen significant performance improvements with deep learning. However, the black-box nature of deep SAR ATR introduces low confidence and high risks in decision-critical SAR applications, hindering practical deployment. To address this issue, deep SAR ATR should provide an interpretable reasoning basis $r_b$ and logic $\lambda_w$, forming the reasoning logic $\sum_{i} {{r_b^i} \times {\lambda_w^i}} =pred$ behind the decisions. Therefore, this paper proposes a physics-based two-stage feature decomposition method for interpretable deep SAR ATR, which transforms uninterpretable deep features into attribute scattering center components (ASCC) with clear physical meanings. First, ASCCs are obtained through a clustering algorithm. To extract independent physical components from deep features, we propose a two-stage decomposition method. In the first stage, a feature decoupling and discrimination module separates deep features into approximate ASCCs with global discriminability. In the second stage, a multilayer orthogonal non-negative matrix tri-factorization (MLO-NMTF) further decomposes the ASCCs into independent components with distinct physical meanings. The MLO-NMTF elegantly aligns with the clustering algorithms to obtain ASCCs. Finally, this method ensures both an interpretable reasoning process and accurate recognition results. Extensive experiments on four benchmark datasets confirm its effectiveness, showcasing the method's interpretability, robust recognition performance, and strong generalization capability.
sparseGeoHOPCA: A Geometric Solution to Sparse Higher-Order PCA Without Covariance Estimation
Jun 10, 2025We propose sparseGeoHOPCA, a novel framework for sparse higher-order principal component analysis (SHOPCA) that introduces a geometric perspective to high-dimensional tensor decomposition. By unfolding the input tensor along each mode and reformulating the resulting subproblems as structured binary linear optimization problems, our method transforms the original nonconvex sparse objective into a tractable geometric form. This eliminates the need for explicit covariance estimation and iterative deflation, enabling significant gains in both computational efficiency and interpretability, particularly in high-dimensional and unbalanced data scenarios. We theoretically establish the equivalence between the geometric subproblems and the original SHOPCA formulation, and derive worst-case approximation error bounds based on classical PCA residuals, providing data-dependent performance guarantees. The proposed algorithm achieves a total computational complexity of $O\left(\sum_{n=1}^{N} (k_n^3 + J_n k_n^2)\right)$, which scales linearly with tensor size. Extensive experiments demonstrate that sparseGeoHOPCA accurately recovers sparse supports in synthetic settings, preserves classification performance under 10$\times$ compression, and achieves high-quality image reconstruction on ImageNet, highlighting its robustness and versatility.
ELFATT: Efficient Linear Fast Attention for Vision Transformers
Jan 10, 2025



The attention mechanism is the key to the success of transformers in different machine learning tasks. However, the quadratic complexity with respect to the sequence length of the vanilla softmax-based attention mechanism becomes the major bottleneck for the application of long sequence tasks, such as vision tasks. Although various efficient linear attention mechanisms have been proposed, they need to sacrifice performance to achieve high efficiency. What's more, memory-efficient methods, such as FlashAttention-1-3, still have quadratic computation complexity which can be further improved. In this paper, we propose a novel efficient linear fast attention (ELFATT) mechanism to achieve low memory input/output operations, linear computational complexity, and high performance at the same time. ELFATT offers 4-7x speedups over the vanilla softmax-based attention mechanism in high-resolution vision tasks without losing performance. ELFATT is FlashAttention friendly. Using FlashAttention-2 acceleration, ELFATT still offers 2-3x speedups over the vanilla softmax-based attention mechanism on high-resolution vision tasks without losing performance. Even on edge GPUs, ELFATT still offers 1.6x to 2.0x speedups compared to state-of-the-art attention mechanisms in various power modes from 5W to 60W. The code of ELFATT is available at [https://github.com/Alicewithrabbit/ELFATT].
