 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
MEMORY-VQ: Compression for Tractable Internet-Scale Memory
Aug 28, 2023



Retrieval augmentation is a powerful but expensive method to make language models more knowledgeable about the world. Memory-based methods like LUMEN pre-compute token representations for retrieved passages to drastically speed up inference. However, memory also leads to much greater storage requirements from storing pre-computed representations. We propose MEMORY-VQ, a new method to reduce storage requirements of memory-augmented models without sacrificing performance. Our method uses a vector quantization variational autoencoder (VQ-VAE) to compress token representations. We apply MEMORY-VQ to the LUMEN model to obtain LUMEN-VQ, a memory model that achieves a 16x compression rate with comparable performance on the KILT benchmark. LUMEN-VQ enables practical retrieval augmentation even for extremely large retrieval corpora.
ImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022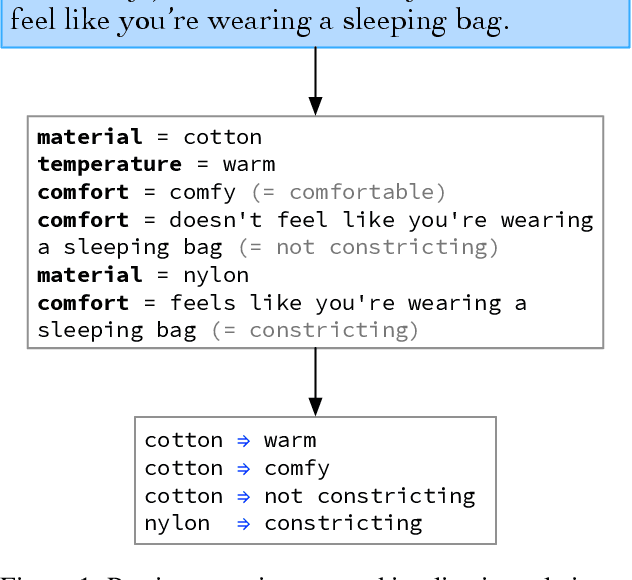

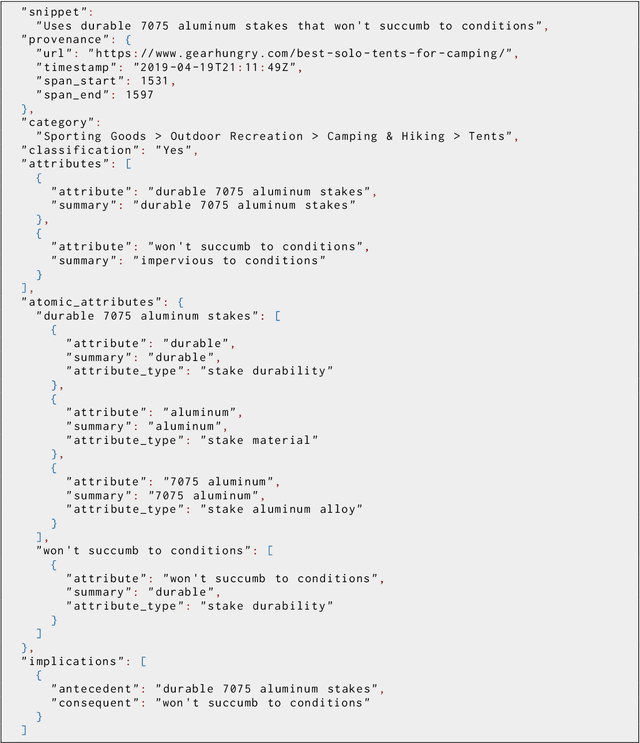
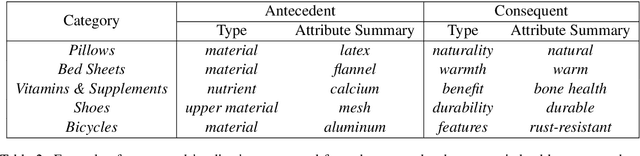
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.
