 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Partial Multiplex Network Embedding
Mar 05, 2022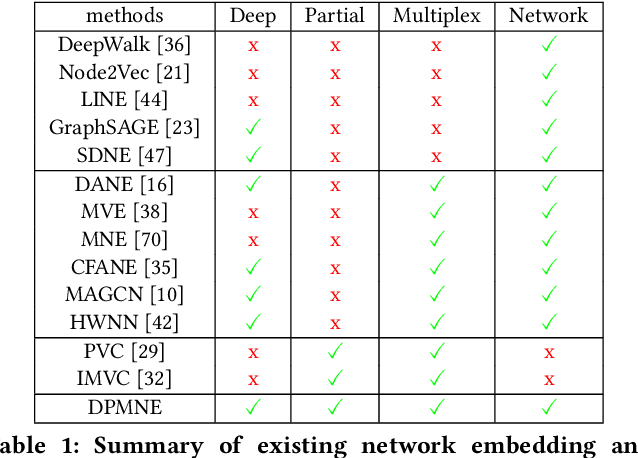
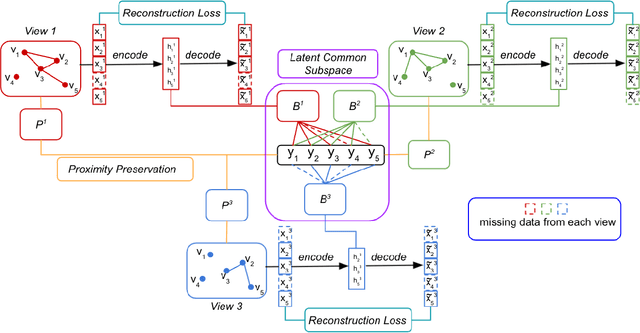
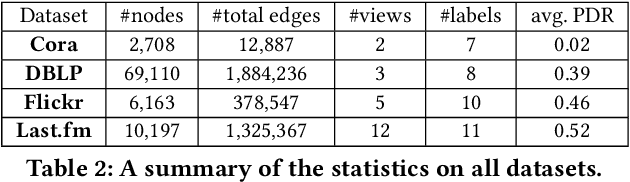
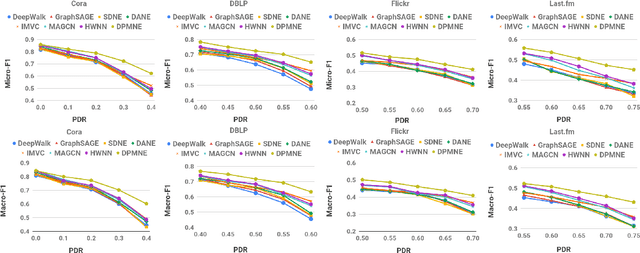
Network embedding is an effective technique to learn the low-dimensional representations of nodes in networks. Real-world networks are usually with multiplex or having multi-view representations from different relations. Recently, there has been increasing interest in network embedding on multiplex data. However, most existing multiplex approaches assume that the data is complete in all views. But in real applications, it is often the case that each view suffers from the missing of some data and therefore results in partial multiplex data. In this paper, we present a novel Deep Partial Multiplex Network Embedding approach to deal with incomplete data. In particular, the network embeddings are learned by simultaneously minimizing the deep reconstruction loss with the autoencoder neural network, enforcing the data consistency across views via common latent subspace learning, and preserving the data topological structure within the same network through graph Laplacian. We further prove the orthogonal invariant property of the learned embeddings and connect our approach with the binary embedding techniques. Experiments on four multiplex benchmarks demonstrate the superior performance of the proposed approach over several state-of-the-art methods on node classification, link prediction and clustering tasks.