Applying Self-supervised Learning to Network Intrusion Detection for Network Flows with Graph Neural Network
Mar 03, 2024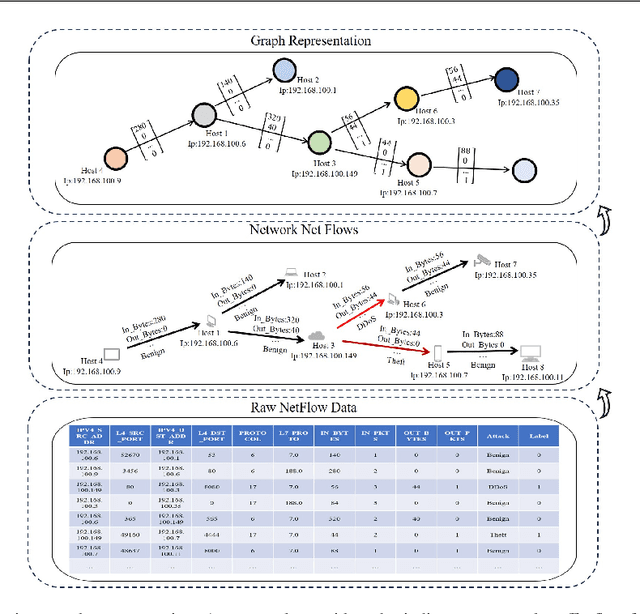
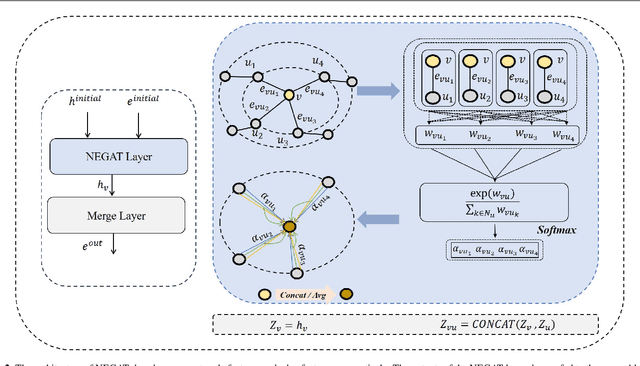
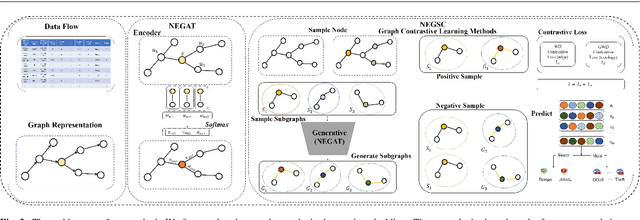
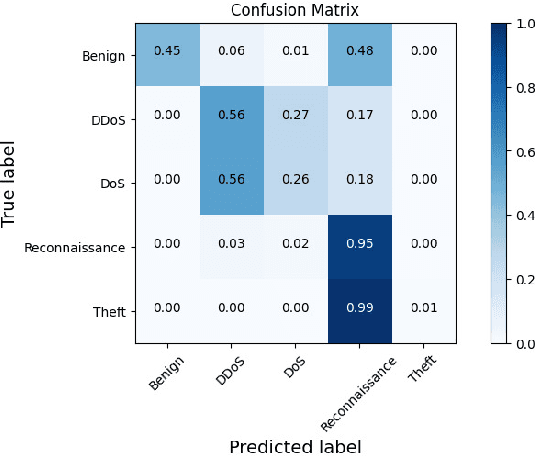
Graph Neural Networks (GNNs) have garnered intensive attention for Network Intrusion Detection System (NIDS) due to their suitability for representing the network traffic flows. However, most present GNN-based methods for NIDS are supervised or semi-supervised. Network flows need to be manually annotated as supervisory labels, a process that is time-consuming or even impossible, making NIDS difficult to adapt to potentially complex attacks, especially in large-scale real-world scenarios. The existing GNN-based self-supervised methods focus on the binary classification of network flow as benign or not, and thus fail to reveal the types of attack in practice. This paper studies the application of GNNs to identify the specific types of network flows in an unsupervised manner. We first design an encoder to obtain graph embedding, that introduces the graph attention mechanism and considers the edge information as the only essential factor. Then, a self-supervised method based on graph contrastive learning is proposed. The method samples center nodes, and for each center node, generates subgraph by it and its direct neighbor nodes, and corresponding contrastive subgraph from the interpolated graph, and finally constructs positive and negative samples from subgraphs. Furthermore, a structured contrastive loss function based on edge features and graph local topology is introduced. To the best of our knowledge, it is the first GNN-based self-supervised method for the multiclass classification of network flows in NIDS. Detailed experiments conducted on four real-world databases (NF-Bot-IoT, NF-Bot-IoT-v2, NF-CSE-CIC-IDS2018, and NF-CSE-CIC-IDS2018-v2) systematically compare our model with the state-of-the-art supervised and self-supervised models, illustrating the considerable potential of our method. Our code is accessible through https://github.com/renj-xu/NEGSC.