Improving Local Identifiability in Probabilistic Box Embeddings
Oct 29, 2020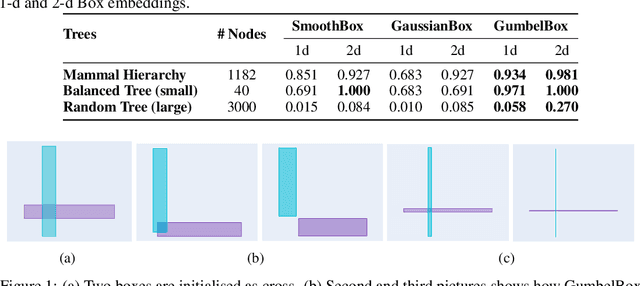
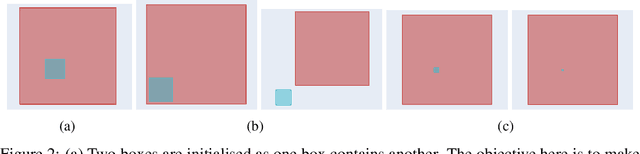
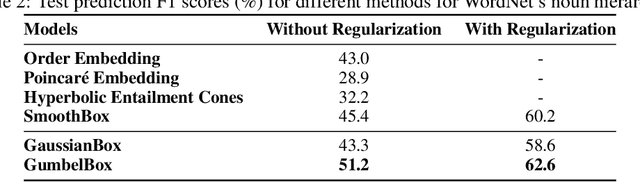
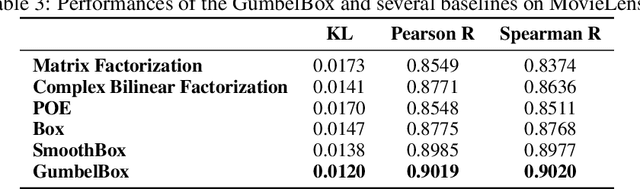
Geometric embeddings have recently received attention for their natural ability to represent transitive asymmetric relations via containment. Box embeddings, where objects are represented by n-dimensional hyperrectangles, are a particularly promising example of such an embedding as they are closed under intersection and their volume can be calculated easily, allowing them to naturally represent calibrated probability distributions. The benefits of geometric embeddings also introduce a problem of local identifiability, however, where whole neighborhoods of parameters result in equivalent loss which impedes learning. Prior work addressed some of these issues by using an approximation to Gaussian convolution over the box parameters, however, this intersection operation also increases the sparsity of the gradient. In this work, we model the box parameters with min and max Gumbel distributions, which were chosen such that space is still closed under the operation of the intersection. The calculation of the expected intersection volume involves all parameters, and we demonstrate experimentally that this drastically improves the ability of such models to learn.
Embedded-State Latent Conditional Random Fields for Sequence Labeling
Sep 28, 2018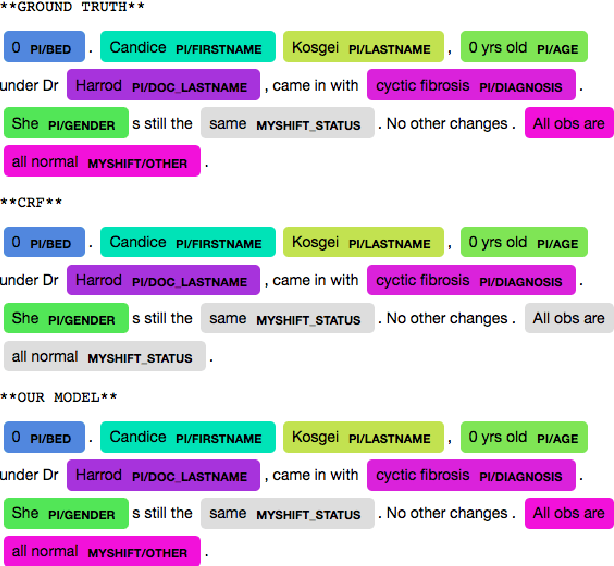
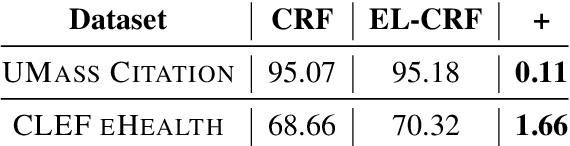
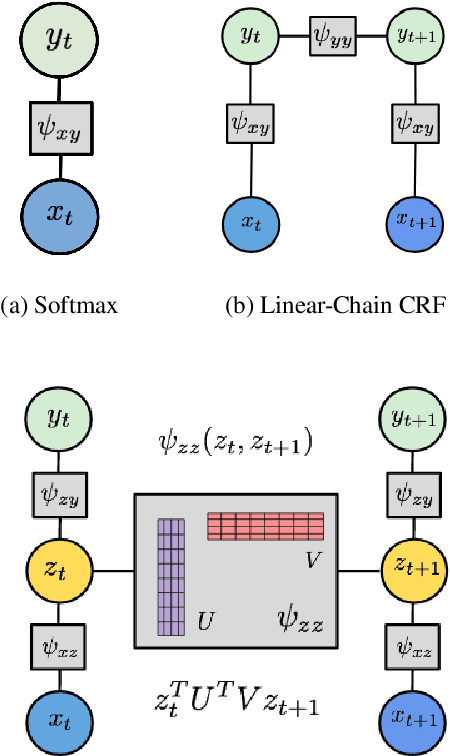
