 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022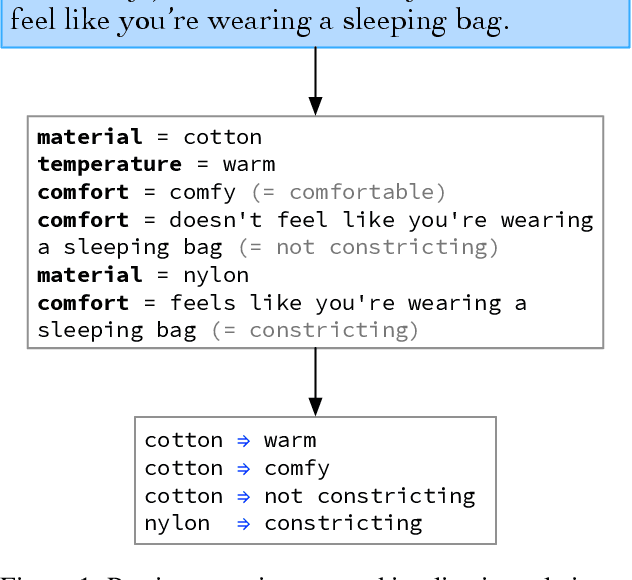

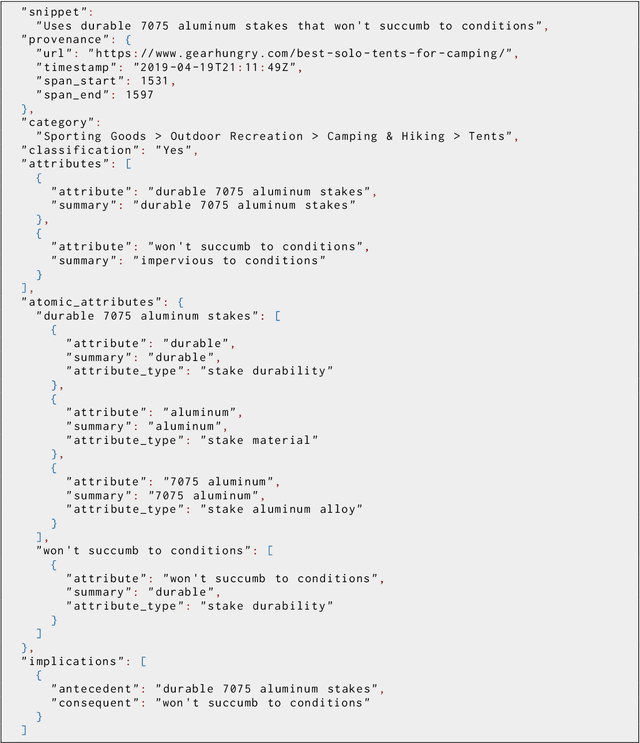
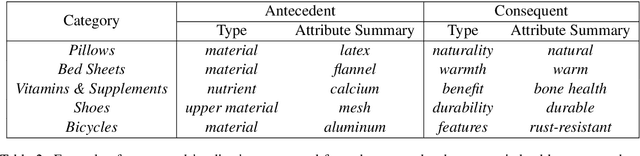
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.