Deep Learning-Driven Edge Video Analytics: A Survey
Nov 28, 2022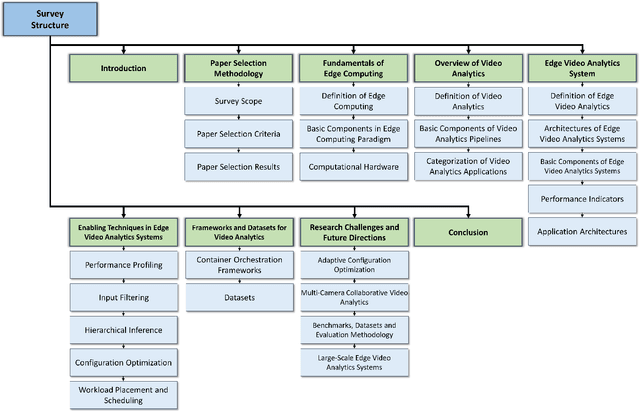



Video, as a key driver in the global explosion of digital information, can create tremendous benefits for human society. Governments and enterprises are deploying innumerable cameras for a variety of applications, e.g., law enforcement, emergency management, traffic control, and security surveillance, all facilitated by video analytics (VA). This trend is spurred by the rapid advancement of deep learning (DL), which enables more precise models for object classification, detection, and tracking. Meanwhile, with the proliferation of Internet-connected devices, massive amounts of data are generated daily, overwhelming the cloud. Edge computing, an emerging paradigm that moves workloads and services from the network core to the network edge, has been widely recognized as a promising solution. The resulting new intersection, edge video analytics (EVA), begins to attract widespread attention. Nevertheless, only a few loosely-related surveys exist on this topic. A dedicated venue for collecting and summarizing the latest advances of EVA is highly desired by the community. Besides, the basic concepts of EVA (e.g., definition, architectures, etc.) are ambiguous and neglected by these surveys due to the rapid development of this domain. A thorough clarification is needed to facilitate a consensus on these concepts. To fill in these gaps, we conduct a comprehensive survey of the recent efforts on EVA. In this paper, we first review the fundamentals of edge computing, followed by an overview of VA. The EVA system and its enabling techniques are discussed next. In addition, we introduce prevalent frameworks and datasets to aid future researchers in the development of EVA systems. Finally, we discuss existing challenges and foresee future research directions. We believe this survey will help readers comprehend the relationship between VA and edge computing, and spark new ideas on EVA.