Complex textual information extraction tasks are often posed as sequence labeling or \emph{shallow parsing}, where fields are extracted using local labels made consistent through probabilistic inference in a graphical model with constrained transitions. Recently, it has become common to locally parametrize these models using rich features extracted by recurrent neural networks (such as LSTM), while enforcing consistent outputs through a simple linear-chain model, representing Markovian dependencies between successive labels. However, the simple graphical model structure belies the often complex non-local constraints between output labels. For example, many fields, such as a first name, can only occur a fixed number of times, or in the presence of other fields. While RNNs have provided increasingly powerful context-aware local features for sequence tagging, they have yet to be integrated with a global graphical model of similar expressivity in the output distribution. Our model goes beyond the linear chain CRF to incorporate multiple hidden states per output label, but parametrizes their transitions parsimoniously with low-rank log-potential scoring matrices, effectively learning an embedding space for hidden states. This augmented latent space of inference variables complements the rich feature representation of the RNN, and allows exact global inference obeying complex, learned non-local output constraints. We experiment with several datasets and show that the model outperforms baseline CRF+RNN models when global output constraints are necessary at inference-time, and explore the interpretable latent structure.
Hierarchical Losses and New Resources for Fine-grained Entity Typing and Linking
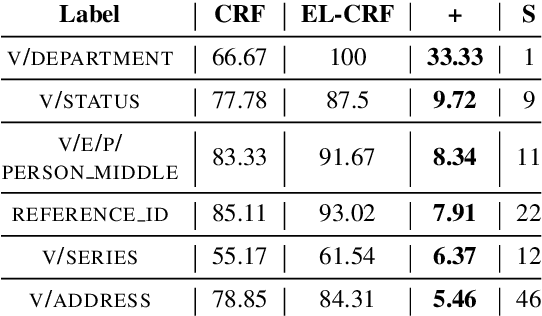
Jul 13, 2018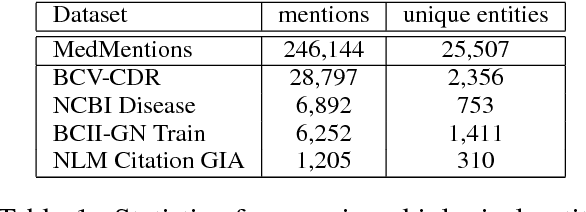
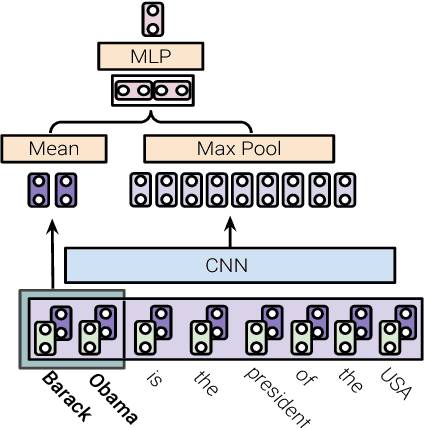
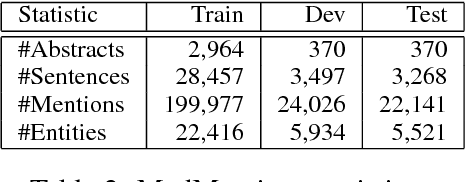
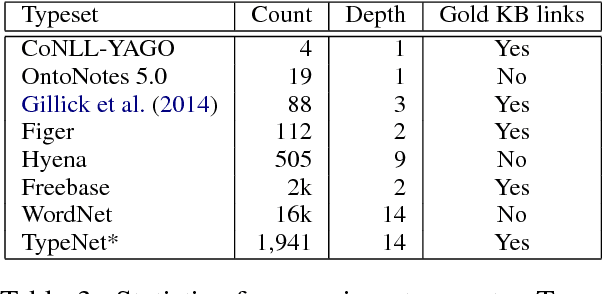
