 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKronecker-Structured Nonparametric Spatiotemporal Point Processes
Mar 24, 2026Events in spatiotemporal domains arise in numerous real-world applications, where uncovering event relationships and enabling accurate prediction are central challenges. Classical Poisson and Hawkes processes rely on restrictive parametric assumptions that limit their ability to capture complex interaction patterns, while recent neural point process models increase representational capacity but integrate event information in a black-box manner, hindering interpretable relationship discovery. To address these limitations, we propose a Kronecker-Structured Nonparametric Spatiotemporal Point Process (KSTPP) that enables transparent event-wise relationship discovery while retaining high modeling flexibility. We model the background intensity with a spatial Gaussian process (GP) and the influence kernel as a spatiotemporal GP, allowing rich interaction patterns including excitation, inhibition, neutrality, and time-varying effects. To enable scalable training and prediction, we adopt separable product kernels and represent the GPs on structured grids, inducing Kronecker-structured covariance matrices. Exploiting Kronecker algebra substantially reduces computational cost and allows the model to scale to large event collections. In addition, we develop a tensor-product Gauss-Legendre quadrature scheme to efficiently evaluate intractable likelihood integrals. Extensive experiments demonstrate the effectiveness of our framework.
Query Suggestion for Retrieval-Augmented Generation via Dynamic In-Context Learning
Jan 13, 2026Retrieval-augmented generation with tool-calling agents (agentic RAG) has become increasingly powerful in understanding, processing, and responding to user queries. However, the scope of the grounding knowledge is limited and asking questions that exceed this scope may lead to issues like hallucination. While guardrail frameworks aim to block out-of-scope questions (Rodriguez et al., 2024), no research has investigated the question of suggesting answerable queries in order to complete the user interaction. In this paper, we initiate the study of query suggestion for agentic RAG. We consider the setting where user questions are not answerable, and the suggested queries should be similar to aid the user interaction. Such scenarios are frequent for tool-calling LLMs as communicating the restrictions of the tools or the underlying datasets to the user is difficult, and adding query suggestions enhances the interaction with the RAG agent. As opposed to traditional settings for query recommendations such as in search engines, ensuring that the suggested queries