Selecting task with optimal transport self-supervised learning for few-shot classification
Apr 01, 2022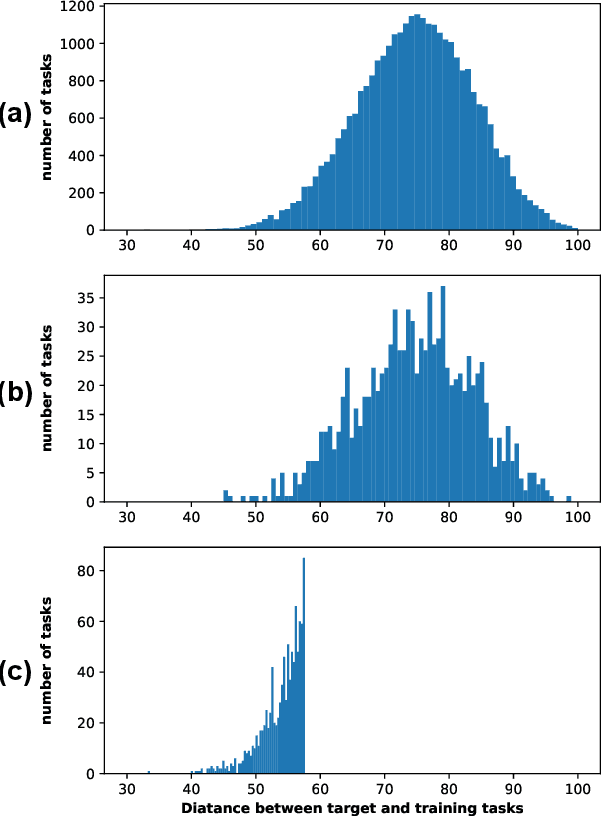
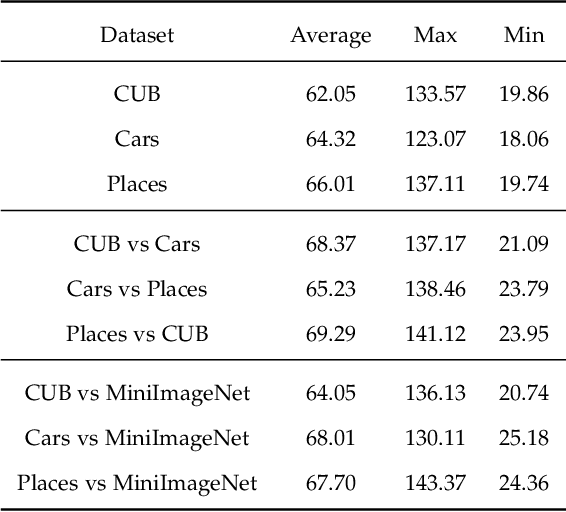

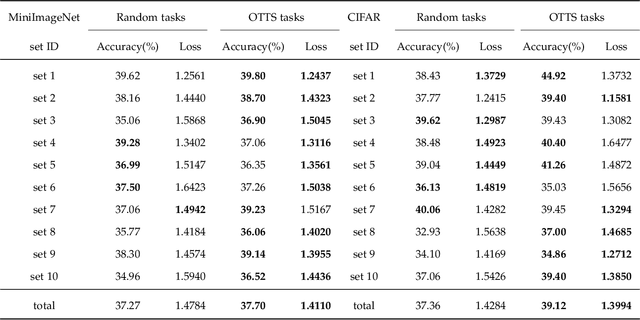
Few-Shot classification aims at solving problems that only a few samples are available in the training process. Due to the lack of samples, researchers generally employ a set of training tasks from other domains to assist the target task, where the distribution between assistant tasks and the target task is usually different. To reduce the distribution gap, several lines of methods have been proposed, such as data augmentation and domain alignment. However, one common drawback of these algorithms is that they ignore the similarity task selection before training. The fundamental problem is to push the auxiliary tasks close to the target task. In this paper, we propose a novel task selecting algorithm, named Optimal Transport Task Selecting (OTTS), to construct a training set by selecting similar tasks for Few-Shot learning. Specifically, the OTTS measures the task similarity by calculating the optimal transport distance and completes the model training via a self-supervised strategy. By utilizing the selected tasks with OTTS, the training process of Few-Shot learning become more stable and effective. Other proposed methods including data augmentation and domain alignment can be used in the meantime with OTTS. We conduct extensive experiments on a variety of datasets, including MiniImageNet, CIFAR, CUB, Cars, and Places, to evaluate the effectiveness of OTTS. Experimental results validate that our OTTS outperforms the typical baselines, i.e., MAML, matchingnet, protonet, by a large margin (averagely 1.72\% accuracy improvement).