Extraction from raw text to a knowledge base of entities and fine-grained types is often cast as prediction into a flat set of entity and type labels, neglecting the rich hierarchies over types and entities contained in curated ontologies. Previous attempts to incorporate hierarchical structure have yielded little benefit and are restricted to shallow ontologies. This paper presents new methods using real and complex bilinear mappings for integrating hierarchical information, yielding substantial improvement over flat predictions in entity linking and fine-grained entity typing, and achieving new state-of-the-art results for end-to-end models on the benchmark FIGER dataset. We also present two new human-annotated datasets containing wide and deep hierarchies which we will release to the community to encourage further research in this direction: MedMentions, a collection of PubMed abstracts in which 246k mentions have been mapped to the massive UMLS ontology; and TypeNet, which aligns Freebase types with the WordNet hierarchy to obtain nearly 2k entity types. In experiments on all three datasets we show substantial gains from hierarchy-aware training.
Distributional Inclusion Vector Embedding for Unsupervised Hypernymy Detection
May 29, 2018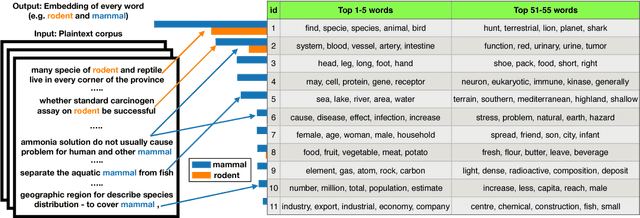
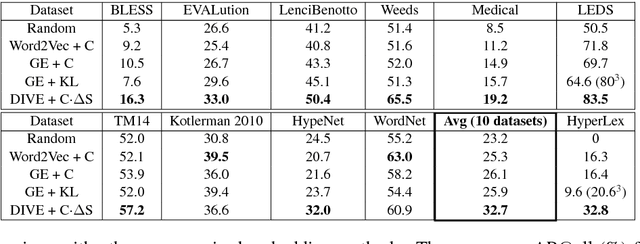
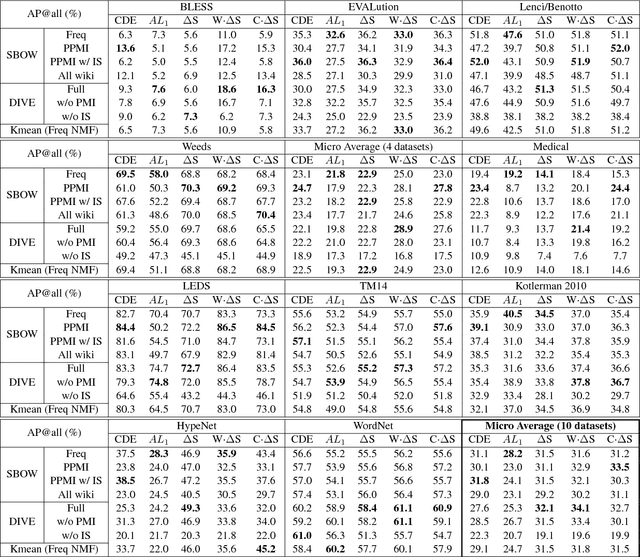
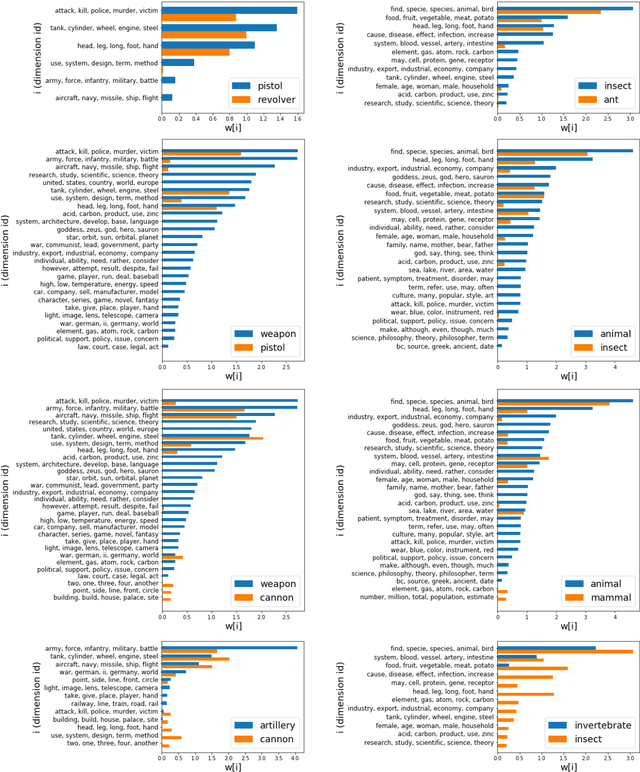
Modeling hypernymy, such as poodle is-a dog, is an important generalization aid to many NLP tasks, such as entailment, coreference, relation extraction, and question answering. Supervised learning from labeled hypernym sources, such as WordNet, limits the coverage of these models, which can be addressed by learning hypernyms from unlabeled text. Existing unsupervised methods either do not scale to large vocabularies or yield unacceptably poor accuracy. This paper introduces distributional