MAVE: A Product Dataset for Multi-source Attribute Value Extraction
Dec 16, 2021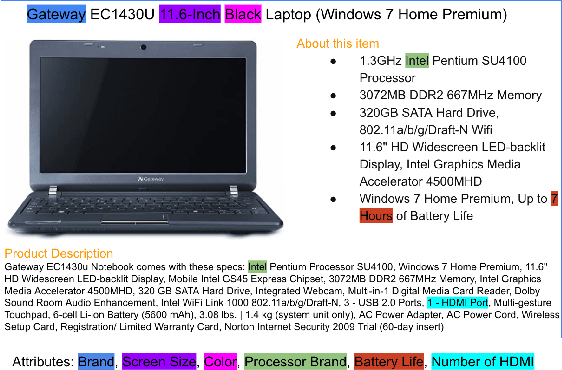
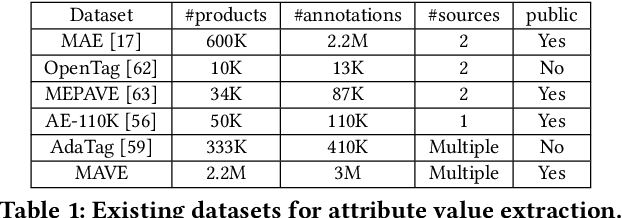

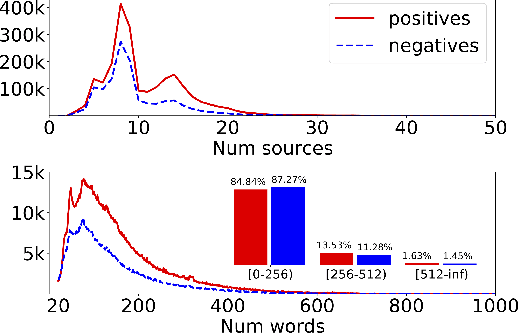
Attribute value extraction refers to the task of identifying values of an attribute of interest from product information. Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product ranking, retrieval and recommendations. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we introduce MAVE, a new dataset to better facilitate research on product attribute value extraction. MAVE is composed of a curated set of 2.2 million products from Amazon pages, with 3 million attribute-value annotations across 1257 unique categories. MAVE has four main and unique advantages: First, MAVE is the largest product attribute value extraction dataset by the number of attribute-value examples. Second, MAVE includes multi-source representations from the product, which captures the full product information with high attribute coverage. Third, MAVE represents a more diverse set of attributes and values relative to what previous datasets cover. Lastly, MAVE provides a very challenging zero-shot test set, as we empirically illustrate in the experiments. We further propose a novel approach that effectively extracts the attribute value from the multi-source product information. We conduct extensive experiments with several baselines and show that MAVE is an effective dataset for attribute value extraction task. It is also a very challenging task on zero-shot attribute extraction. Data is available at {\it \url{https://github.com/google-research-datasets/MAVE}}.
ShopTalk: A System for Conversational Faceted Search
Sep 02, 2021


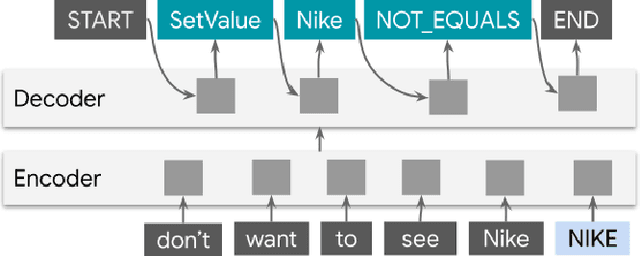
We present ShopTalk, a multi-turn conversational faceted search system for shopping that is designed to handle large and complex schemas that are beyond the scope of state of the art slot-filling systems. ShopTalk decouples dialog management from fulfillment, thereby allowing the dialog understanding system to be domain-agnostic and not tied to the particular shopping application. The dialog understanding system consists of a deep-learned Contextual Language Understanding module, which interprets user utterances, and a primarily rules-based Dialog-State Tracker (DST), which updates the dialog state and formulates search requests intended for the fulfillment engine. The interface between the two modules consists of a minimal set of domain-agnostic "intent operators," which instruct the DST on how to update the dialog state. ShopTalk was deployed in 2020 on the Google Assistant for Shopping searches.
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

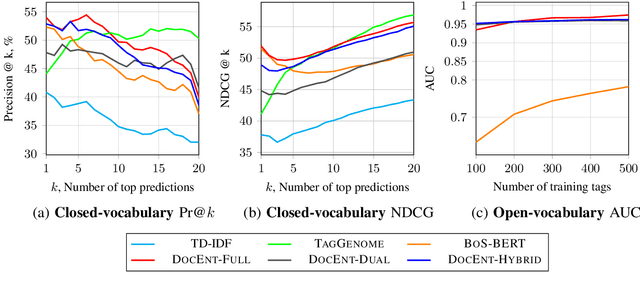
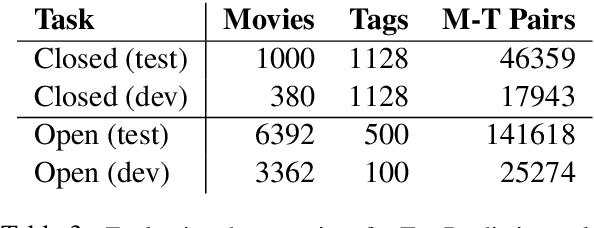
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.