are answerable is a major challenge due to the RAG's multi-step workflow that demands a nuanced understanding of the RAG as a whole, which the executing LLM lacks. As such, we introduce robust dynamic few-shot learning which retrieves examples from relevant workflows. We show that our system can be self-learned, for instance on prior user queries, and is therefore easily applicable in practice. We evaluate our approach on three benchmark datasets based on two unlabeled question datasets collected from real-world user queries. Experiments on real-world datasets confirm that our method produces more relevant and answerable suggestions, outperforming few-shot and retrieval-only baselines, and thus enable safer, more effective user interaction with agentic RAG.
Modeling and Performance Analysis for Semantic Communications Based on Empirical Results
Apr 29, 2025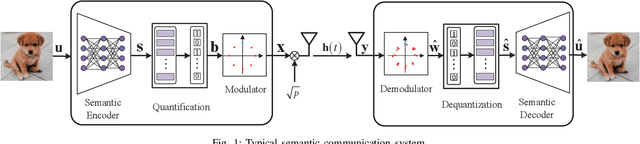
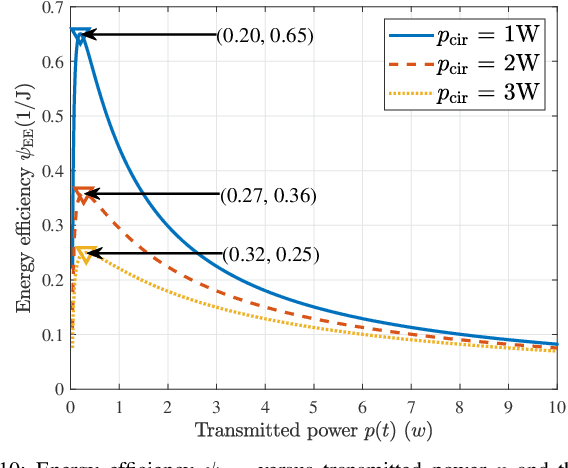
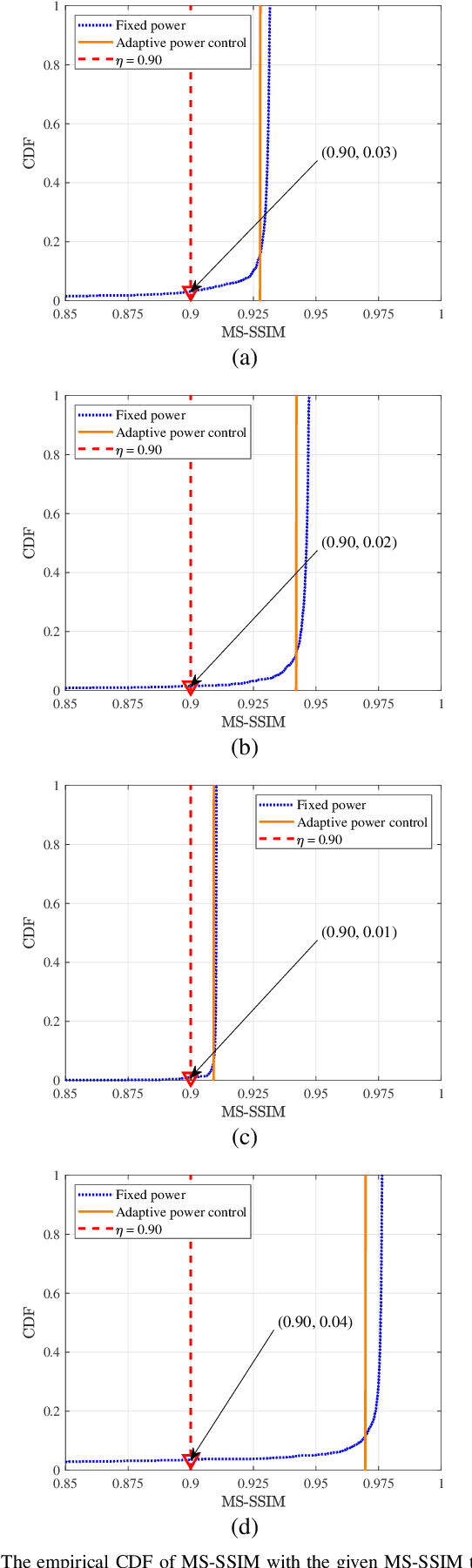
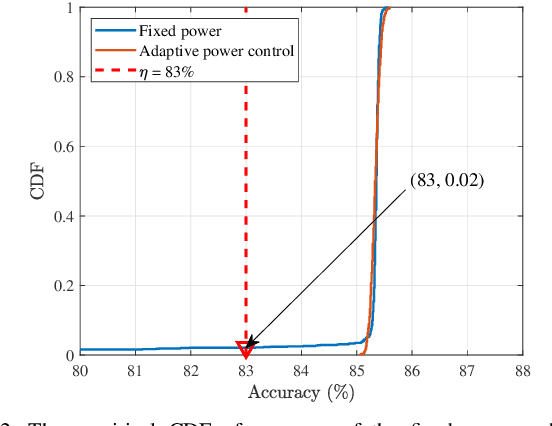
Due to the black-box characteristics of deep learning based semantic encoders and decoders, finding a tractable method for the performance analysis of semantic communications is a challenging problem. In this paper, we propose an Alpha-Beta-Gamma (ABG) formula to model the relationship between the end-to-end measurement and SNR, which can be applied for both image reconstruction tasks and inference tasks. Specifically, for image reconstruction tasks, the proposed ABG formula can well fit the commonly used DL networks, such as SCUNet, and Vision Transformer, for semantic encoding with the multi scale-structural similarity index measure (MS-SSIM) measurement. Furthermore, we find that the upper bound of the MS-SSIM depends on the number of quantized output bits of semantic encoders, and we also propose a closed-form expression to fit the relationship between the MS-SSIM and quantized output bits. To the best of our knowledge, this is the first theoretical expression between end-to-end performance metrics and SNR for semantic communications. Based on the proposed ABG formula, we investigate an adaptive power control scheme for semantic communications over random fading channels, which can effectively guarantee quality of service (QoS) for semantic communications, and then design the optimal power allocation scheme to maximize the energy efficiency of the semantic communication system. Furthermore, by exploiting the bisection algorithm, we develop the power allocation scheme to maximize the minimum QoS of multiple users for OFDMA downlink semantic communication Extensive simulations verify the effectiveness and superiority of the proposed ABG formula and power allocation schemes.