inclusion vector embedding (DIVE), a simple-to-implement unsupervised method of hypernym discovery via per-word non-negative vector embeddings which preserve the inclusion property of word contexts in a low-dimensional and interpretable space. In experimental evaluations more comprehensive than any previous literature of which we are aware-evaluating on 11 datasets using multiple existing as well as newly proposed scoring functions-we find that our method provides up to double the precision of previous unsupervised embeddings, and the highest average performance, using a much more compact word representation, and yielding many new state-of-the-art results.
Probabilistic Embedding of Knowledge Graphs with Box Lattice Measures
May 17, 2018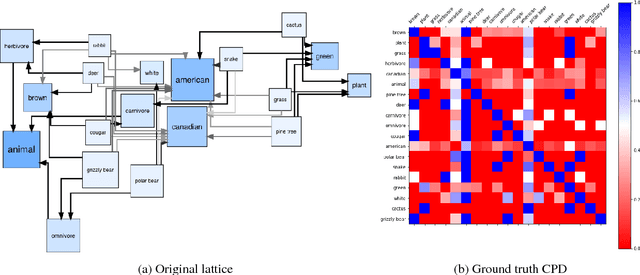

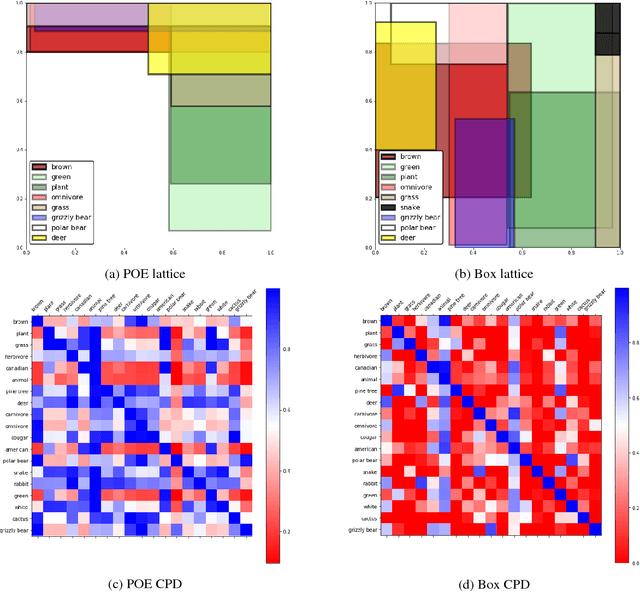
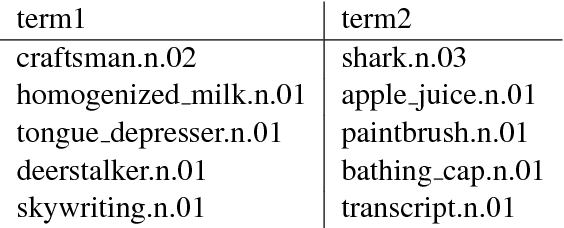
Embedding methods which enforce a partial order or lattice structure over the concept space, such as Order Embeddings (OE) (Vendrov et al., 2016), are a natural way to model transitive relational data (e.g. entailment graphs). However, OE learns a deterministic knowledge base, limiting expressiveness of queries and the ability to use uncertainty for both prediction and learning (e.g. learning from expectations). Probabilistic extensions of OE (Lai and Hockenmaier, 2017) have provided the ability to somewhat calibrate these denotational probabilities while retaining the consistency and inductive bias of ordered models, but lack the ability to model the negative correlations found in real-world knowledge. In this work we show that a broad class of models that assign probability measures to OE can never capture negative correlation, which motivates our construction of a novel box lattice and accompanying probability measure to capture