 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022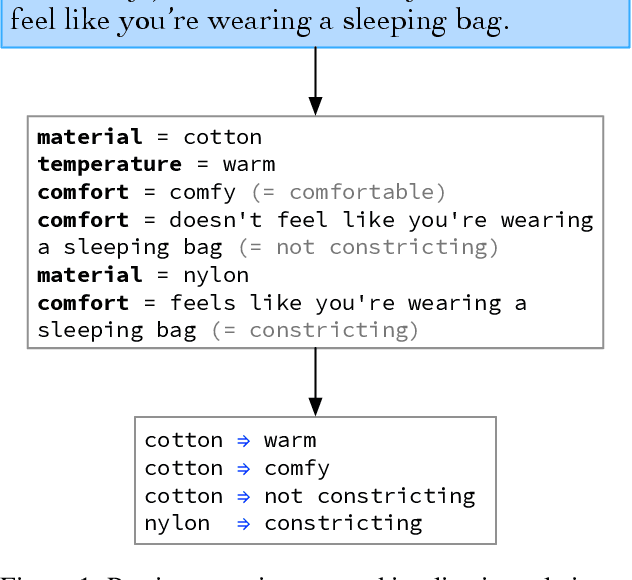

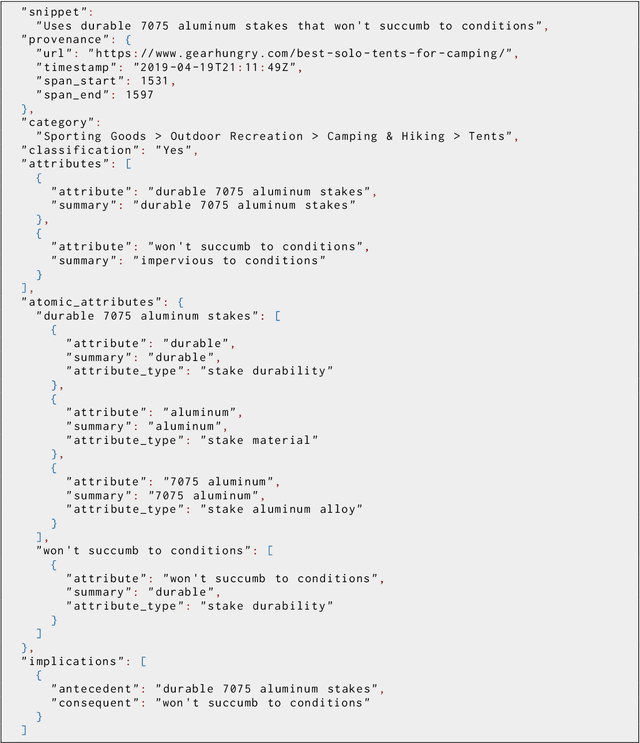
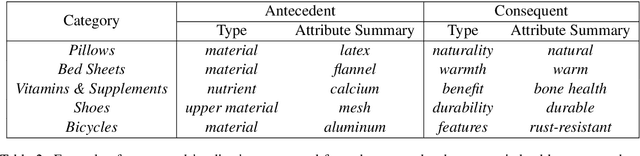
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.