 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Semantic Decoding with Vision Foundation Models for Few-shot Segmentation
Nov 19, 2025Few-shot segmentation has garnered significant attention. Many recent approaches attempt to introduce the Segment Anything Model (SAM) to handle this task. With the strong generalization ability and rich object-specific extraction ability of the SAM model, such a solution shows great potential in few-shot segmentation. However, the decoding process of SAM highly relies on accurate and explicit prompts, making previous approaches mainly focus on extracting prompts from the support set, which is insufficient to activate the generalization ability of SAM, and this design is easy to result in a biased decoding process when adapting to the unknown classes. In this work, we propose an Unbiased Semantic Decoding (USD) strategy integrated with SAM, which extracts target information from both the support and query set simultaneously to perform consistent predictions guided by the semantics of the Contrastive Language-Image Pre-training (CLIP) model. Specifically, to enhance the unbiased semantic discrimination of SAM, we design two feature enhancement strategies that leverage the semantic alignment capability of CLIP to enrich the original SAM features, mainly including a global supplement at the image level to provide a generalize category indicate with support image and a local guidance at the pixel level to provide a useful target location with query image. Besides, to generate target-focused prompt embeddings, a learnable visual-text target prompt generator is proposed by interacting target text embeddings and clip visual features. Without requiring re-training of the vision foundation models, the features with semantic discrimination draw attention to the target region through the guidance of prompt with rich target information.
Selecting task with optimal transport self-supervised learning for few-shot classification
Apr 01, 2022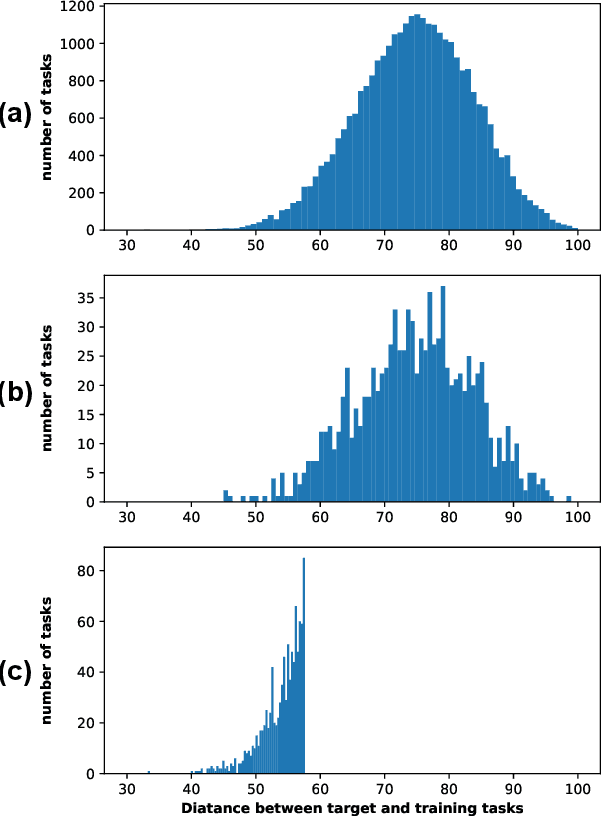
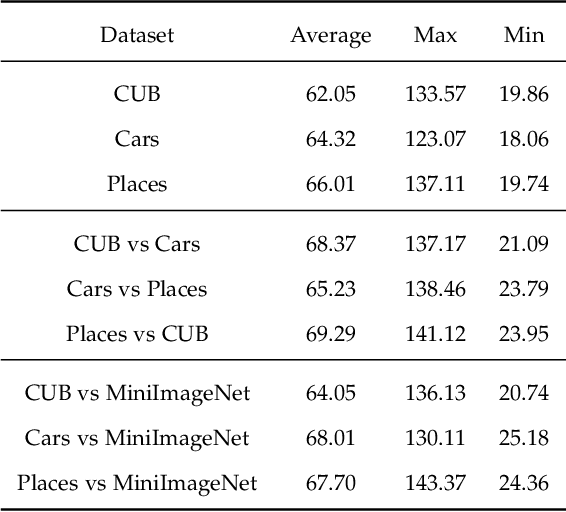

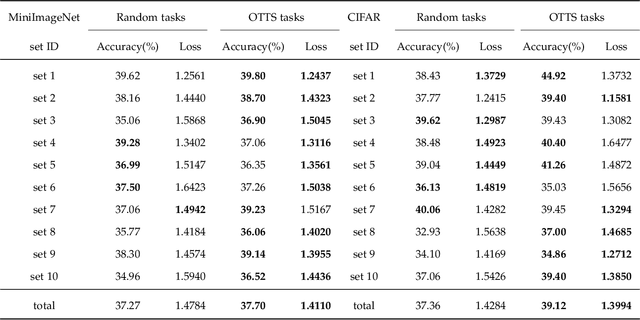