The Devil is in the Sources! Knowledge Enhanced Cross-Domain Recommendation in an Information Bottleneck Perspective
Sep 29, 2024



Cross-domain Recommendation (CDR) aims to alleviate the data sparsity and the cold-start problems in traditional recommender systems by leveraging knowledge from an informative source domain. However, previously proposed CDR models pursue an imprudent assumption that the entire information from the source domain is equally contributed to the target domain, neglecting the evil part that is completely irrelevant to users' intrinsic interest. To address this concern, in this paper, we propose a novel knowledge enhanced cross-domain recommendation framework named CoTrans, which remolds the core procedures of CDR models with: Compression on the knowledge from the source domain and Transfer of the purity to the target domain. Specifically, following the theory of Graph Information Bottleneck, CoTrans first compresses the source behaviors with the perception of information from the target domain. Then to preserve all the important information for the CDR task, the feedback signals from both domains are utilized to promote the effectiveness of the transfer procedure. Additionally, a knowledge-enhanced encoder is employed to narrow gaps caused by the non-overlapped items across separate domains. Comprehensive experiments on three widely used cross-domain datasets demonstrate that CoTrans significantly outperforms both single-domain and state-of-the-art cross-domain recommendation approaches.
Semantic Feature Division Multiple Access for Multi-user Digital Interference Networks
Jul 11, 2024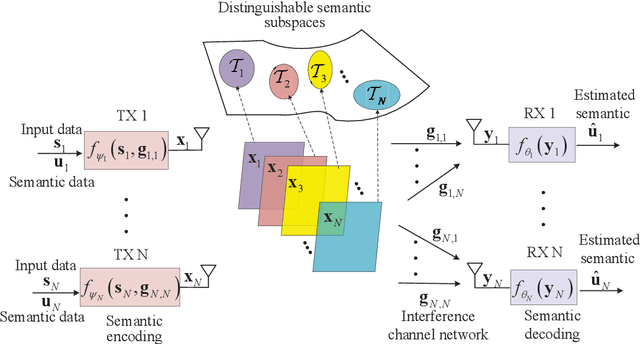


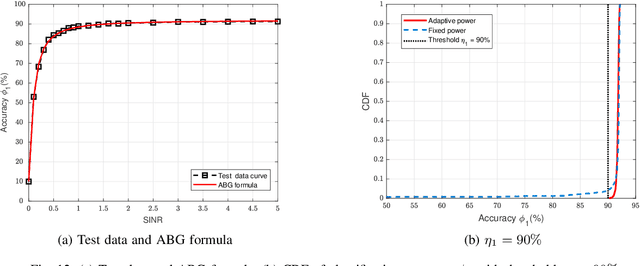
With the ever-increasing user density and quality of service (QoS) demand,5G networks with limited spectrum resources are facing massive access challenges. To address these challenges, in this paper, we propose a novel discrete semantic feature division multiple access (SFDMA) paradigm for multi-user digital interference networks. Specifically, by utilizing deep learning technology, SFDMA extracts multi-user semantic information into discrete representations in distinguishable semantic subspaces, which enables multiple users to transmit simultaneously over the same time-frequency resources. Furthermore, based on a robust information bottleneck, we design a SFDMA based multi-user digital semantic interference network for inference tasks, which can achieve approximate orthogonal transmission. Moreover, we propose a SFDMA based multi-user digital semantic interference network for image reconstruction tasks, where the discrete outputs of the semantic encoders of the users are approximately orthogonal, which significantly reduces multi-user interference. Furthermore, we propose an Alpha-Beta-Gamma (ABG) formula for semantic communications, which is the first theoretical relationship between inference accuracy and transmission power. Then, we derive adaptive power control methods with closed-form expressions for inference tasks. Extensive simulations verify the effectiveness and superiority of the proposed SFDMA.