WebFormer: The Web-page Transformer for Structure Information Extraction
Feb 01, 2022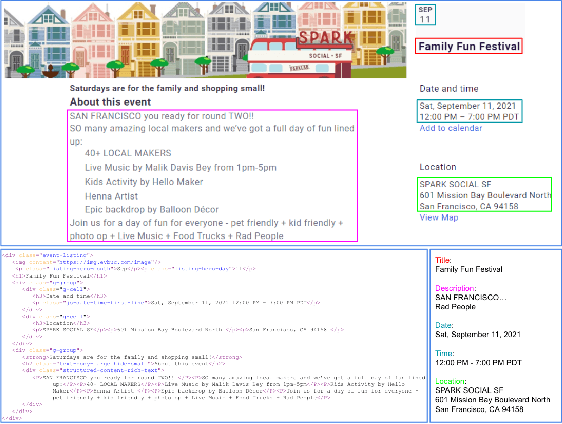
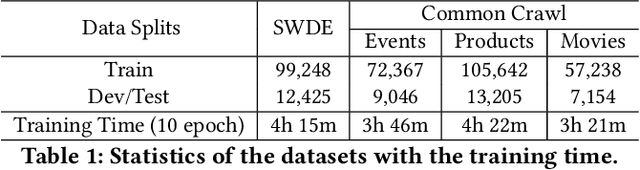
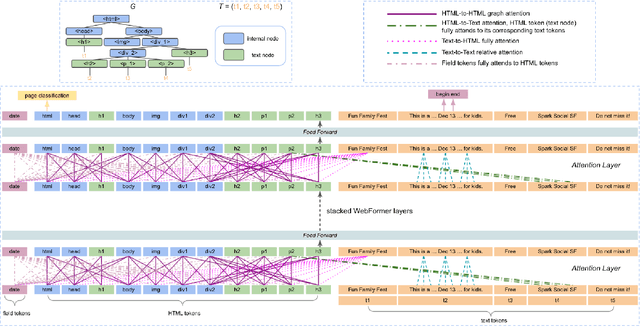
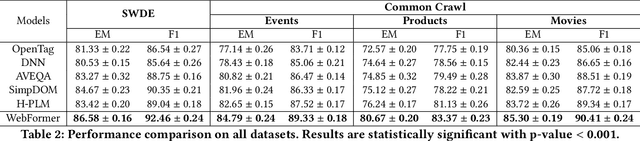
Structure information extraction refers to the task of extracting structured text fields from web pages, such as extracting a product offer from a shopping page including product title, description, brand and price. It is an important research topic which has been widely studied in document understanding and web search. Recent natural language models with sequence modeling have demonstrated state-of-the-art performance on web information extraction. However, effectively serializing tokens from unstructured web pages is challenging in practice due to a variety of web layout patterns. Limited work has focused on modeling the web layout for extracting the text fields. In this paper, we introduce WebFormer, a Web-page transFormer model for structure information extraction from web documents. First, we design HTML tokens for each DOM node in the HTML by embedding representations from their neighboring tokens through graph attention. Second, we construct rich attention patterns between HTML tokens and text tokens, which leverages the web layout for effective attention weight computation. We conduct an extensive set of experiments on SWDE and Common Crawl benchmarks. Experimental results demonstrate the superior performance of the proposed approach over several state-of-the-art methods.
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

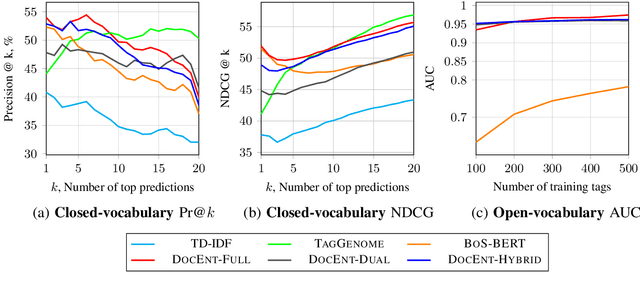
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.
RealFormer: Transformer Likes Residual Attention
Dec 23, 2020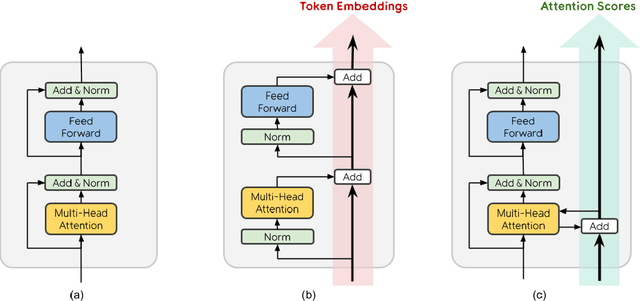
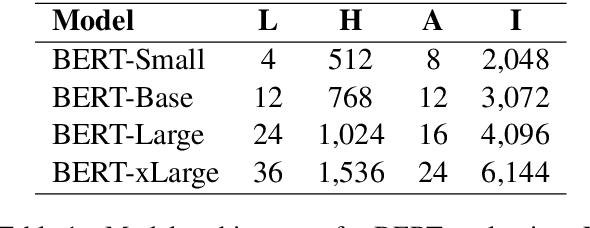
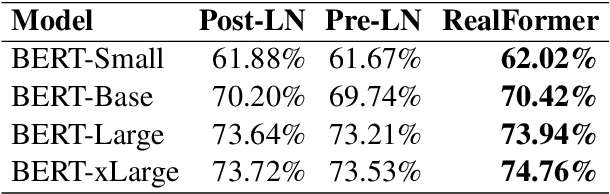
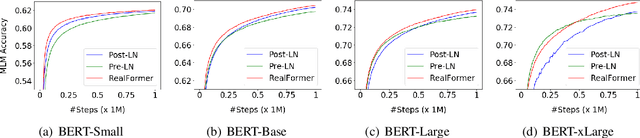
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple Residual Attention Layer Transformer architecture that significantly outperforms canonical Transformers on a spectrum of tasks including Masked Language Modeling, GLUE, and SQuAD. Qualitatively, RealFormer is easy to implement and requires minimal hyper-parameter tuning. It also stabilizes training and leads to models with sparser attentions. Code will be open-sourced upon paper acceptance.