Few-Shot classification aims at solving problems that only a few samples are available in the training process. Due to the lack of samples, researchers generally employ a set of training tasks from other domains to assist the target task, where the distribution between assistant tasks and the target task is usually different. To reduce the distribution gap, several lines of methods have been proposed, such as data augmentation and domain alignment. However, one common drawback of these algorithms is that they ignore the similarity task selection before training. The fundamental problem is to push the auxiliary tasks close to the target task. In this paper, we propose a novel task selecting algorithm, named Optimal Transport Task Selecting (OTTS), to construct a training set by selecting similar tasks for Few-Shot learning. Specifically, the OTTS measures the task similarity by calculating the optimal transport distance and completes the model training via a self-supervised strategy. By utilizing the selected tasks with OTTS, the training process of Few-Shot learning become more stable and effective. Other proposed methods including data augmentation and domain alignment can be used in the meantime with OTTS. We conduct extensive experiments on a variety of datasets, including MiniImageNet, CIFAR, CUB, Cars, and Places, to evaluate the effectiveness of OTTS. Experimental results validate that our OTTS outperforms the typical baselines, i.e., MAML, matchingnet, protonet, by a large margin (averagely 1.72\% accuracy improvement).
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
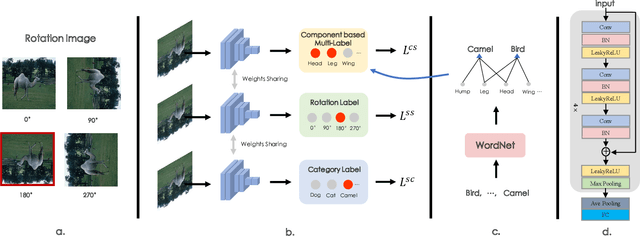

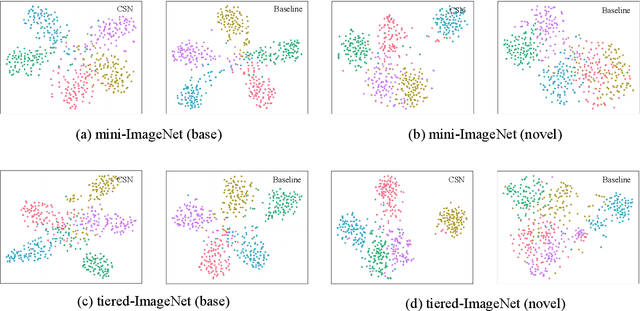
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.
SSDL: Self-Supervised Dictionary Learning
Dec 03, 2021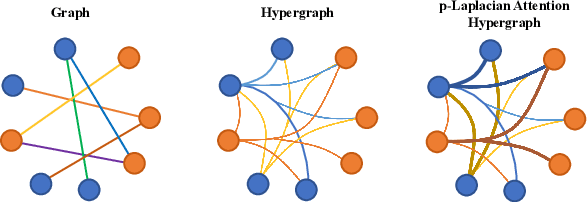
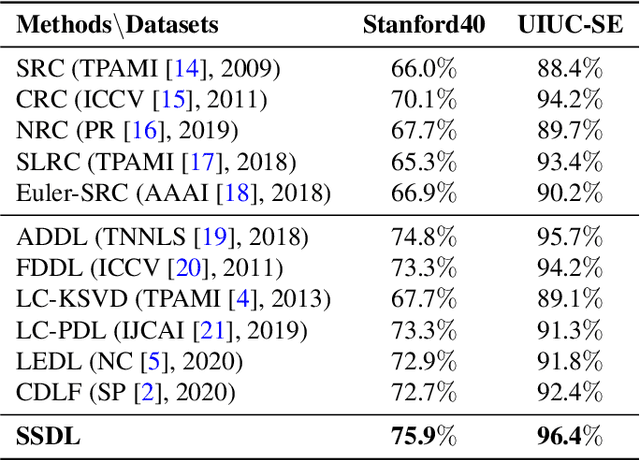
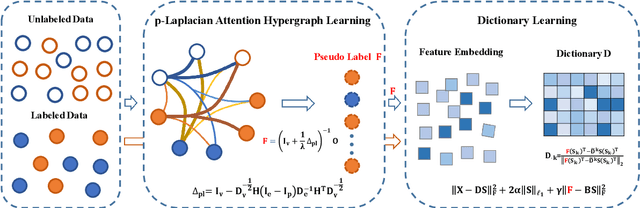
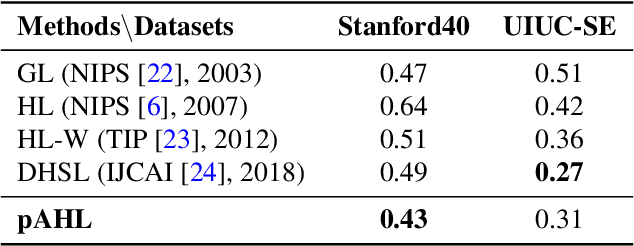
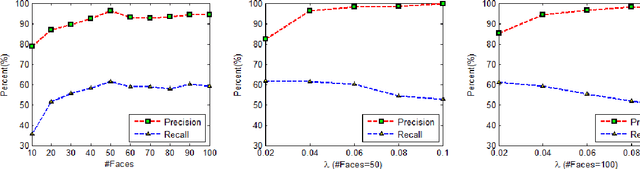
