 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality of Answers of Generative Large Language Models vs Peer Patients for Interpreting Lab Test Results for Lay Patients: Evaluation Study
Jan 23, 2024Lab results are often confusing and hard to understand. Large language models (LLMs) such as ChatGPT have opened a promising avenue for patients to get their questions answered. We aim to assess the feasibility of using LLMs to generate relevant, accurate, helpful, and unharmful responses to lab test-related questions asked by patients and to identify potential issues that can be mitigated with augmentation approaches. We first collected lab test results related question and answer data from Yahoo! Answers and selected 53 QA pairs for this study. Using the LangChain framework and ChatGPT web portal, we generated responses to the 53 questions from four LLMs including GPT-4, Meta LLaMA 2, MedAlpaca, and ORCA_mini. We first assessed the similarity of their answers using standard QA similarity-based evaluation metrics including ROUGE, BLEU, METEOR, BERTScore. We also utilized an LLM-based evaluator to judge whether a target model has higher quality in terms of relevance, correctness, helpfulness, and safety than the baseline model. Finally, we performed a manual evaluation with medical experts for all the responses to seven selected questions on the same four aspects. The results of Win Rate and medical expert evaluation both showed that GPT-4's responses achieved better scores than all the other LLM responses and human responses on all four aspects (relevance, correctness, helpfulness, and safety). However, LLM responses occasionally also suffer from a lack of interpretation in one's medical context, incorrect statements, and lack of references. We find that compared to other three LLMs and human answer from the Q&A website, GPT-4's responses are more accurate, helpful, relevant, and safer. However, there are cases which GPT-4 responses are inaccurate and not individualized. We identified a number of ways to improve the quality of LLM responses.
ImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022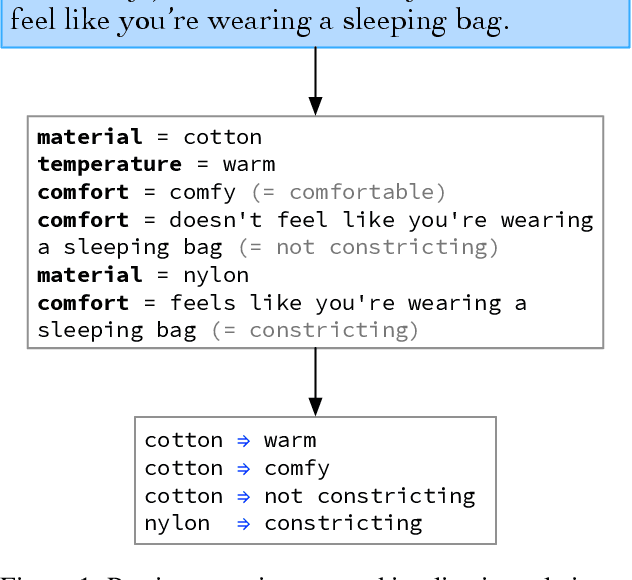

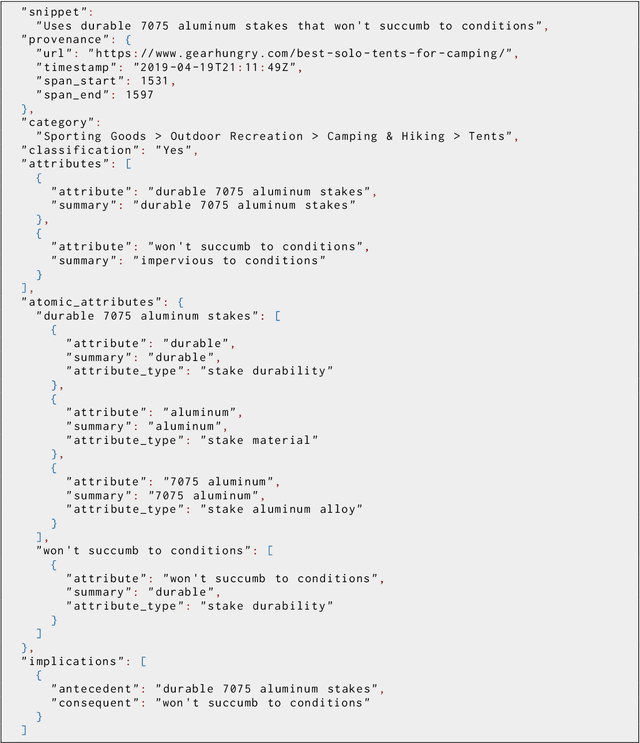
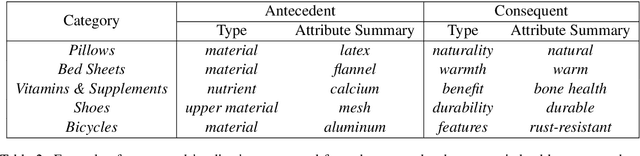
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.