Deep Partial Multiplex Network Embedding
Mar 05, 2022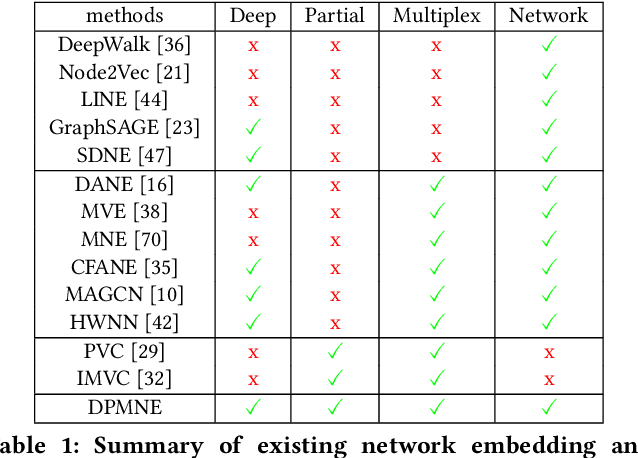
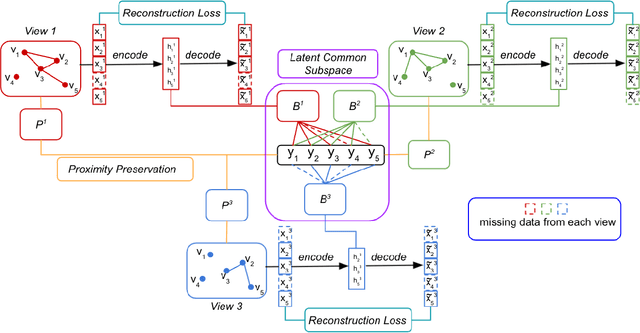
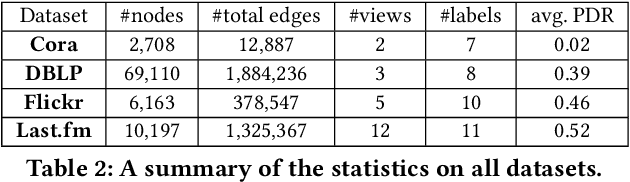
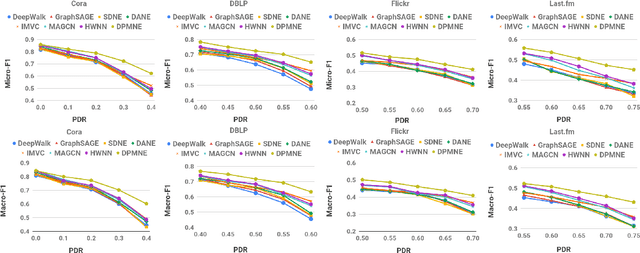
Network embedding is an effective technique to learn the low-dimensional representations of nodes in networks. Real-world networks are usually with multiplex or having multi-view representations from different relations. Recently, there has been increasing interest in network embedding on multiplex data. However, most existing multiplex approaches assume that the data is complete in all views. But in real applications, it is often the case that each view suffers from the missing of some data and therefore results in partial multiplex data. In this paper, we present a novel Deep Partial Multiplex Network Embedding approach to deal with incomplete data. In particular, the network embeddings are learned by simultaneously minimizing the deep reconstruction loss with the autoencoder neural network, enforcing the data consistency across views via common latent subspace learning, and preserving the data topological structure within the same network through graph Laplacian. We further prove the orthogonal invariant property of the learned embeddings and connect our approach with the binary embedding techniques. Experiments on four multiplex benchmarks demonstrate the superior performance of the proposed approach over several state-of-the-art methods on node classification, link prediction and clustering tasks.