The label-embedded dictionary learning (DL) algorithms generate influential dictionaries by introducing discriminative information. However, there exists a limitation: All the label-embedded DL methods rely on the labels due that this way merely achieves ideal performances in supervised learning. While in semi-supervised and unsupervised learning, it is no longer sufficient to be effective. Inspired by the concept of self-supervised learning (e.g., setting the pretext task to generate a universal model for the downstream task), we propose a Self-Supervised Dictionary Learning (SSDL) framework to address this challenge. Specifically, we first design a $p$-Laplacian Attention Hypergraph Learning (pAHL) block as the pretext task to generate pseudo soft labels for DL. Then, we adopt the pseudo labels to train a dictionary from a primary label-embedded DL method. We evaluate our SSDL on two human activity recognition datasets. The comparison results with other state-of-the-art methods have demonstrated the efficiency of SSDL.
Robust Nonnegative Matrix Factorization via $L_1$ Norm Regularization
Apr 11, 2012
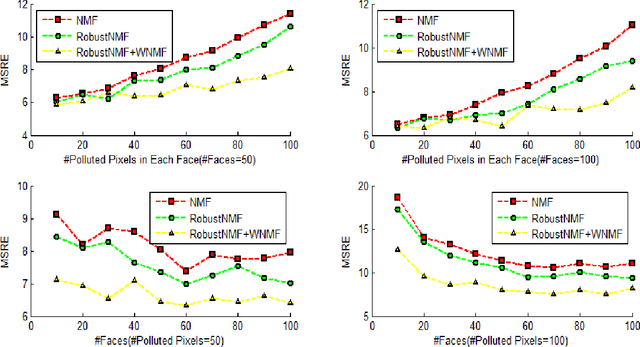

Nonnegative Matrix Factorization (NMF) is a widely used technique in many applications such as face recognition, motion segmentation, etc. It approximates the nonnegative data in an original high dimensional space with a linear representation in a low dimensional space by using the product of two nonnegative matrices. In many applications data are often partially corrupted with large additive noise. When the positions of noise are known, some existing variants of NMF can be applied by treating these corrupted entries as missing values. However, the positions are often unknown in many real world applications, which prevents the usage of traditional NMF or other existing variants of NMF. This paper proposes a Robust Nonnegative Matrix Factorization (RobustNMF) algorithm that explicitly models the partial corruption as large additive noise without requiring the information of positions of noise. In practice, large additive noise can be used to model outliers. In particular, the proposed method jointly approximates the clean data matrix with the product of two nonnegative matrices and estimates the positions and values of outliers/noise. An efficient iterative optimization algorithm with a solid theoretical justification has been proposed to learn the desired matrix factorization. Experimental results demonstrate the advantages of the proposed algorithm.