Big Bird: Transformers for Longer Sequences
Jul 28, 2020
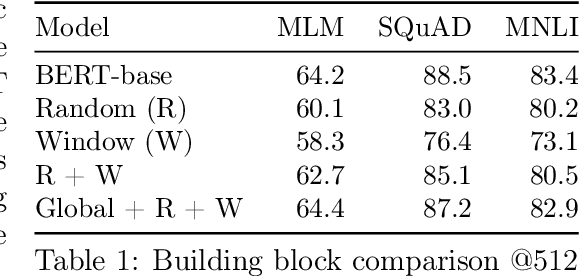

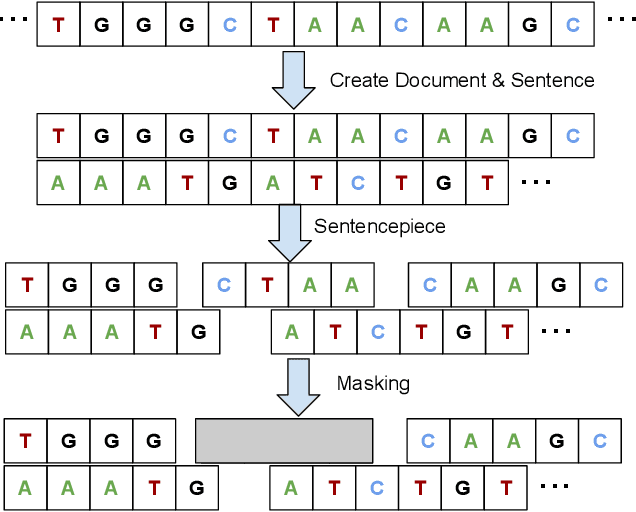
Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.
ETC: Encoding Long and Structured Data in Transformers
Apr 21, 2020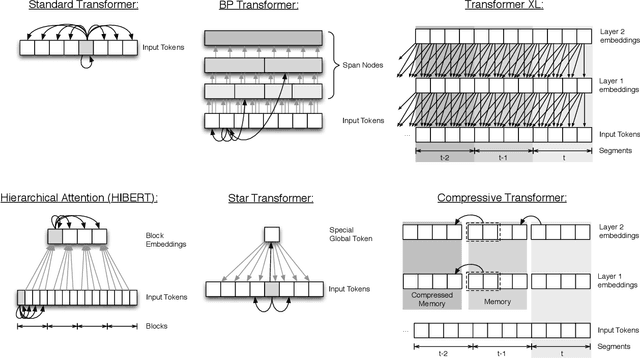
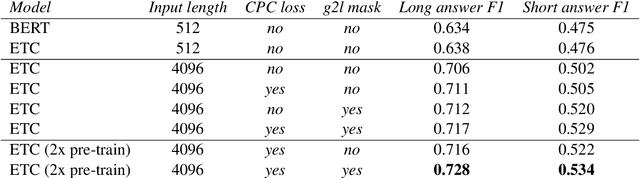
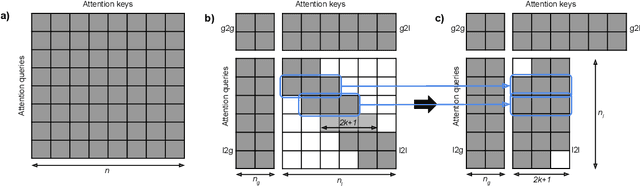
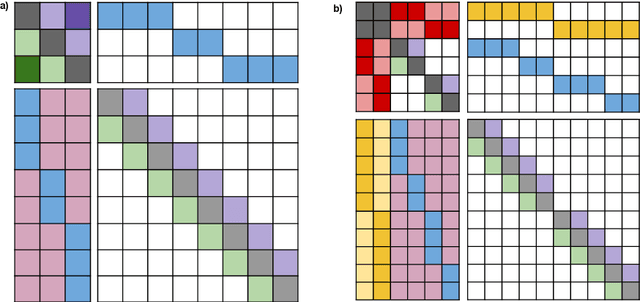
Transformer-based models have pushed the state of the art in many natural language processing tasks. However, one of their main limitations is the quadratic computational and memory cost of the standard attention mechanism. In this paper, we present a new family of Transformer models, which we call the Extended Transformer Construction (ETC), that allows for significant increases in input sequence length by introducing a new global-local attention mechanism between a global memory and the standard input tokens. We also show that combining global-local attention with relative position encodings allows ETC to handle structured data with ease. Empirical results on the Natural Questions data set show the promise of the approach.