DART: Domain-Adversarial Residual-Transfer Networks for Unsupervised Cross-Domain Image Classification
Dec 30, 2018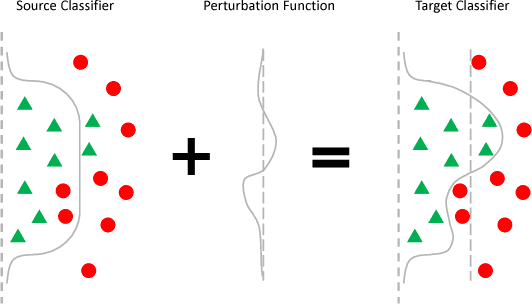

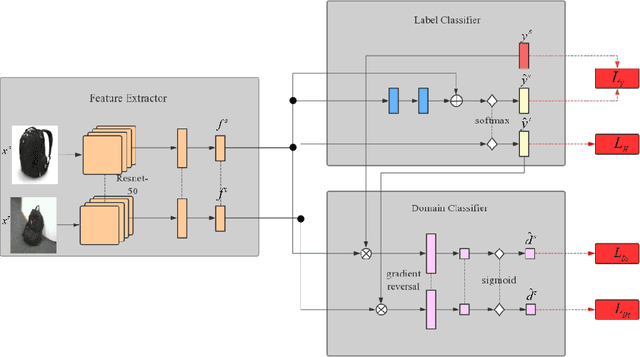
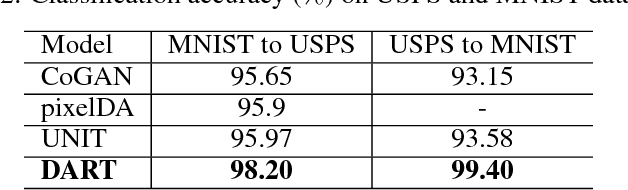
The accuracy of deep learning (e.g., convolutional neural networks) for an image classification task critically relies on the amount of labeled training data. Aiming to solve an image classification task on a new domain that lacks labeled data but gains access to cheaply available unlabeled data, unsupervised domain adaptation is a promising technique to boost the performance without incurring extra labeling cost, by assuming images from different domains share some invariant characteristics. In this paper, we propose a new unsupervised domain adaptation method named Domain-Adversarial Residual-Transfer (DART) learning of Deep Neural Networks to tackle cross-domain image classification tasks. In contrast to the existing unsupervised domain adaption approaches, the proposed DART not only learns domain-invariant features via adversarial training, but also achieves robust domain-adaptive classification via a residual-transfer strategy, all in an end-to-end training framework. We evaluate the performance of the proposed method for cross-domain image classification tasks on several well-known benchmark data sets, in which our method clearly outperforms the state-of-the-art approaches.
Image Tag Completion by Low-rank Factorization with Dual Reconstruction Structure Preserved
Jun 09, 2014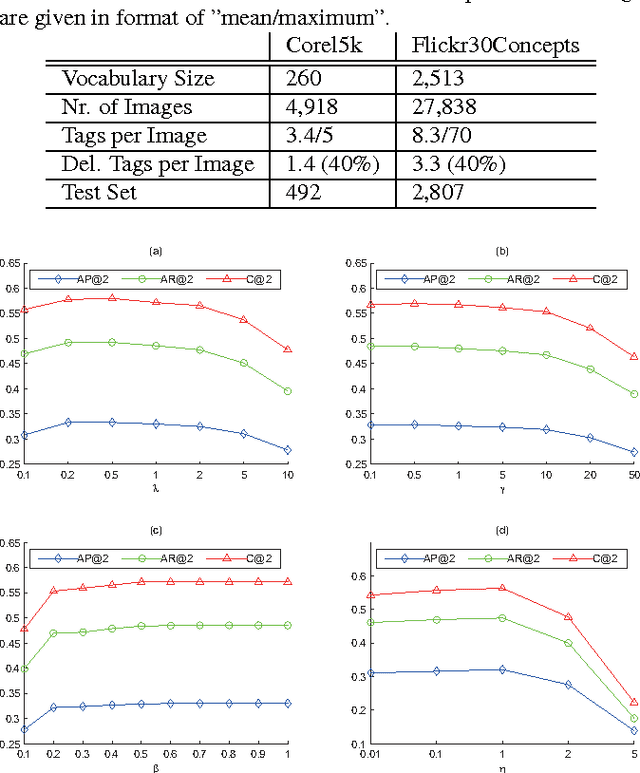
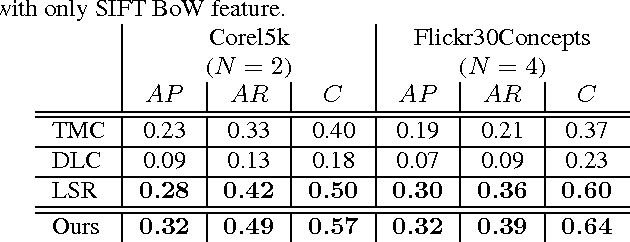
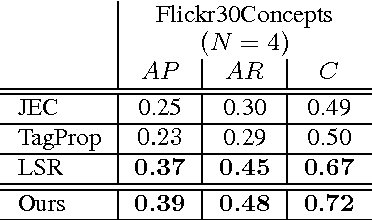
A novel tag completion algorithm is proposed in this paper, which is designed with the following features: 1) Low-rank and error s-parsity: the incomplete initial tagging matrix D is decomposed into the complete tagging matrix A and a sparse error matrix E. However, instead of minimizing its nuclear norm, A is further factor-ized into a basis matrix U and a sparse coefficient matrix V, i.e. D=UV+E. This low-rank formulation encapsulating sparse coding enables our algorithm to recover latent structures from noisy