anticorrelation and even disjoint concepts, while still providing the benefits of probabilistic modeling, such as the ability to perform rich joint and conditional queries over arbitrary sets of concepts, and both learning from and predicting calibrated uncertainty. We show improvements over previous approaches in modeling the Flickr and WordNet entailment graphs, and investigate the power of the model.
Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning
Nov 15, 2017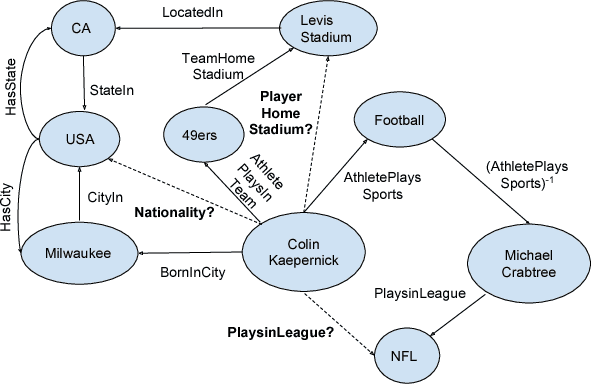
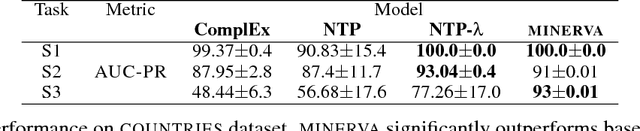
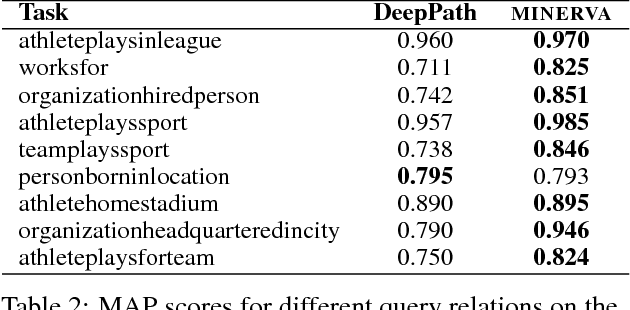
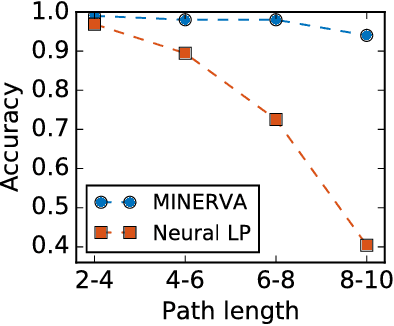
Knowledge bases (KB), both automatically and manually constructed, are often incomplete --- many valid facts can be inferred from the KB by synthesizing existing information. A popular approach to KB completion is to infer new relations by combinatory reasoning over the information found along other paths connecting a pair of entities. Given the enormous size of KBs and the exponential number of paths, previous path-based models have considered only the problem of predicting a missing relation given two entities or evaluating the truth of a proposed triple. Additionally, these methods have traditionally used random paths between fixed entity pairs or more recently learned to pick paths between them. We propose a new algorithm MINERVA, which addresses the much more difficult and practical task of answering questions where the relation is known, but only one entity. Since random walks are impractical in a setting with combinatorially many destinations from a start node, we present a neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths. Empirically, this approach obtains state-of-the-art results on several datasets, significantly outperforming prior methods.