RealFormer: Transformer Likes Residual Attention
Dec 23, 2020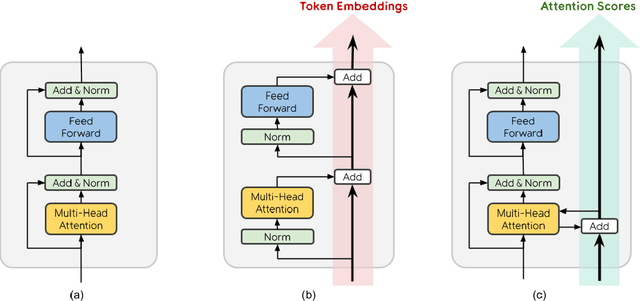
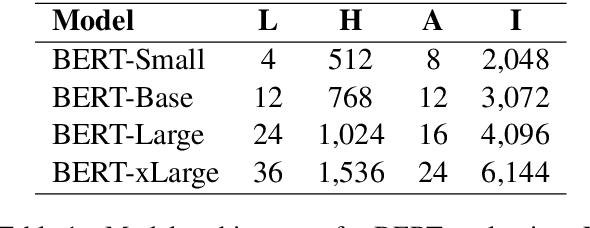
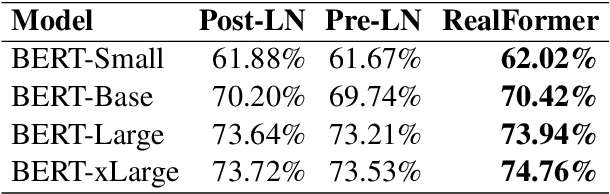
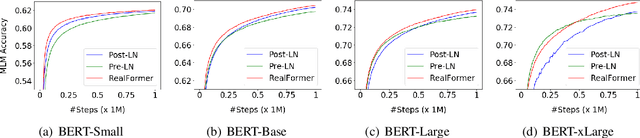
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple Residual Attention Layer Transformer architecture that significantly outperforms canonical Transformers on a spectrum of tasks including Masked Language Modeling, GLUE, and SQuAD. Qualitatively, RealFormer is easy to implement and requires minimal hyper-parameter tuning. It also stabilizes training and leads to models with sparser attentions. Code will be open-sourced upon paper acceptance.
A Generic Coordinate Descent Framework for Learning from Implicit Feedback
Nov 15, 2016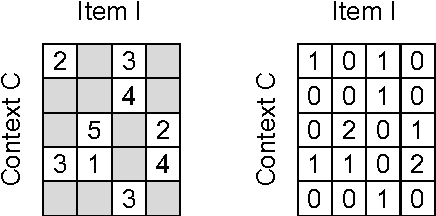
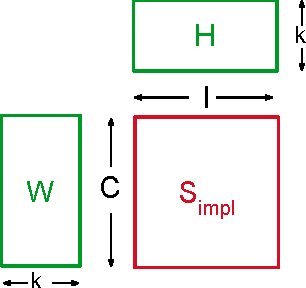
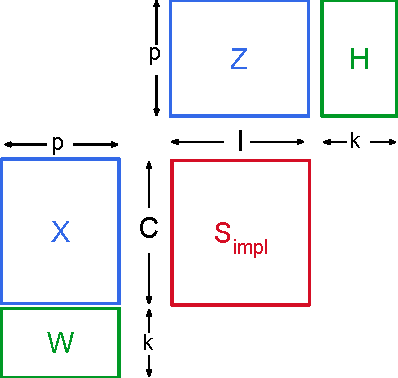
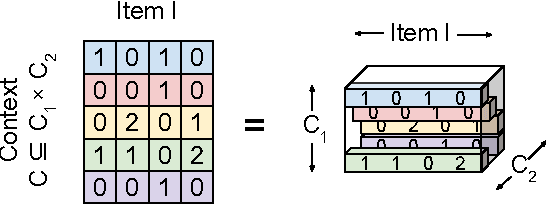
In recent years, interest in recommender research has shifted from explicit feedback towards implicit feedback data. A diversity of complex models has been proposed for a wide variety of applications. Despite this, learning from implicit feedback is still computationally challenging. So far, most work relies on stochastic gradient descent (SGD) solvers which are easy to derive, but in practice challenging to apply, especially for tasks with many items. For the simple matrix factorization model, an efficient coordinate descent (CD) solver has been previously proposed. However, efficient CD approaches have not been derived for more complex models. In this paper, we provide a new framework for deriving efficient CD algorithms for complex recommender models. We identify and introduce the property of k-separable models. We show that k-separability is a sufficient property to allow efficient optimization of implicit recommender problems with CD. We illustrate this framework on a variety of state-of-the-art models including factorization machines and Tucker decomposition. To summarize, our work provides the theory and building blocks to derive efficient implicit CD algorithms for complex recommender models.