initial data and avoid performing too much denoising; 2) Local reconstruction structure consistency: to steer the completion of D, the local linear reconstruction structures in feature space and tag space are obtained and preserved by U and V respectively. Such a scheme could alleviate the negative effect of distances measured by low-level features and incomplete tags. Thus, we can seek a balance between exploiting as much information and not being mislead to suboptimal performance. Experiments conducted on Corel5k dataset and the newly issued Flickr30Concepts dataset demonstrate the effectiveness and efficiency of the proposed method.
Robust Nonnegative Matrix Factorization via $L_1$ Norm Regularization
Apr 11, 2012
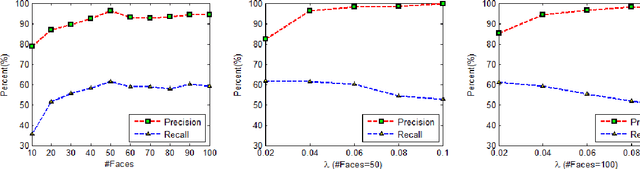
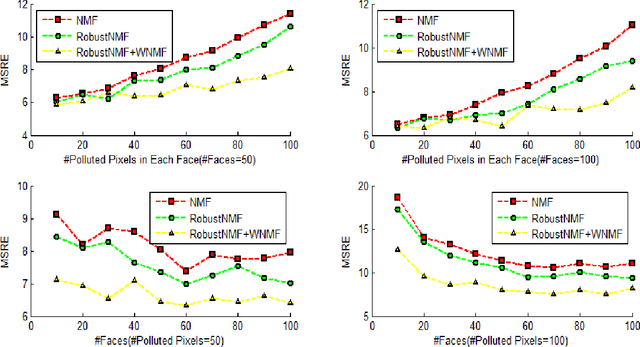

Nonnegative Matrix Factorization (NMF) is a widely used technique in many applications such as face recognition, motion segmentation, etc. It approximates the nonnegative data in an original high dimensional space with a linear representation in a low dimensional space by using the product of two nonnegative matrices. In many applications data are often partially corrupted with large additive noise. When the positions of noise are known, some existing variants of NMF can be applied by treating these corrupted entries as missing values. However, the positions are often unknown in many real world applications, which prevents the usage of traditional NMF or other existing variants of NMF. This paper proposes a Robust Nonnegative Matrix Factorization (RobustNMF) algorithm that explicitly models the partial corruption as large additive noise without requiring the information of positions of noise. In practice, large additive noise can be used to model outliers. In particular, the proposed method jointly approximates the clean data matrix with the product of two nonnegative matrices and estimates the positions and values of outliers/noise. An efficient iterative optimization algorithm with a solid theoretical justification has been proposed to learn the desired matrix factorization. Experimental results demonstrate the advantages of the proposed algorithm.