Finer Grained Entity Typing with TypeNet
Nov 15, 2017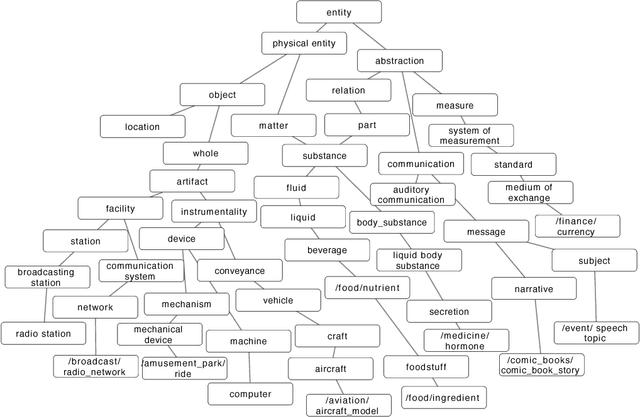
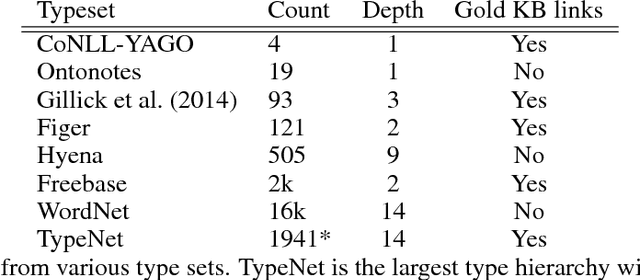
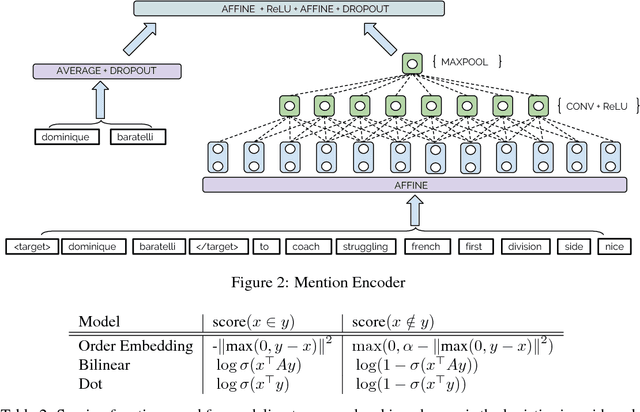
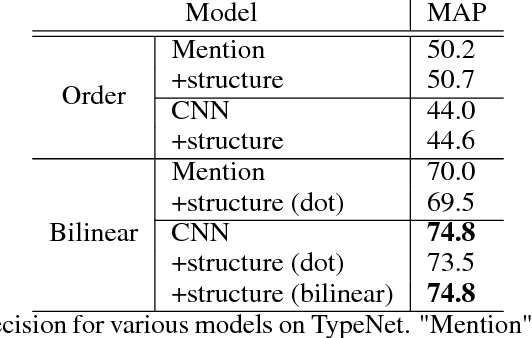
We consider the challenging problem of entity typing over an extremely fine grained set of types, wherein a single mention or entity can have many simultaneous and often hierarchically-structured types. Despite the importance of the problem, there is a relative lack of resources in the form of fine-grained, deep type hierarchies aligned to existing knowledge bases. In response, we introduce TypeNet, a dataset of entity types consisting of over 1941 types organized in a hierarchy, obtained by manually annotating a mapping from 1081 Freebase types to WordNet. We also experiment with several models comparable to state-of-the-art systems and explore techniques to incorporate a structure loss on the hierarchy with the standard mention typing loss, as a first step towards future research on this dataset.